
Одно из самых больших изменений в C# 8 — это nullable reference types. Ранее Андрей Дятлов (JetBrains) рассказал на конференции DotNext о трудностях и проблемах, которые вы можете встретить при работе с ними. Доклад понравился зрителям, поэтому теперь для Хабра готова его текстовая версия.

Наиболее полезным пост будет для тех, кто планирует использовать nullable reference types в больших проектах, которые невозможно перевести на использование NRT и проаннотировать целиком за короткое время; проектах, в которых используются собственные решения для ассертов или исключений, либо методы со сложными контрактами, связывающими наличие null во входных и выходных значениях, так как эти методы придется аннотировать для корректной работы компилятора с ними.
Я оставляю ссылку на оригинальный доклад. Дальше повествование пойдет от лица Андрея Дятлова, а пока что последний момент от меня: мы уже вовсю готовим осенний DotNext, и до 16 августа включительно принимаем заявки на доклады, так что если вам тоже есть о чем поведать дотнетчикам, откликайтесь.
Я занимаюсь поддержкой C# c 2015 года. В основном пишу анализаторы кода, занимаюсь рефакторингом и поддержкой новых версий языка. А по совместительству нахожу еще и баги в Roslyn.
План доклада
- Краткое описание nullable reference types
- Способы постепенного перевода проекта на их использование
- Взаимодействие с обобщенным кодом
- Аннотации для помощи компилятору
- Что делать, если компилятор не прав?
- Подводные камни
- Warnings as errors
Что такое nullable reference types?

До C# 8 вы могли объявить вот такой класс сотрудника, дать ему поля: имя, фамилия, день рождения и при помощи структуры Nullable<T> с помощью вопроса на конце указать, что день рождения у сотрудника может быть не заполнен. И при попытке обращаться к этому свойству вам приходилось проверять, есть ли там действительно значение, при помощи свойства HasValue. Явно оттуда его доставать при помощи Value, либо делать это при помощи Conditional Access(?.).
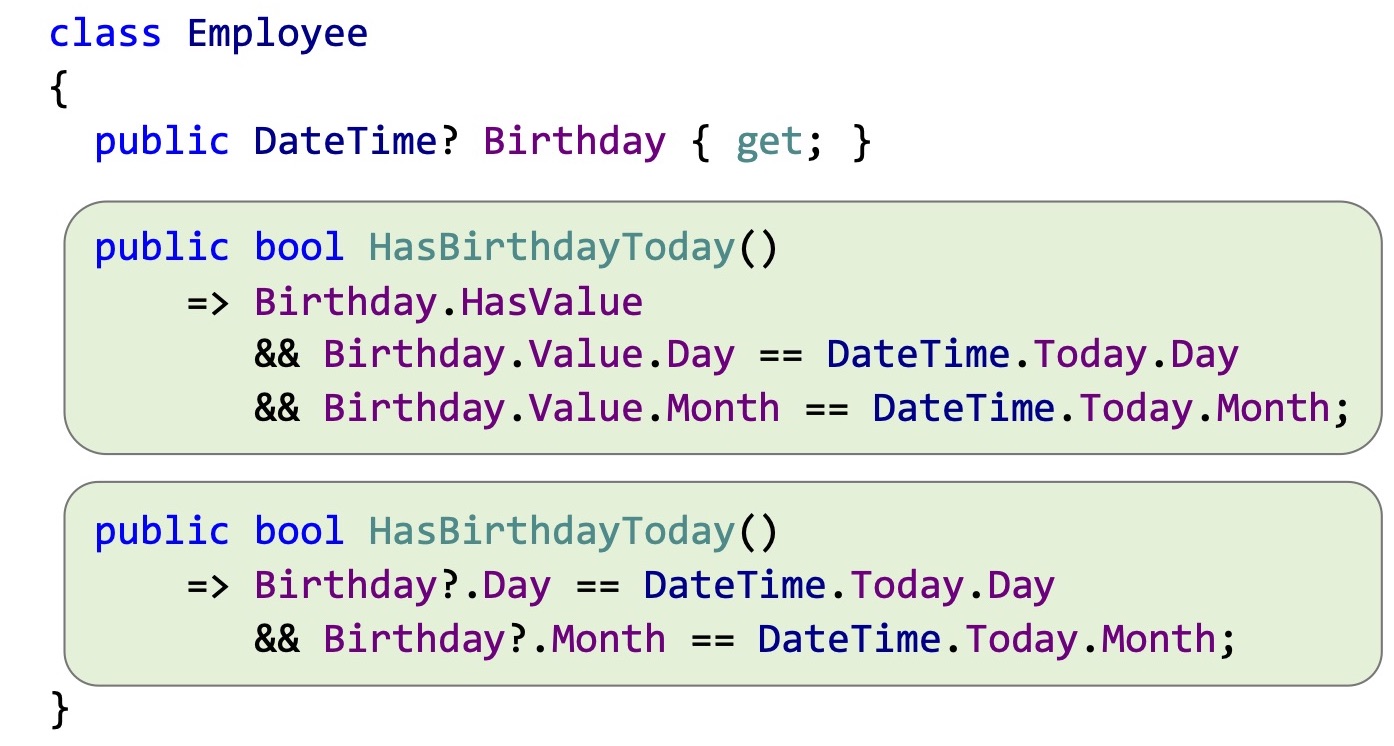
Но с reference-типами у вас не было такой подсказки, и если вам приходилось модифицировать этот класс, например, добавить в него метод получения инициалов сотрудника (по первым буквам имени и фамилии), то у вас возникали вопросы. А может ли фамилия сотрудника быть незаполненной?
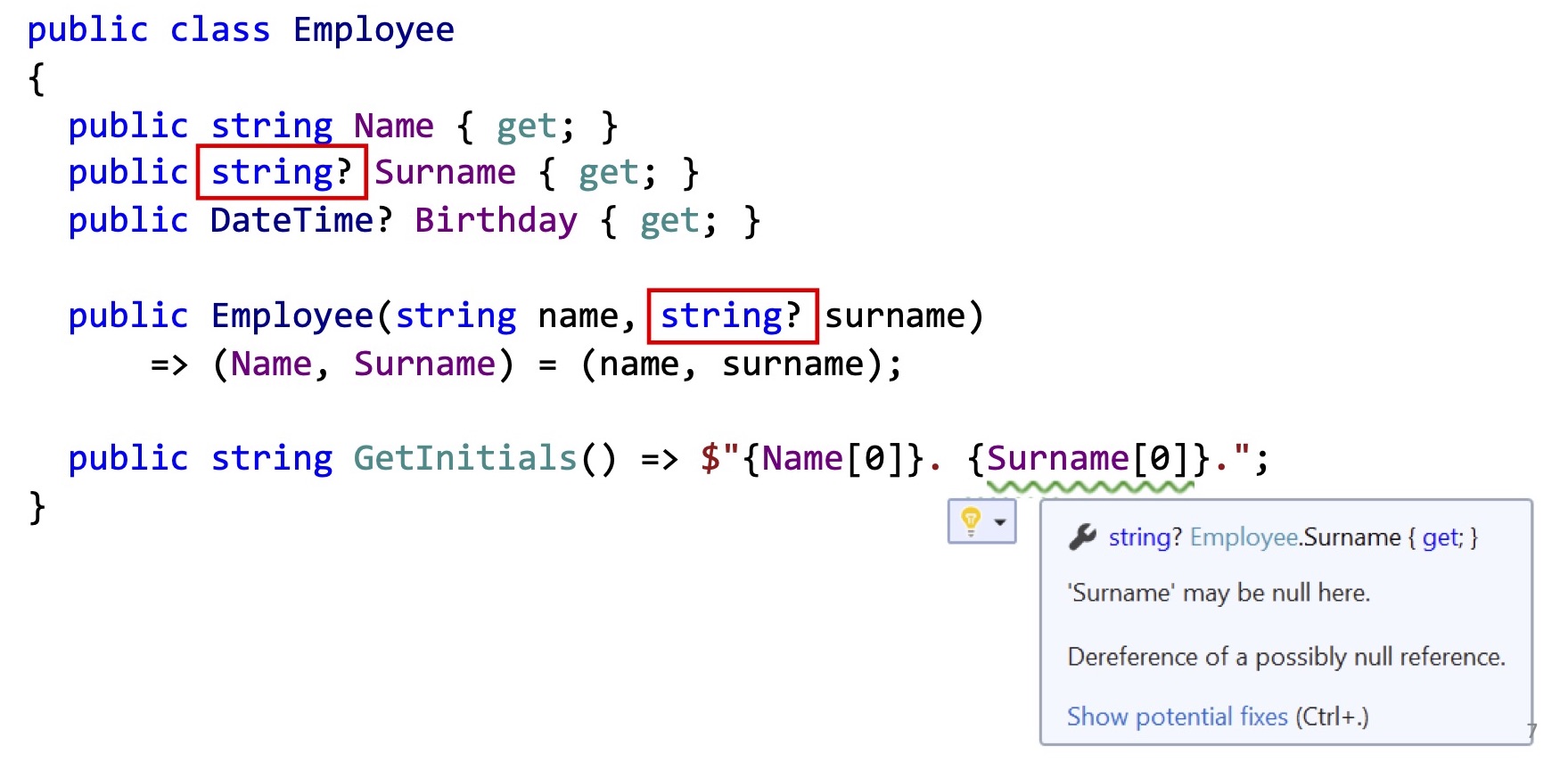
Теперь, начиная с C# 8, вы можете использовать тот же самый синтаксис для reference-типов, добавить вопрос в конец для поля Surname, и сказать, что имя у сотрудника есть всегда, а фамилию он может не заполнять. Компилятор теперь сразу подскажет вам, что когда вы обращаетесь к первой букве фамилии, фамилии может не быть, и в этом случае может произойти исключение. Причем если мы посмотрим на то, как этот метод скомпилирован, то обнаружим, что идет запрос к свойству Surname, и после этого сразу идет обращение к первому символу, то есть никаких рантайм-проверок на самом деле не добавилось. Если там Null, то вы все еще получите NullReferenceException. Теперь видите это предупреждение и понимаете, что фамилия может null. Можете его исправить при помощи все того же Conditional Access(.?) для доступа к первому элементу.
Отличие от Nullable<T>

