
Меня зовут Юля, я разработчик команды ETNA. Расскажу о том, как мы запустили открытый инструмент для аналитики и прогнозирования бизнес-процессов, как он устроен и как его использовать.
В Тинькофф мы часто решаем задачи по прогнозированию: хотим знать количество звонков на линии обслуживания или сколько наличных клиенты снимут в банкомате на следующей неделе. Специалисты по обработке данных и аналитики, которые сталкиваются с проблемами прогнозирования, могут использовать целый ряд различных инструментов для своей работы. Это неудобно и требует времени. Чтобы упростить задачу, мы разработали наш фреймворк.
Как мы создавали библиотеку
Суть нашей работы — предсказывать будущие события, используя исторические данные. Например, в задаче с банкоматами выше мы берем исторические данные оборота каждого банкомата и смотрим, какой оборот будет в будущем. На основе этих прогнозов анализируются возможные варианты инкассации и выбирается оптимальная дата. Данные, которые мы прогнозируем, называются временными рядами.
Временной ряд — это любой поток данных с привязкой ко времени. Например, количество проданных кружек кофе в торговом центре за каждый день — это временной ряд. Прогнозировать его необходимо для оптимизации процессов и эффективного распределения ресурсов. Как уже говорили, мы начинали с прогнозирования оборота наличности в банкоматах, потом предсказывали количество встреч представителей и обращений в кол-центр.
Этими процессами занимались разные команды с использованием целого перечня инструментов. Инструменты были хорошими и помогали в решении задач, но каждое направление создавало свои доработки, которые невозможно было воспроизвести. И отсутствовал единый центр экспертизы, поэтому возникали проблемы с обменом опытом.
Мы провели исследование, чтобы понять, каким должно быть решение, подходящее всем. Поговорили с аналитиками, выяснили, как выглядят их рабочие задачи на прогнозирование и какие этапы работы с данными вызывают наибольшее затруднение.
Выяснилось, что проблемы начинаются еще до обучения моделей. Реальные данные не всегда можно использовать для обучения в чистом виде: в них есть пропуски, потерянные даты, аномалии и прочие неприятности. Для многих процессов необходимо предсказывать не один и не пять, а тысячи рядов. Попытка обработать данные вручную выливается в сотни строк кода, циклов и сложных для понимания конструкций.
И когда, казалось бы, все сложности позади, возник еще ряд вопросов: как правильно измерить качество модели? как построить процесс валидации? как быстро и безболезненно сравнить несколько моделей? как использовать дополнительные данные? как сгенерировать признаки для обучения модели?
Для того чтобы найти ответы на эти вопросы, мы и создали библиотеку ETNA.
Как устроена ETNA
Как же выглядит процесс прогнозирования и проведения экспериментов с помощью ETNA? Сейчас прогнозирование можно разделить на несколько важных шагов.
Подготовка и валидация данных. Для работы с данными в библиотеке ETNA существует класс TSDataset. Он позволяет привести все ряды к единому формату, восстановить потерянные частотности, а также реализует связь данных для прогнозирования с дополнительными данными.
import pandas as pd
from etna.datasets import TSDataset
df_flat = pd.read_csv("data/example_dataset.csv")
# приводим данные к ETNA-формату
df = TSDataset.to_dataset(df_flat)
ts = TSDataset(df=df, freq="D")
TSDataset гарантирует корректную работу с данными в настоящем и будущем.