А чем это отличается от Nullable<T> для структур? Nullable<T> — специальный тип, компилятор о нем знает, и если вы измените возвращаемый тип метода на Nullable<T>, то у вас изменится сигнатура метода.
А nullable reference types — это просто аннотация в системе типов. И если вы ее меняете, никаких разрушительных последствий обычно не происходит. Кроме того, с Nullable<T> вам приходится явно получать значение, которое там лежит, при помощи обращения к свойству Value, а с nullable reference types все работает как раньше, то есть никаких церемоний с тем, чтобы получить значение, нет. Но и компилятор в рантайме ничего проверять за вас не будет, он просто выдаст вам предупреждение, когда вы будете компилировать проект. И если что-то пошло не так, то всё будет работать по-старому с NullReferenceException.
Интересное сравнение реализаций null safety в C# и Kotlin в докладе Kotlin и С#. Чему языки могут поучиться друг у друга?(по ссылке тайм-код) Дмитрия Иванова.
Преимущества аннотаций

Скорее всего, кто-нибудь уже использует аннотации для решения проблем с null reference. Вы можете проаннотировать поля и коллекции при помощи атрибутов. А в чем тогда преимущество новой фичи языка?
Дело в том, что новая фича языка — это аннотация, которую можно использовать везде, где вы используете тип, но там, где нельзя было использовать атрибуты. Либо для таких сценариев, где атрибуты не предусмотрены. Например, если у вас есть вложенная коллекция, вы не могли ее проаннотировать атрибутами. Если у вас есть какой-то дженерик-тип, и один из типов аргументов должен быть nullable, вы тоже не могли это выразить атрибутами.
Кроме того, вы не могли использовать атрибут там, где используются локальные переменные, где вы реализуете интерфейс или наследуетесь c какого-то класса, с ограничениями какого-то типа параметров. То есть во многих местах языка атрибуты в принципе запрещено писать, поэтому это нельзя было сделать. А новый синтаксис можно использовать везде, где вы можете в принципе написать тип. Это вcё, что я хотел сказать про саму фичу языка.
Это очень кратко, но команда компилятора, по их собственным оценкам, потратила на реализацию примерно 15 человеко-лет и, конечно, они подумали о том, с какими сложностями вы можете столкнуться и как это добавить в существующие проекты, в которых уже есть достаточно много кода, и он написан по-старому.
Включаем и пользуемся!
Для начала рассмотрим проблемы, с которыми вы можете столкнуться, если просто включите эту фичу для своего проекта.

У вас есть функция, она принимает какой-то ввод. Если этот ввод оказался null, спрашивает у пользователя ввод, если это разрешено, (bool allowUserInput) проверяет, что там парсится число в этой строке и после этого возвращает либо строку с числом, либо null. Если мы сейчас в этом проекте включаем nullable reference types, то у нас на каждой строке этого проекта появится предупреждение.
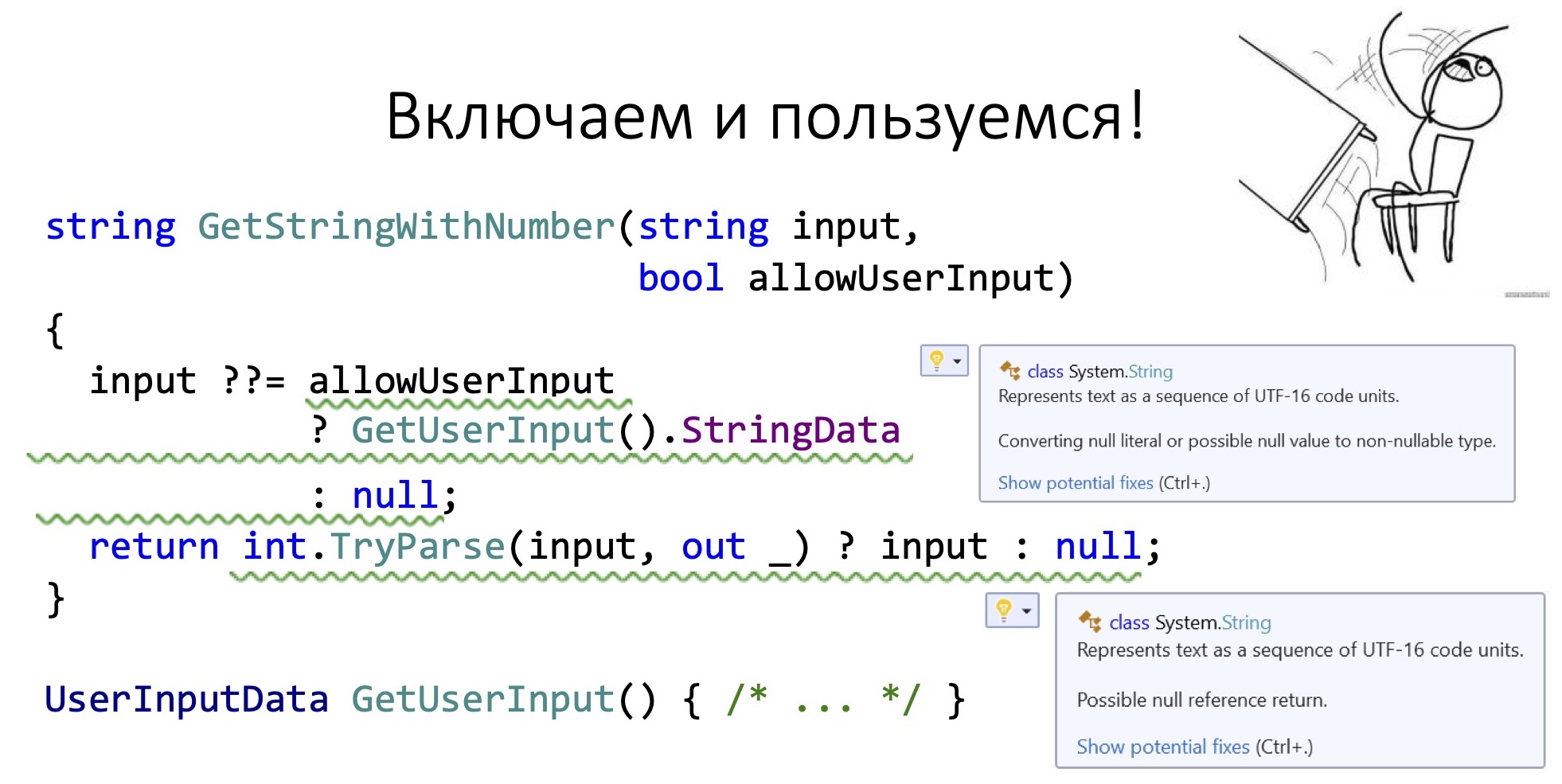
Почему это происходит? Дело в том, что старый синтаксис, когда вы не указали вопрос после типа, теперь означает, что в этом типе никогда не бывает null, и компилятор не только не предупреждает вас, если вы пытаетесь прочитать оттуда значения, но и запрещает вам положить null в такую переменную при помощи предупреждения.
Починить мы это можем так: указываем, что в переменной input может лежать null, и вернуться из этого метода тоже может null. Нужно всего лишь объявить входную и выходную строку как nullable. Это достаточно просто, но трудоемко на больших проектах.
Предупреждения компилятора без лишних усилий
Наверное, многие знают библиотеку NewtonsoftJson. Ее перевели на nullable reference types, и для этого пришлось изменить 170 файлов и 4000 строк кода. Если ваш проект немного больше, то скорее всего вам будет еще тяжелее.
Что можно сделать, если вы не хотите сейчас переписывать весь свой проект и тратить на это несколько месяцев или лет? Команда компилятора предусмотрела следующие опции: если вы хотите включить анализ только для части проекта, а для какой-то — нет, если вы хотите, чтобы вот прямо сейчас компилятор вам помог с проблемами в вашем коде, но вы пока вообще ничего не готовы для этого делать, ни одной аннотации проставлять.

Если вы пишете библиотеку, то можете захотеть проаннотировать ее только для пользователей, но пока не пользоваться этой фичей. Это тоже можно. Сейчас я расскажу подробнее о том, как всё это работает.
Во-первых, если у вас есть банковский софт, вы создаете транзакции, у вас есть клиент, информацию о котором нужно заполнить, вы проверяете, в какой стране живет клиент, требуется ли информация о почтовом индексе.
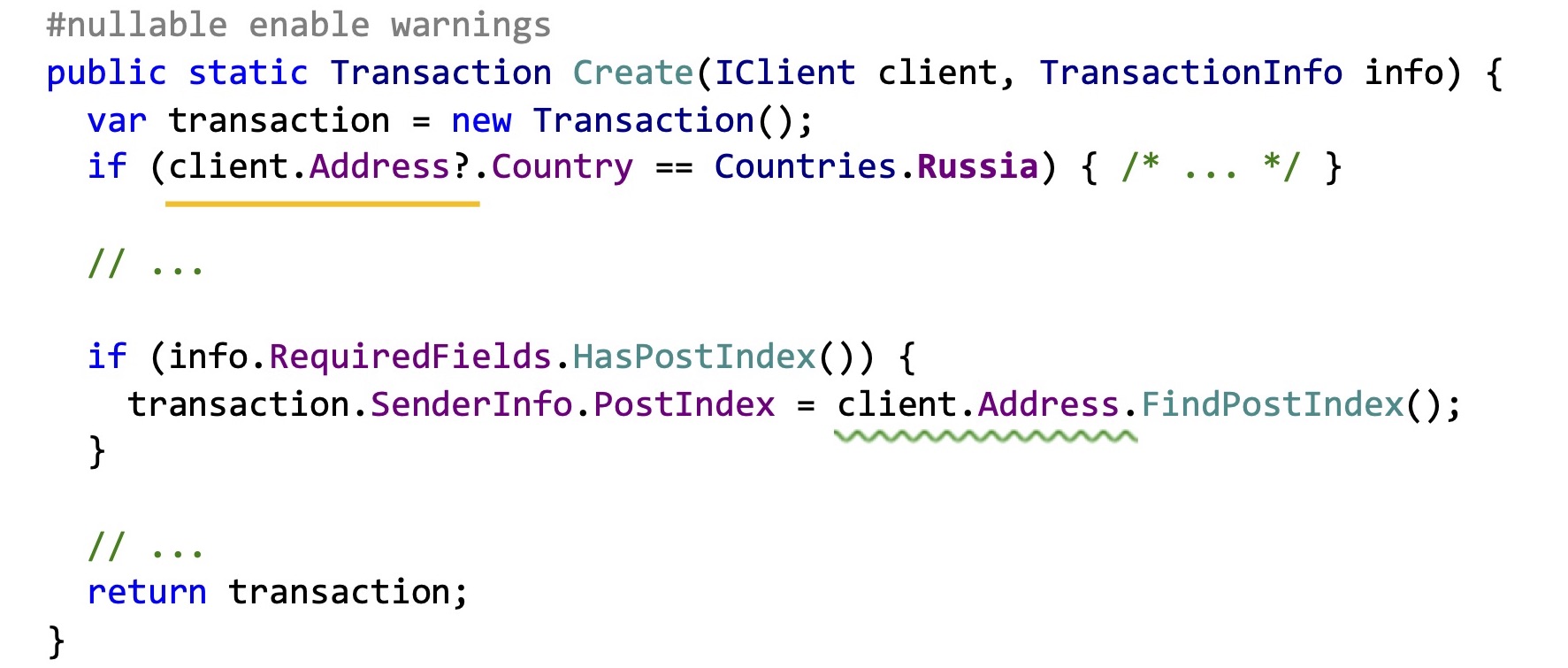
Если вы прямо сейчас, ничего не аннотируя, просто включите здесь предупреждения при помощи препроцессора #nullable enable warnings, компилятор подскажет вам, что во втором if адрес может быть null. Вы можете наткнуться на NullReferenceException.
Почему он это знает? Дело в том, что в предыдущем if, когда вы проверяли строку, где живет клиент, вы при помощи вопроса с точкой сказали компилятору: вы как программист считаете, что здесь может встретиться null. Компилятор это запомнил, поэтому когда вы потом в следующем If обратились без этой проверки, компилятор говорит, что нет, мы же знаем, что здесь может быть null, вы уже проверяли. И предупреждает вас об этом. Может быть, это действительно ошибка в проекте, у вас просто никогда не было такой комбинации информации о клиенте и обязательных полей.

Компилятор может узнать о том, что вы хотите видеть здесь предупреждение, либо если вы явно присвоили туда null, либо если вы явно предположили, что там бывает null при помощи проверки в If или conditional access. Несмотря на то, что мы пока включили только предупреждение, вы уже можете аннотировать свой проект и сказать, что конкретно эта переменная бывает null. Чем это тогда отличается от того, что мы включим вообще всю фичу, если мы уже можем аннотировать и получать предупреждение?

Отличие в том, что по умолчанию, если вы включили nullable reference types, то типы, которые были написаны по старому, без вопросов на конце, стали not-nullable types. Это такие типы, в которые нельзя присвоить null, и компилятор вас об этом предупреждает. Именно из-за этого у нас в предыдущем примере с функцией на несколько строк были предупреждения.
Если вы включили только предупреждения, но не всю фичу, то такие типы станут oblivious types. Это понятия для типов, когда компилятор не знает, что там лежит, и поэтому по умолчанию считает, что пользователь может пользоваться этой переменной как угодно. Может даже присвоить в нее null, предупреждений не будет. Таким образом, вы получите минимальное количество предупреждений, которые скорее всего сигнализируют об ошибках в коде. Потому что они получены из предыдущих проверок в этом же коде.
Продолжаем аннотировать
Допустим, у вас есть в компании еще один отдел, который пользуется теми же интерфейсами, которые вы пишете. И у вас есть информация о клиенте, которой мы только что пользовались.

У клиента есть имя, фамилия, отчество, адрес, о котором мы уже знаем по проверкам в коде, что он бывает null. Паспорт, телефон и имейл, можно отправить нотификацию о том, что какая-нибудь его транзакция не прошла, потому что он указал неправильные данные.
И скорее всего, этот отдел периодически будет ходить к вам с вопросами о том, можно ли здесь передать null, можно ли, например, отправить этому клиенту нотификацию без указания транзакции, просто отправить сообщение с рекламой? Будет ли оно вообще в этом случае создано, и может ли клиент от этого отписаться? Вы можете, не включая всю фичу, добавить только препроцессор #nullable enable annotations, и в этом случае компилятор будет считывать аннотации, которые вы добавите в этот код, и пользоваться ими для того, чтобы положить их в .dll.
Здесь я указал, что у клиента мы всегда спрашиваем имя и фамилию, а отчество он может не заполнять. Адреса у него может не быть, телефон он обязан оставить, а имейл — как пожелает.

Теперь посмотрим на декомпилированный код этой библиотеки — он покрылся атрибутами [NullableContext]. Я не буду вдаваться в подробности, как они работают, потому что это важно только компилятору. Но он будет их считывать, когда вы подключите эту библиотеку к вашему проекту, и будет предупреждать пользователей вашей библиотеки о том, как ей пользоваться.
Аналогичным образом это происходит, если вы используете в проекте dynamic — это всё тоже компилируется в атрибуты и скорее всего, вам это тоже не требуется знать, потому что это важно только для разработчиков компилятора.
Я перед этим говорил, что вы можете пользоваться этими аннотациями потому, что можете применять их везде, в том числе там, где атрибут повесить нельзя. Например с локальными переменными.
Как они тогда компилируются? Дело в том, что они вообще не компилируются, так как компилятор уже выдал вам о них предупреждения. И после этого их снаружи использовать нельзя, поэтому проблемы как бы и нет, ничего не изменилось вообще в результирующем коде.
Теперь мы готовы
Мы уже проаннотировали часть проекта, включили предупреждения, и наверное, можно даже на каком-то проекте включить всю фичу целиком. Вы можете сделать это либо в .csproj-файле при помощи свойства nullable enable, либо на уровне отдельных классов.

Включить, например, только в этом классе анализ, либо включить его только для метода, который может быть проаннотирован и более важен для вашего продукта. Не менее важной фичей является возможность отключить этот анализ на какой-нибудь части проекта. Опять же пример из NewthonsoftJson. Здесь был класс JsonValidatingReader, в котором было примерно 1000 строк кода, и этот код уже был обсолетным, его не нужно использовать в этой библиотеке, он переехал в другой пакет, поэтому аннотировать его, наверное, не имеет большого смысла. Это трудозатратно: просмотреть в очередной раз тысячу строк кода и подумать о том, что где-то тут может быть null, а где-то не может.
Поэтому вы можете при помощи препроцессора #nullable disable выключить в этой части вашего проекта и анализы, и аннотации. В результате оно скомпилируется без каких-либо аннотаций в качестве атрибутов. Люди, которые будут подключать эту библиотеку к своему проекту, будут знать о том, что эта часть контракта не проаннотирована.
Работаем с обобщенным кодом
Дальше расскажу о том, как это работает с обобщенным кодом. Но перед этим нужно понять, какие теперь есть отношения между nullable reference types и обычными.
Если у вас есть not-nullable строка, то с точки зрения системы типов она будет являться подтипом nullable-строки. Это логично, потому что всё, что вы можете положить в nullable-строку — это все значения not-nullable строки и еще одно дополнительное значение null. Поэтому в местах, где компилятор захочет вывести общий тип, например, если у вас создается массив и вы кладете в него переменные одновременно и с nullable-строками, и not-nullable строками, то компилятор будет выводить наиболее общий тип.

В данном случае это nullable-строка. Аналогично это будет работать в любом месте, где компилятору требуется вывести какой-то общий тип для нескольких переменных.
Например, если у вас есть какой-нибудь дженерик-метод, и вы в один и тот же тип параметров передаете аргумент с разными аннотациями. Кроме того, если вы получили oblivious-строки (напоминаю, что это строки из не проаннотированных контекстов). Например, из подключенной библиотеки, где автор не предоставил аннотации. Либо из той части проекта, где вы анализ выключили, но будучи проаннотированными, они будут автоматически конвертироваться в not-nullable строки.

То есть вы вызвали не проаннотированный метод, положили его в переменную. Компилятор теперь считает что там не может быть null, разрешает вам ей пользоваться и предупреждает, если вы положите туда null.
Но это с простыми типами, а как быть с дженериками? Если у вас есть последовательность not-nullable строк и последовательность nullable-строк, то с точки зрения системы типов вы можете положить not-nullable строки в nullable, но не наоборот.

Почему это происходит? Дело в том, что если у вас есть метод, который принимает последовательность строк, среди которых могут встретиться null значения, он их будет проверять, и если ни одного null не встретится, то проблемы нет, мы просто зря выполнили проверку. Но всё по-прежнему будет работать. А наоборот, к сожалению, работать не будет. Если у вас есть метод, и он принимает только not-nullable строки, то проверять на null он их не будет. Первый же null обрушит вашу программу с NullReferenceException.

С Action<string?> это будет работать немного по-другому. Если у вас есть метод, который говорит, что хочет Action, работающий с null значениями, то он может их туда передать. Если метод говорит, что работает только с Not-Null Action то он никуда null не передаст. Соответственно nullableAction готов и к тому развитию событий, и к другому. Если передали null, то работает с ним, а если не передают null — тоже работает. Его можно передавать куда угодно. Not-Nullable Action — только туда, где аннотации совпадают.