Предварительный анализ данных (EDA). Для того чтобы пользователи поняли структуру и особенности прогнозируемых рядов, мы добавили методы EDA. Они позволяют построить статистики по данным, оценить автокорреляцию, обнаружить выбросы.
ts.describe()
from etna.analysis import sample_acf_plot
sample_acf_plot(ts=ts)
from etna.analysis import get_anomalies_density, plot_anomalies
anomalies = get_anomalies_density(
ts=ts,
window_size=45,
n_neighbors=25,
distance_coef=1.9
)
plot_anomalies(ts=ts, anomaly_dict=anomalies)
Построение пайплайна прогнозирования. По результатам EDA можно понять, какие признаки выделять из данных, как нужно обработать ряды для дальнейшей работы. Например, вычесть тренд или прологарифмировать.
from etna.transforms import (
LinearTrendTransform,
DensityOutliersTransform,
TimeSeriesImputerTransform,
)
transforms = [
# удаляем выбросы из данных
DensityOutliersTransform(
in_column="target",
window_size=45,
n_neighbors=25,
distance_coef=1.9
),
# заполняем образовавшиеся пропуски
TimeSeriesImputerTransform(
in_column="target",
strategy="running_mean"
),
# вычитаем тренд
LinearTrendTransform(in_column="target"),
]Все модели в ETNA имеют единый интерфейс, поэтому, независимо от предыдущих шагов, можно использовать любую из представленных моделей.
from etna.models import SeasonalMovingAverageModel
from etna.pipeline import Pipeline
model = SeasonalMovingAverageModel(seasonality=7, window=5)
pipeline = Pipeline(
model=model,
transforms=transforms,
horizon=14
)Построение прогноза и валидация. Чтобы проверить, насколько хорошо представленный пайплайн будет работать для данных рядов, можно запустить тестирование на исторических данных.
from etna.metrics import MAE, SMAPE, MSE, MAPE
from etna.analysis import plot_backtest
METRICS = [MAE(), MSE(), MAPE(), SMAPE()]
metrics, forecasts, info = pipeline.backtest(
ts=ts,
metrics=METRICS,
n_folds=5,
)
plot_backtest(forecast_df=forecasts, ts=ts, history_len=50)
# в metrics содержатся метрики прогнозирования для каждого
# фолда валидации для каждого сегмента
metrics.head(7)
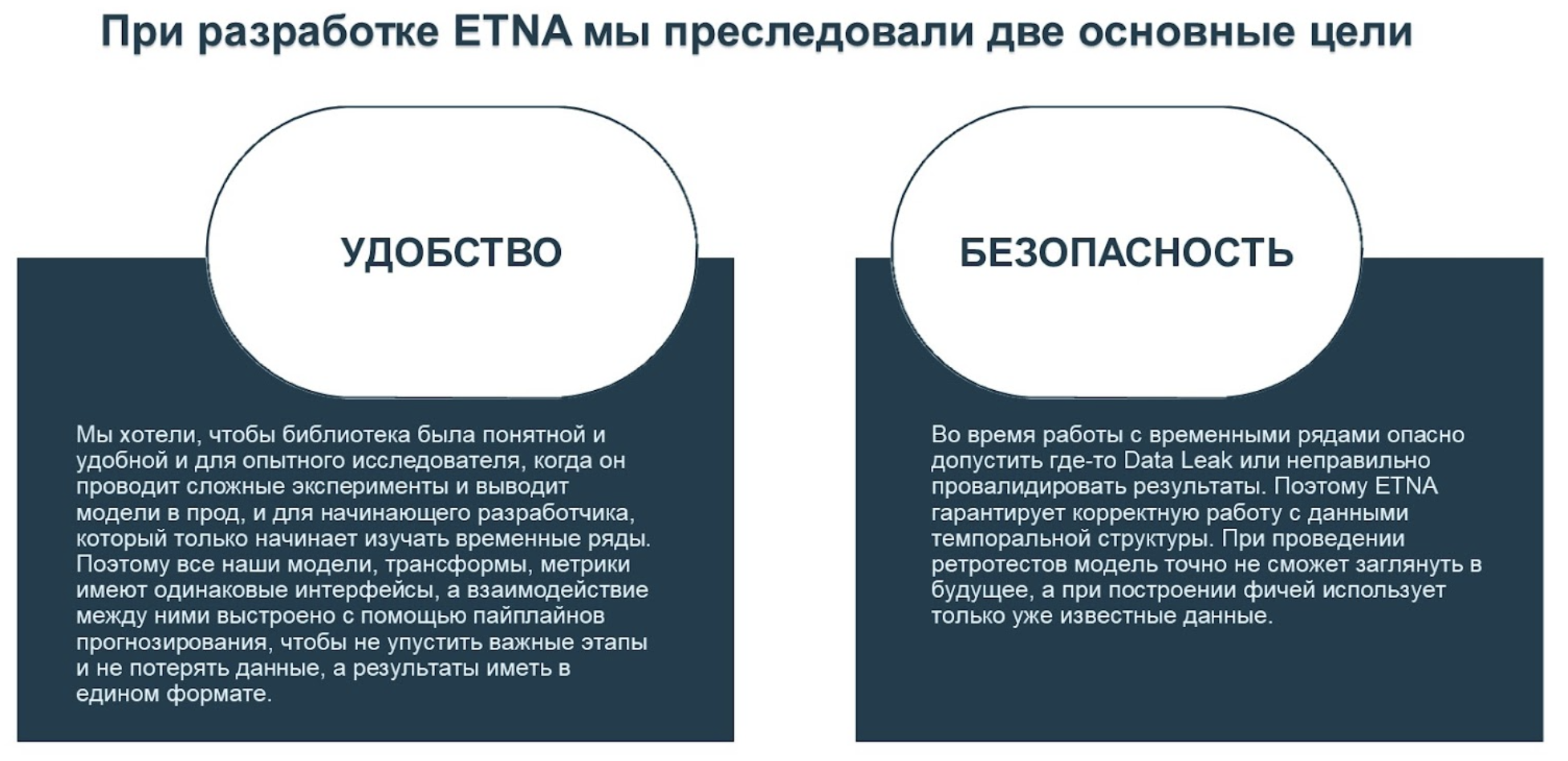
Мы позаботились о том, чтобы пользователь мог не беспокоиться о технической стороне эксперимента и сконцентрировался на работе со своей задачей, поэтому реализовали в ETNA несколько вспомогательных инструментов:
Множество логгеров для интеграции с W&B, сохранения промежуточных результатов в s3 или локальный файл, вывода лога в консоль.
Удобный CLI, который позволяет конфигурировать и запускать эксперименты без написания кода, через yaml-конфиг.
Инструменты аналитики результатов: метрики регрессии и методы визуализации прогнозов и их доверительных интервалов.
Как мы вышли в опенсорс и как планируем развиваться дальше
Мы создавали библиотеку для внутренних нужд. Хотели удобной и гибкой работы с кодом и экспериментами, а экспериментов проводили много и решили их структурировать и оптимизировать.
В итоге получили инструмент, который делает процесс решения наших задач простым, понятным и удобным, поэтому захотели поделиться им с коммьюнити.
Наша команда видит в этом много плюсов:
Практичность для экспериментов: логирование, конфигурации, встроенная предобработка данных и выделение признаков.
Возможность пользователям давать нам обратную связь или рассказывать о своих потребностях.
Единый интерфейс для всех моделей, что делает фреймворк удобным.
Возможность делать ETNA удобнее и универсальнее, когда решаем пользовательские запросы, тем самым улучшаем свой опыт и развиваем библиотеку.
Рост экспертизы. Чем шире аудитория, с которой мы взаимодействуем, тем больше развивается фреймворк и коммьюнити. Мы можем делиться историями, лайфхаками и обмениваться экспертизой друг с другом.
О пользе опенсорса для компании уже писал наш коллега Роман Седов:
В ближайшее время мы собираемся сделать упор на внутреннюю реализацию библиотеки. Первые пункты в нашем todo по библиотеке ETNA — это ускорение пайплайнов прогнозирования и оптимизация работы с большими данными. Но не останутся без внимания и новые методы аналитики и генерации признаков. Кроме того, мы планируем подготовить большое количество статей и примеров, показывающих, как можно прогнозировать ряды и какие фичи могут в этом помочь.