И у нас получилась теперь интересная ситуация, когда nullable-типы находятся с разных сторон. К вопросу о том, что я объяснял ранее относительно того, какой тип является подтипом другого.
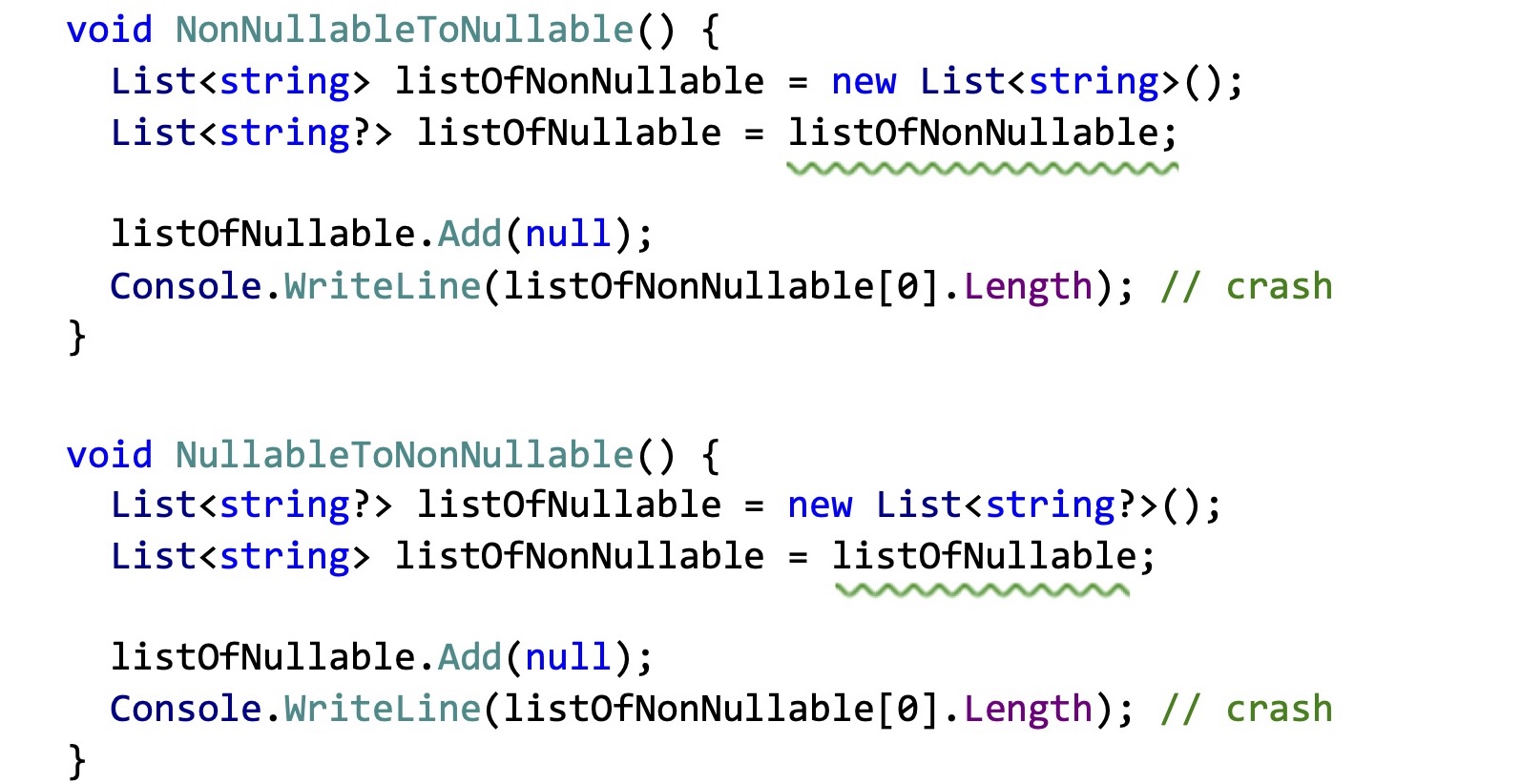
Дело в том, что если у вас есть какой-то список, и вы присваиваете одну переменную в другую, и у них есть по-разному проаннотированные элементы, то теперь у вас в программе появилось две ссылки на один и тот же list, но типизированные по-разному. А контракт списка позволяет как добавить в него элементы, так и прочитать. Мы можете через ссылку, которая говорит, что это list от nullable-строк, добавить null, а через ссылку, которая говорит, что здесь null не бывает, прочитать его обратно и получить в рантайме исключение. Чтобы такого не было, компилятор в принципе запрещает вам преобразование из одного типа в другой. Причем как в одну, так и в другую сторону, потому что в конечном итоге у вас точно так же появляются две ссылки на один и тот же list.
Изменения с выводом типов
Не менее интересны изменения, которые произошли с выводом типов. Допустим, у вас есть переменная, тип которой мы выводим из правой части, то есть обозначенная как var.
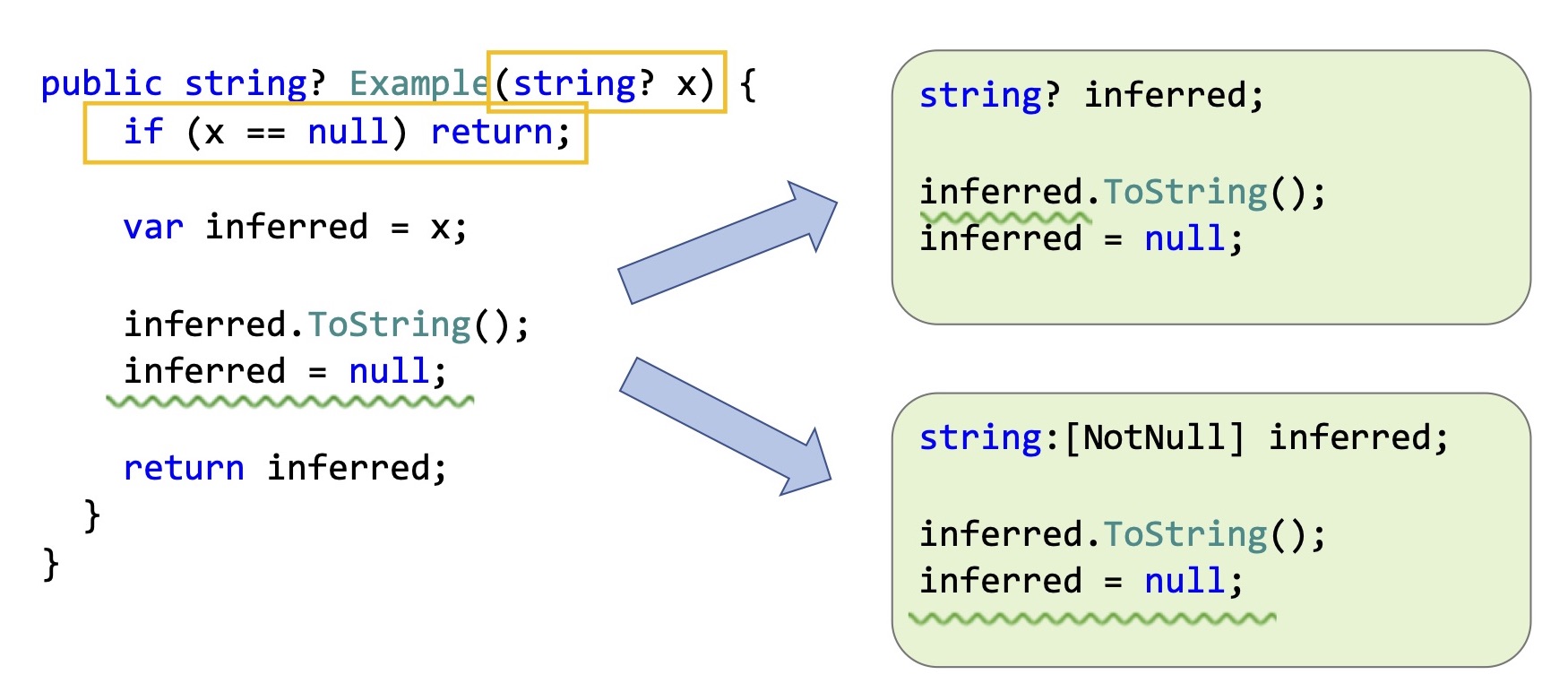
Обычно мы для этого смотрим на то, чем ее инициализировали. В данном случае — параметром x. Параметр x объявлен как Nullable string. inferred тоже должен, казалось бы, вывестись, как Nullable string, компилятор должен потребовать проверить, что там не null перед тем, как вы им пользуетесь. И разрешить присваивать туда null.
Существует альтернативный вариант: мы можем посмотреть на значения, которые там находятся, то есть сделать честный Data Flow Analysis метода, узнать, что мы уже проверили, что конкретно в этой переменной null уже не бывает, и вывести not-nullable string и разрешить пользоваться этой переменной. Но предупредить, если мы присваиваем туда null.
На самом деле, компилятор проведет честный Data Flow Analysis, после этого еще раз подменит у себя информацию о типе переменной и скажет, что хорошо, мы знаем, что здесь никогда null значений не бывает, выведет not-nullable тип, разрешит ей пользоваться, запретит вам присваивать туда null. Потому что тип переменной все еще not null, а не что-то неизвестное.
Новые ограничения для параметров типа
Кроме того, теперь с nullable-reference типами вы можете добавлять generic constraints, аннотируя их. А старые constraints теперь означают, что сюда нельзя подставлять nullable-reference типы. Только старые типы, не допускающие null значений, которые не нужно проверять.

Если вы хотите это изменить, то вам нужно воспользоваться тем же самым новым синтаксисом с вопросом на конце. Такое же расширение получил constraint class (where T: class). Теперь у вас class означает, что сюда можно поставить всё, но только не nullable классы. Но можно записать его с вопросом, и тогда можно будет подставить любой reference-тип. Кроме того, появился новый constraint notnull (where T: notnull), который будет означать, что сюда можно подставить любой тип, который не допускает значение null. То есть либо структура, либо not-nullable reference type. Поэтому теперь, если у вас есть класс, метод с constraint class:
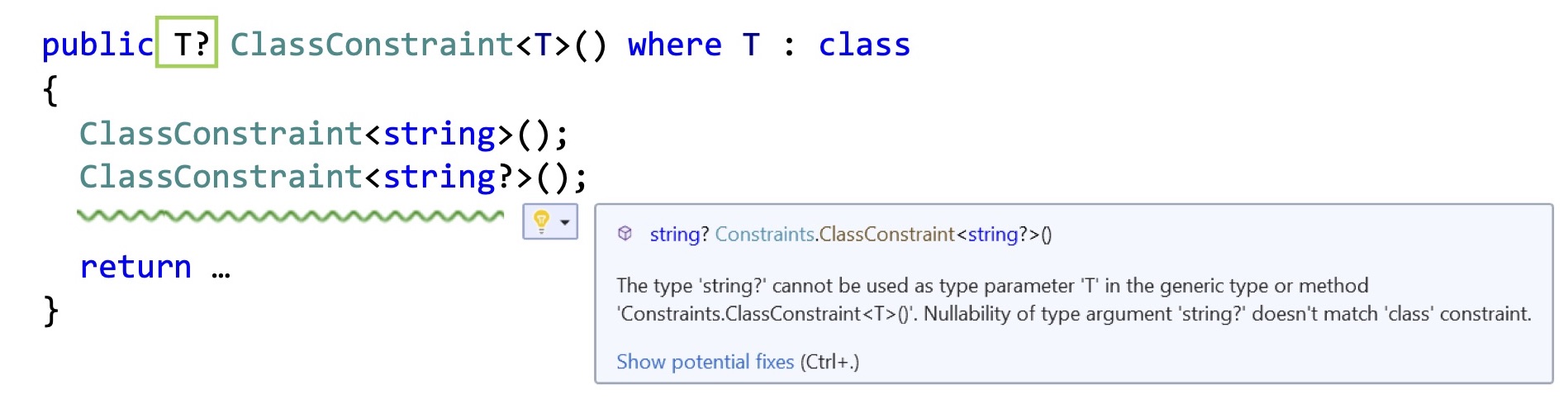
Он теперь компилируется как constraint на not-nullable reference type. Вы получаете предупреждение, если пытаетесь поставить туда nullable reference types. И вы теперь можете пользоваться с этим типом параметра тем же самым синтаксисом. Потому что теперь компилятор знает, что это reference-тип, что его можно проаннотировать, и позволяет вам также писать вопросы, как и с обычными string. Давайте попытаемся воспользоваться этим и проаннотировать какой-нибудь утильный метод из вашего фреймворка.
Аннотируем свой фреймворк
Например, у нас будет метод, который получает коллекцию элементов с constraint на IKeyOwner и пытается найти элемент по ключу. Если получилось — возвращает его. Если нет — то возвращает дефолтное значение.

Дело в том, что если мы попытаемся так написать, то компилятор скажет нам, что он не знает, что значит этот синтаксис. Дело в том, что интерфейс IKeyOwner можно реализовать как структурой, так и классом. А синтаксис с вопросом на конце должен означать для них разные вещи.
В одном случае это должно означать, что метод должен вернуть структуру Nullable<T>, в другом случае это должно означать, что это просто аннотация, a типы не меняются.
Как быть? Компилятор в своей подсказке предлагает нам добавить constraint class. Давайте попробуем это сделать.

Что произошло? Во-первых, теперь мы не можем пользоваться этими структурами, но возможно, они у вас в проекте не используются, и вам это не очень важно.
К сожалению, с классами тоже не всё до конца работает, потому что мы задали constraint на not-nullable классы, а хотели бы пользоваться любыми. Если есть массив, в котором лежат nullable-значения, то мы не можем использовать этот метод, чтобы найти в нем элемент. Может быть, нам поможет новый constraint class?

Во-первых, при этом мы должны убрать вопрос с возвращаемого значения, потому что компилятор говорит, что и так можно подставить Nullable<T>. Но кроме того, это теперь не работает с Not-Nullable<T>. Если у нас есть массив, в котором null не бывает, мы пытаемся найти в нём элемент, в качестве типа аргумента выводится not-nullable тип, сигнатура говорит, что возвращает not-nullable тип, проверять его не требуется, предупреждений нет. Кажется, мы не можем написать такой простой метод.
К счастью, в языке уже есть место, где похожая семантика используется, это FirstOrDefault. Давайте попробуем написать с ним код и посмотрим, что он-то хотя бы работает. Создадим программу, возьмем пустой массив, возьмем из него первый элемент и попытаемся его разыменовать. Никаких предупреждений не случилось, но случилось исключение в рантайме.

Неужели вы думаете, что сигнатуру FirstOrDefault теперь писать нельзя, а язык сломан? Думаете, что можно? А почему тогда этот пример не работает?
На самом деле, сигнатуру FirstOrDefault теперь в языке написать можно, просто не успели обновить этот фреймворк. Если мы посмотрим на исходники .NET Core на GitHub, то мы обнаружим, что даже в превью .NET Core 3.1, который сейчас доступен, сигнатура FirstOrDefault выглядит по-старому, а в master branch, который скорее всего будет в .NET Core 3.2, появился новый атрибут на возвращаемом значении.


Мы можем попытаться применить его к нашему методу и посмотреть, что произойдет. Этот атрибут лежит в namespace System.Diagnostics.CodeAnalysis.MayBeNull, и теперь внезапно всё начало работать правильно, несмотря на то, что мы подставляем в тип-параметр not-nullable тип, для возвращаемого значения компилятор добавляет к нему аннотацию и выдает нам корректное предупреждение.

Кстати, а как это будет работать со структурами? Они станут теперь Nullable<T> или нет? На самом деле, всё останется по-старому, потому что этот атрибут действительно просто добавляет аннотацию, если может добавить.
То есть для структур по-прежнему это точно not-nullable значение, всё работает по-старому, а с nullable reference-типами, если вы примените атрибут к возвращаемому значению метода, то компилятор продвинет его до nullable-версии типа, если это возможно. Последним штрихом у нас еще где-то есть Assert в программе, давайте добавим его в этот метод.

Опять что-то пошло не так. Дело в том, что теперь мы объявили input как not-nullable параметр, проверили при помощи ассерта, что он действительно not-null, а компилятор требует проверить еще раз.
Это происходит из-за того, что компилятор не знает, что имел в виду метод Assert. У него есть только название, и всё, что видит компилятор, — у нас есть переменная, и по какой-то причине программист проверяет ее на null. Наверное, он там может лежать. Результат этой проверки в виде bool куда-то передается, а затем снова пользуется переменной без проверок. Чтобы компилятор понял, что хотел сказать автор, ему нужно подсказать.

Тоже атрибутом из System.Diagnostics.CodeAnalysis — [DoesNotReturnIf(false)], который теперь скажет компилятору, что если условия, которые мы передали в этот метод, вычисляются в false, то этот метод никогда нормально не вернется. Он либо зациклится, либо выдаст исключение. И теперь этот метод можно использовать действительно для честных asserts, когда вам откуда-то возвращается nullable-строка, например, но вы знаете, что конкретно с этой комбинацией аргументов она null быть не должна, и можете сказать компилятору об этом.
Атрибуты-помощники
В System.Diagnostics.CodeAnalysis довольно много атрибутов, которые в основном помогают компилятору понять, что хотел сказать автор.

Если есть дженерик-код, который нельзя правильно проаннотировать, либо если есть какие-то сложные контракты. Когда в общем случае метод должен работать по одному сценарию, но в некоторых условиях может вернуть странное значение.
Я сейчас кратко расскажу о том, что делает каждый из них и где он используется во фреймворке, чтобы у вас был пример, для чего это нужно. А также, если вы пользуетесь аннотациями JetBrains Annotations, какой аннотации JetBrains соответствует каждый из них. Первая группа атрибутов — это [NotNull], [AllowNull], [DisallowNull].
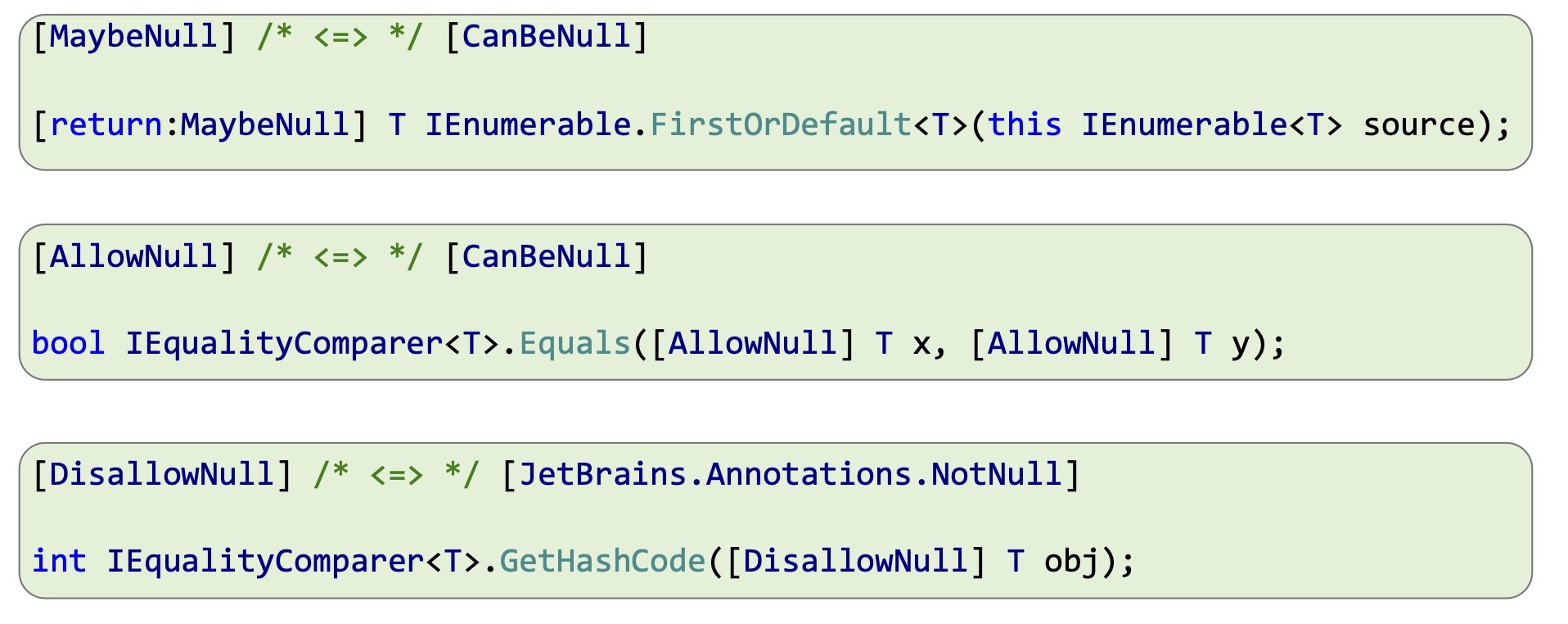
Они позволяют переопределить аннотацию. В основном они нужны для дженерик типов параметров, которые компилятор запрещает аннотировать. Например, в IEnumerable.FirstOrDefault уже он используется. Либо в IEqualityComparer.
Кроме того, у вас есть группа атрибутов, которые говорят, что в некоторых случаях метод нормально не завершается — это [NotNull] атрибут. Не нужно путать его с JetBrains annotations Not Null, он называется так же, но лежит в другом namespace и в другой сборке и означает совершенно другое. Он означает, что если вы передали null в какой-то параметр, то метод выбросит исключение.

И также есть пара атрибутов [DoesNotReturn], [DoesNotReturnIf(true)] или (false), которые во фреймворке используются для того, чтобы проаннотировать Debug.Assert(), Debug.Fail().

И последняя группа атрибутов. Это атрибуты, которые позволяют связать входные и выходные значения метода. Например, если у вас есть словарь и он проаннотирован как словарь, в котором никогда null не лежит, то метод TryGetValue, если он вернул false, все еще может вернуть null. То есть несмотря на аннотацию сигнатуры, которая говорит, что в словаре никогда не лежит null-значение, все еще метод может вернуть null. И это выражается таким атрибутом.
Аналогично [NotNullWhen(true)] или false определяет сигнатуру в обратную сторону. И последний атрибут [NotNullIfNotNull] говорит, что если в какой-то параметр был передан not null, то и вернется тоже not null. Например, во фреймворке есть метод Path.GetFileName, который таким контрактом обладает.

И последнее, что хотелось бы сказать про эти атрибуты, — это просто подсказка компилятору, что должен делать метод. Компилятор будет полагаться на эти аннотации при анализе использования метода.
Во-первых, скорее всего, вам это потребуется только с каким-то дженерик-кодом в вашем фреймворке, который обладает странным контрактом, и в повседневной жизни вам не придется непрерывно искать, как проаннотировать ваш метод. Скорее всего, это потребуется сделать один раз при переводе общей кодовой базы вашего проекта. Кроме того, компилятор не будет проверять, что этот метод соответствует тому, что вы проаннотировали, в отличие от code-контрактов. Ни в местах вызова, ни в самом методе ни рантайм-проверок, ни compile time-проверок не будет. Компилятор просто верит вам на слово, и если вы написали контракт для метода, а потом его не придерживаетесь, то сами виноваты.
А что, если компилятор все равно не прав?
А что делать, если компилятор после всего этого оказался неправ, то есть мы не смогли объяснить ему, что хотел сказать автор? В методах, которые мы описали, есть еще одно предупреждение, о котором я не упомянул, — это return default.

Во-первых, что такое default? В новом мире у нас есть строка, она объявлена как not-nullable строка. Мы присваиваем в нее default. Кто думает, что будет пустая строка и всё хорошо?
На самом деле, несмотря на то, что это not-nullable reference тип, значение default для него все еще null. Аннотации влияют только на compile-time предупреждения. Они не влияют на то, как будет компилироваться это дефолтное значение. Кроме того, если у вас есть сложный класс с конструктором, который принимает какие-то аргументы, компилятор не знает, как создать этот класс, поэтому он всегда будет ставить null, но будет вас предупреждать об этом.
В примере выше именно об этом и предупреждает нас компилятор, что мы возвращаем default, но тип-параметр в этом методе может быть подставлен как not-nullable тип, а про аннотацию он ничего не знает, потому что вернется к ней, когда найдет использование этого метода.
Однако это предупреждение здесь бесполезно, так как мы знаем, что конкретно здесь наши аннотации разрешают вернуть null. Поэтому мы должны быть немного настойчивее. Если сказали вернуть дефолт, вернуть дефолт! Поставьте ! — компилятор вам это разрешит.

Dammit-оператор ! (null-forgiving оператор)
Это новый синтаксис, который неформально называется dammit-оператор, и он используется для того, чтобы в каком-нибудь выражении просто убрать предупреждения компилятора, потому что каждый раз, когда анализ ошибается, писать #pragma warnings disable не очень удобно. Если компилятор в каком-то месте выдал неправильную ошибку, то вы можете либо игнорировать предупреждение, либо добавить ассерт, либо использовать dammit-оператор.

Этот оператор также позволяет инициализировать non-nullable переменные nullами, но так лучше не делать. Если у вас есть такое место, то потом вернитесь к нему, инициализируйте корректно. Если вы ее не инициализировали, компилятор узнает об этом и разрешит вам ей пользоваться, если нет — что-то пошло не так.

Стоит заметить, что dammit-оператор никогда не добавляет рантайм-проверок, и он просто убирает предупреждение в одном месте.
Кроме того, с dammit-оператором есть еще одна проблема, которую мы рассмотрим на следующем примере.
У нас есть код, который работает с неуспешными транзакциями.

Первый метод возвращает список таких транзакций и пользователей, которые их совершили, при этом, так как обычно все транзакции проходят успешно, метод может вернуть null. Однако, если все же вернул словарь, в нем уже null быть не может.
А второй метод возвращает список транзакций на взятие комиссии, которые созданы нашей системой, а не пользователями.
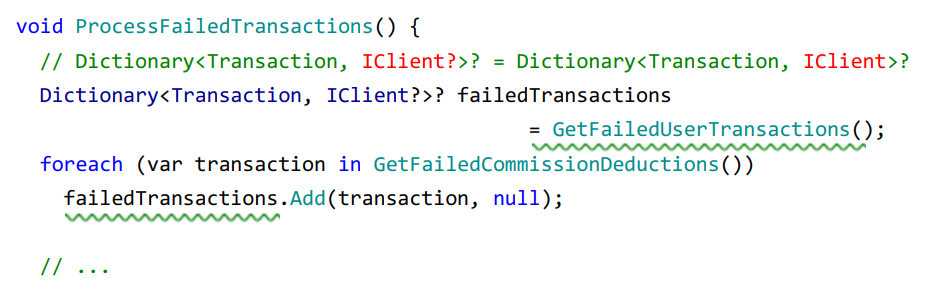
И у нас есть таск, который будет получать словарь и как-то с ним работать: докидывать в пользовательские транзакции наши и пытаться что-то с ними сделать.
Однако здесь есть предупреждение. Мы получили словарь, а словарь мог вернуться как null. Пока всё хорошо. В этом коде есть второе предупреждение о том, что мы потом пытаемся в этот словарь добавить null. Словарь должен быть обозначен как содержащий в качестве значений nullable-типы. Метод, который позволяет нам получить транзакции для пользователя, возвращает not-nullable типы.
Я уже рассказывал на примере с list, почему такая конверсия запрещена. Конкретно здесь проблемы нет, проблема возникала из-за того, что мы получали две ссылки, типизированные по-разному. Здесь же мы получаем ссылку, просто меняем ей тип, старую ссылку выбрасываем. Остается просто словарь, можем положить в него null, можем из него null прочитать.
Проблемы на самом деле нет, чтобы решить вопрос с предупреждением, можем переложить из этого словаря в другой значение. Но кажется, это не имеет смысла, потому что мы просто потратим время, память. Давайте задавим предупреждение, потому что знаем, что проблемы нет. Добавим восклицательный знак. К сожалению, в этом методе произошло еще одно изменение, которое сейчас видно на слайде, но в реальном проекте это могут быть десятки строк ниже, где-то за границей экрана.
Несмотря на то, что мы объявили метод, который получает пользовательские транзакции, как метод, возвращающий null вместо словаря, мы объявили переменную как переменную, которая содержит null. Компилятор всё еще не предупреждает нас о том, что мы ей пользуемся.
Это случилось потому, что помимо того, чтобы задавить все предупреждения, восклицательный знак также говорит компилятору, что конкретно это значение не является null. К сожалению, об этом нужно помнить. Если вы будете пытаться бороться со сложными предупреждениями, то вам нужно это учитывать, потому что в противном случае вы просто можете быть уверены, что здесь null не бывает, потому что никаких предупреждений нет. Компилятор вас защищает. На самом деле, вы изменили семантику тем, что убрали предупреждение в другом месте.
А что если компилятор слишком прав?
Иногда компилятор ошибается в другую сторону и выдает вам слишком правильный тип.
Это пример от Дэвида Кина, разработчика Visual Studio из Microsoft. И с его слов: «Кажется, компилятор игнорирует меня, когда я пытаюсь ему сказать, что это nullable-строка».
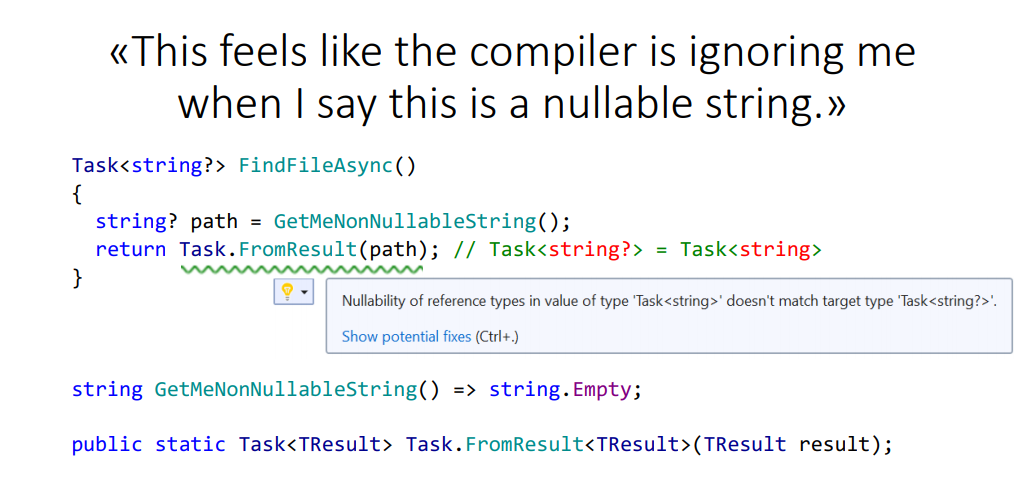
У него есть метод, который работает с путями к файлам. Он пытается асинхронно получить путь к файлу и возвращает Task<string?>, в переменной тоже nullable string. Делает Task.FromResult, выводит тип task, исходя из аргумента. Но из-за того, что метод GetMeNonNullableString вернул ему строку, в которой не бывает null, компилятор знает, что там не бывает null, он использует это знание для того, чтобы вывести типы, говорит, что типы не сошлись в возвращаемом значении.
Первое, что замечаем, — компилятор отмечает, что это правильное поведение, это действительно by design.

Дело в том, что если у вас действительно мог быть null в этой переменной и вы уже проверили, что это не так, вы хотели бы пользоваться более точным типом для вывода типов и здесь вывести таск от not-nullable string.
Но как тогда быть в исходном примере? У нас есть предупреждение, его там быть не должно. Если мы подняли его до ошибки, то у нас не компилируется проект.

Первое, что мы можем сделать, это использовать все тот же dammit-оператор для того, чтобы убрать здесь ошибку. Всё будет компилироваться, и кажется, что проблемы нет.

Кроме того, можно явно указать тип аргумента и сказать, что это не просто task from result, который должен вывести свой тип аргумента из переданного значения, а task from result от nullable-строк. Тогда тоже всё будет работать. Но, возможно, это будет длинно для сложных дженерик-вызовов.

И последнее, что вы можете сделать, это кастануть значение, получаемое из метода, к nullable версии того же типа. Почему, в отличие от переменной, это работает?
Дело в том, что компилятор не знает, зачем вы объявили переменную как nullable. Может быть, потом вы когда-нибудь будете класть в нее null, получив его из другого метода. Когда вы делаете cast, компилятор знает, что это конкретно про то значение, которое получили. Вы хотите в этом месте трактовать его как nullable-значение, и вы уже и переменную можете неявно типизировать и использовать, и всё тоже будет работать.
Итак, если компилятор не справляется с вашим кодом, то чтобы донести свою мысль до компилятора, вы можете либо использовать assert, либо dammit-оператор, если компилятор говорит, что где-то бывает null, а вы как программист знаете, что здесь это невозможно.
Вы можете, когда в обратную сторону вам нужен nullable-тип для вывода типов, либо сделать каст, либо указать явные типы-аргументы.
Наконец, если у вас есть более сложное предупреждение, например, преобразование сложных дженерик-типов со словарями, то вы можете использовать dammit-оператор. Главное — убедиться в том, что вы случайно не сказали компилятору сделать больше, чем нужно, и никаких побочных эффектов не случилось.
Помимо этого вы можете пользоваться препроцессором pragma warnings disable, nullable disable warnings для того, чтобы убрать предупреждения в конкретном регионе кода.

Где нужно быть особенно внимательным?
Существуют традиционно сложные места для data flow-анализа:
- Не проаннотированные библиотеки
- Инициализация массивов
- ref/in/out параметры и переменные
- Кросс-процедурные зависимости
- Замыкания
Рассмотрим подробнее каждый из этих случаев.
Использование не проаннотированных библиотек
Возьмем библиотеку NLog.
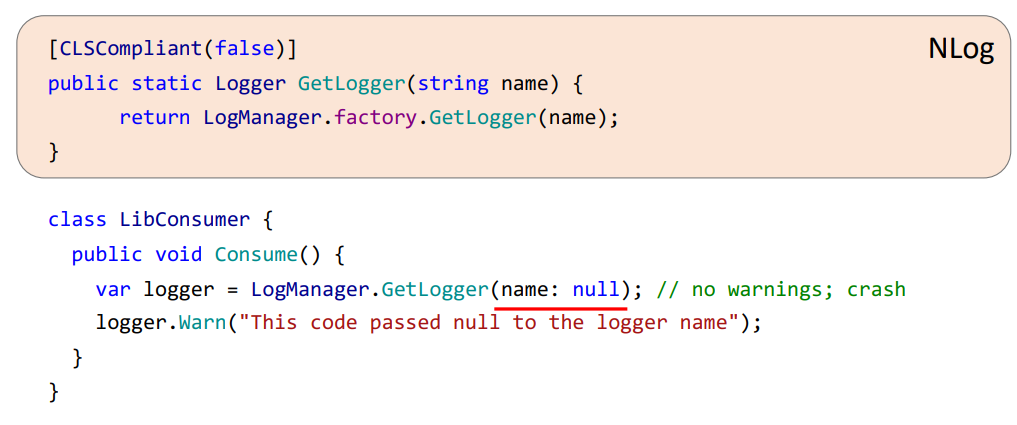
В ней есть метод GetLogger, который принимает параметр string name. Ничего не зная о методе и как с ним работать, вы можете попытаться передать туда null, специально или случайно, например передавая другую переменную, которую вы не проверили на null. И даже если ваш код проаннотирован, никаких предупреждений вы от этого не получите, но в рантайме произойдет исключение. Дело в том, что библиотека NLog еще не проаннотированна и компилятор просто не знает, допускается ли там null или нет.
Кстати, если мы посмотрим на статистику скачивания пакетов с NuGet.org, то обнаружим, что среди топ-20 пакетов, не включая зависимые пакеты, например, xUnit, проаннотирован лишь Newtonsoft.json (на момент 2019 года)
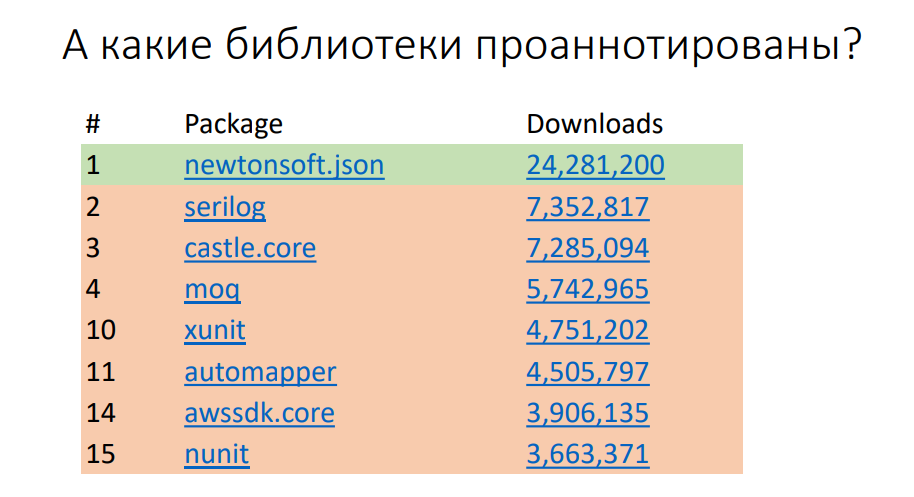
На момент выхода статьи (август 2021) ситуация изменилась. Подробнее о состоянии на декабрь 2020 в докладе Джареда Парсонса Nullability in C#. Доклад не расшифрован, но в видео по ссылке есть русские субтитры.
Возможно, это связано с тем, что например, xUnit аннотировать не то чтобы сильно надо. Он практически всегда отдает вам not null, принимает nulls и тоже работает с этим. Какие-то библиотеки пока слишком масштабные, чтобы проаннотировать их за несколько месяцев с тех пор, как вышел C# 8. Надеюсь, в скором это изменится к лучшему.
Инициализация массивов
Кроме того, существуют места, которые команда компилятора просто не смогла поддержать.

К примеру, массивы мы заполняем не инициализатором, а просто объявляем их. В этот момент мы получаем массив, в котором все элементы забиты значением null, и казалось бы, нужно предупреждение. Но обычно мы сразу заполняем его в цикле, поэтому предупреждения решили не делать, а поскольку проверить, что вы действительно зашли и заполнили каждый элемент массива, достаточно сложно, то даже если вы этого делать не будете, никаких предупреждений у вас не появится, но в рантайме будет исключение.
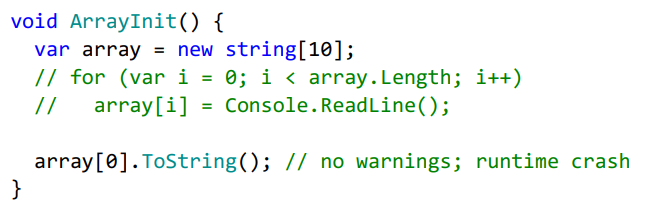
Кросс-процедурные зависимости
Еще одна проблема — это кросс-процедурные зависимости. Например, если у вас есть кусок программы, который отвечает за генерацию контента, к примеру презентации.

На слайде может быть изображение, текст и, возможно, другие колонки с контентом. Также у нас есть метод FormatContent, который при наличии изображения и текста форматирует слайд в две колонки с ними. Внутри этого метода используется метод SetTwoColumnsTemplate, который инициализирует слайд с двумя колонками. Но так как компилятор этого не знает, он выдает предупреждение при обращении к элементу массива Columns, поэтому можно просто поставить dammit-оператор.
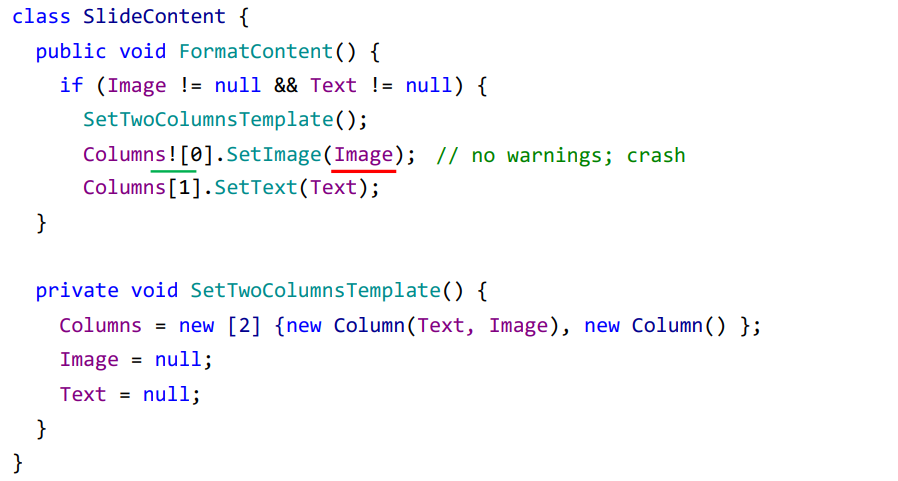
Однако если посмотреть реализацию метода SetTwoColumnsTemplate, мы видим, что он сам кладет в первую колонку текст и изображение и соответственно стирает со слайда Image и Text. Но и об этом компилятор не знает, поэтому не выдает предупреждений в первом методе, так как проверка на null уже была.
Подобное поведение является балансом между количеством ложноположительных предупреждений и точностью анализа. Команда компилятора выбрала считать, что instance-методы никогда не изменяют значение полей, и если вы бы хотели в таких ситуациях получать предупреждение, вам стоит воспользоваться другим анализатором, например ReSharper или PVS-Studio.
Ref/in/out параметры
Кроме того есть еще ref/in/out параметры. Они могут измениться в любой момент, независимо от того, что делает метод, потому что это ссылка.

Если у вас есть аргумент check, который принимает not-nullable reference, компилятор будет проверять только то, что значение, которое ему передали по ссылке прямо сейчас, соответствует тому, что хочет метод.
Мы проверили, что в field не лежит null, передали его по ссылке в этот метод. Метод, например, заполнил, сбросил field и прочитал это же значение по ссылке через свой аргумент, и опять же не случилось предупреждений, в рантайме всё упало.
Замыкания
Компилятор не может выяснить, когда вы будете вызывать лямбду и что онабудет делать в этот момент.

Поэтому если в лямбде вы инициализируете замкнутое nullable-значение и вызовете ее, компилятор об этом не узнает, поэтому все равно будет выдавать предупреждение. В данном случае это безвредно, так как это просто предупреждение, которое можно убрать, например, поставив проверку.

Однако это работает и в обратном случае. Если вы проверили переменную, в лямбде значение сбросили на null и после этого пытаетесь воспользоваться этой переменной, предупреждения вы не получите, но исключение в рантайме будет.
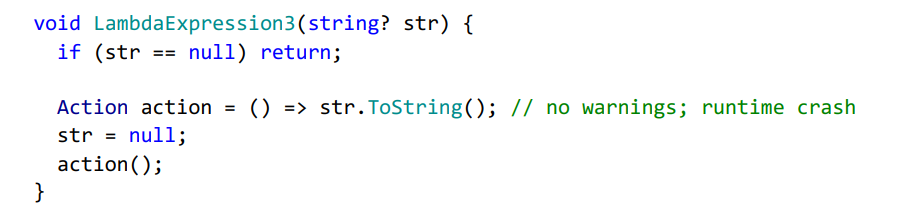
Наконец, анализ может работать некорректно и в теле лямбда-функции с замыканием. Компилятор предполагает, что единственное место, где лямбда может быть выполнена — это там, где вы ее объявили.

Если вы в ней замкнулись на переменную, потом прочитали ее в лямбде, сбросили на null и вызвали тот делегат, то компилятор вам ничем не поможет.
При этом в случае локальных функций, так как они могут быть объявлены в любом месте метода, даже в недостижимой зоне, например после return, компилятор производит анализ исходя только из объявленных типов замкнутых переменных.
С локальными функциями у команды компилятора есть планы как минимум добавить поддержку инициализаторов полей в конструкторах, когда они выполнены как локальные функции.
Аннотация массивов
Еще одно интересное место, в котором вам нужно быть внимательными, — это аннотация массивов. Дело в том, что при чтении из массивов в C#, итераторы всегда указывались в том порядке, в котором вы их объявляли, например:

Однако если рассматривать каждый массив, как отдельный тип, кажется, что тип string[][,][,,] обозначает трехмерный массив, состоящий из двухмерных массивов, элементы которых являются массивы stringов. Чтобы лучше понять это, можно проставить скобки: ((string[])[,])[,,], в этом случае правильнее было бы обращаться к элементам массива так: array[3,3,3][2,2][1], но для удобства в C# используется обратный порядок индексаторов — слева направо, то есть string[][,][,,] на самом деле обозначает одномерный массив из string[,][,,].

Однако, если мы проаннотируем массивы при помощи нового синтаксиса, использовать их таким же образом не получится, так как теперь каждый отдельный проаннотированный массив считается отдельным типом, поэтому в примере выше, для чтения элемента нужно использовать порядок справа налево. Более того, так как каждый nullable массив может быть null, нужно также использовать оператор ?[].
Чтобы закрепить это, предлагаю пройти небольшой quiz:

Какой из этих трех вариантов обращения к элементу массива является правильным в данном случае с одной аннотацией? (без учета оператора ?[])

Правильный ответ: 3. Потому что string[]? считается отдельным типом, и на него не действует синтаксический сахар, в виде перестановки индексаторов в обратном порядке, то есть этот тип можно представить так: (string[]?)[,][,,], при этом последние два индексатора работают как принято в C#: слева направо. Можно представить, что string[], это просто какой-то класс с индексатором, назовем его T, тогда для получения объекта класса T из типа T?[,][,,], нужно обратиться к элементу массива как обычно: array[2,2][3,3,3] и уже потом можно воспользоваться индикатором класса, если значение элемента не null: (array[2,2][3,3,3])?[1].
При этом объявляться такой массив будет так:

Как такое могло случиться?

Дело в том что изначально, когда у нас был C# 7.3, nullable-типы были запрещены в паттерн-матчинге из-за того, что компилятор не учитывает, как расставлены пробелы, и не может понять, что вы имели в виду. Вы имели в виду, что это паттерн-матчинг с nullable-переменной, для которой он должен создать переменную, а затем — двоеточие, либо, что это conditional expression?:
В каком порядке это парсить? Nullable-типы были запрещены.

Потом, когда появились nullable reference-типы, они также были запрещены в type checks и паттерн-матчинге по тем же причинам.

Но с массивами была странная ситуация: одномерные nullable-массивы были запрещены по той же причине, так как ? находится в конце, при этом если только вложенный тип был nullable, например string?[], то все в порядке, так как никакой неоднозначности нет. Но в случае с массивом массивов, ? относится не к top-level типу, а к вложенному, из-за обратного порядка. Поэтому компилятор также считал, что все в порядке, хотя на самом деле здесь снова возникала синтаксическая неоднозначность. Поэтому команда компилятора решила изменить синтаксис таким образом, что последний ? всегда привязан к top-level типу.
Если вам интересно, как такое случилось и какие именно breaking changes были обнаружены со старым синтаксисом, вы можете пройти по ссылке, где была эта дискуссия.
Warning as errors
Напоследок я расскажу про warning as errors. Я часто встречаю такое мнение: «Сейчас мы поднимем предупреждения до ошибок, компилятор подскажет нам все места, где может быть NullReferenceException и у нас будет всё прекрасно: проверять ничего не надо, тестировать ничего не надо, всё всегда будет хорошо».
Вы действительно будете быстрее обнаруживать ошибки при изменениях в коде. Также вы сможете сразу заметить изменения контрактов в сторонних библиотеках при их изменениях, так как у вас просто перестанет компилироваться проект.
Но ваш код станет слишком хрупким, и при рефакторингах будут появляться ошибки. Иногда вы не сможете объявить переменную того типа, который хотели бы, например, для out var переменных. И так как вы больше не можете просто игнорировать некоторые предупреждения, ваш код может наполниться бессмысленными проверками, где анализ не справляется.

Вот несколько примеров таких проблем.
Первый пример отметила команда ASP.NET, когда они достаточно рано начали использовать nullable reference-типы, в том числе подняли их до ошибок. Суть примера сводилась к тому, что у них было две переменные, и они их попарно проверяли. Сначала обе null, потом обе — not null, потом первая not null.

Здесь на последней строчке мы точно знаем, что two — не null, а one — null, но компилятор об этих зависимостях между переменными не знает и анализирует их независимо, поэтому здесь будет ошибка. В этом случае порекомендовали пользоваться dammit-оператором, мы просто оставили этот тикет как пример несовершенства анализа, который вряд ли будет исправлен.

Это пример того, как легко код с nullability и warnings as errors ломается рефакторингом. К примеру в какой-то момент метод M1 стал слишком большой и вы решили разбить его следующим образом:

Но так как компилятор не делает кросс-процедурный анализ, здесь появится ошибка. И этот недостаток анализатора также сложно исправить, так как для этого нужно будет проверить, что везде, где вызывается этот метод, передаваемый аргумент не является nullable, либо уже была проверка на null.

Вот еще один пример рефакторинга. В первом методе все хорошо, никаких предупреждений нет и все работает, так как если a равен null, то выражение null is B будет равно false.
Но если, как во втором методе, выделить выражение в отдельную переменную и использовать оператор as, появится ошибка, так как компилятор не знает, что если b != null, то a не могло быть null, потому что это слишком сложно.
Есть пример, когда человек в конструкторе задал значение, в соседнем методе пытается его использовать. В данном случае человек использует опцию warning source errors, поэтому его код не компилируется. Это происходит потому, что свойство item groups, которое он пытается прочитать, отмечено как nullable, и компилятор в методах не знает ни что было задано в конструкторе, ни могло ли это что-то измениться по мере исполнения программы. Отмечено как not nullable — будь добр проверить.
Dammit-оператор нельзя использовать везде в языке. Его можно использовать, чтобы убрать предупреждения из каких-то выражений, но не с объявления переменных. Например, если у вас есть dictionary try get value, вы пытаетесь получить из него string, то поскольку он отмечен TryGetValue, пройдет ли get value в случае, если он вернул false, положит в эту переменную null, то вы должны также переменную объявить как nullable. В этом месте вы даже не можете убрать предупреждение при помощи dammit-оператора.
Официальная рекомендация команды Microsoft — пользуйтесь старым синтаксисом C# 5, объявите переменную где-нибудь еще, тогда сможете воспользоваться dammit-оператором. Помимо этого в паттерн-матчинге я рассказывал на примере с массивами, почему так случилось, что nullable reference-типы там нельзя использовать. Поэтому все переменные с паттерн-матчингом у вас будут not nullable кроме var-переменных. Положить в них null потом будет нельзя. Вы можете либо пользоваться dammit-операторами, либо объявить вторую переменную, которая будет с тем типом, который вам нужен.
Выводы
Nullable reference-типы — большая фича, вы действительно будете получать больше информации о коде, если вы перейдете.
Вы сразу увидите, какая часть вашей программы допускает null, а какая — нет. Вы сможете найти больше ошибок на этапе разработки.
Но анализ может ошибаться. Если старый анализ Roslyn действительно сигнализировал о критических проблемах в коде, то либо вы забыли удалить переменную, либо использовали что-то другое в вашем коде. Анализ не может быть точным.
Если вы переводите большой проект на nullable reference-типы, рекомендую вам это сделать, потому что вы потратите меньше времени на поиск мест, в каких бывает null, а в каких — нет. Можно сделать это постепенно при помощи null-директив. Вы можете аннотировать фреймворк, вам понадобится это для сложных контрактов при помощи System.Diagnostics.CodeAnalysis-атрибутов.
Warnings as errors может сделать ваш код слишком хрупким.
Следующий DotNext пройдет онлайн с 21 по 22 октября. Билеты уже в продаже (и постепенно дорожают), программа на сайте появится позже. А если вам есть что поведать дотнетчикам, сейчас последняя возможность лично оказаться в этой программе: принимаем заявки на доклады до понедельника 16-го включительно.
