Доброго времени суток habr, на связи Николай Иванов, студент-магистр 1 курса Сколтеха факультета Data Science. С почином, так как это моя первая, и, надеюсь, не последняя статья на habr. С того момента как я познакомился с областью Deep Learning прошло уже около двух лет. С самого начала мне была интересна область обработки естественного языка (Natural Laguage Processing, NLP), о некоторых задачах которой и результатах я попробую рассказать в этой статье. В мае 2023 года начался мой путь в Sber AI Lab в замечательном центре медицины. Мой рассказ будет в какой-то степени сравнением того что было сделано до меня и того, какие идеи мы развили, что получилось, а что не получилось. Хочу сослаться на замечательную статью Даниила (ссылка), который использовал модель RuBioBERTa для задач из MedBench. Я же буду использовать другое решение, посмотрим, чем оно лучше, чем хуже и вообще насколько подходит для NLP-задач в медицине.
Немного оффтопа
Я очень рад, что каждый месяц появляются новые, более сложные и интересные архитектуры, реализующие смелые идеи, которые двигают вперёд области Deep Learning, NLP и Computer Vision (CV), но сколько из них реально используются в прикладных задачах? Вот оценка внедрения AI решений по странам (на основании отчёта IBM Global AI Adoption Index 2022):

А что с данными по России? Статистика (ссылка) за 2021 год показывает, что около 21% компании в России внедрили ИИ. Данных за 2022 пока нет, экстраполируем примерно на 25%, что весьма неплохо.

Теперь более предметно, что с медициной? Ведь медицина — очень деликатное и регламентированное направление. Пока что около 16% организаций сферы здравоохранения внедряют технологии искусственного интеллекта (ссылка). Потенциал роста огромный! В 2022 году вышла очень интересная статья: "Почему внедрение ИИ в медицину отстаёт?", где весьма аргументировано написано, почему человечество сталкивается с трудностями в этом процессе. Анализ изображений в медицине однако, достаточно хорошо принял ИИ: IRA LABS, UNIM, DINGOCAT и др. компании уже используют ИИ для анализа мед снимков. В таких задачах действительно происходит уменьшение времени работы врача, улучшается конверсия пациентов (больше пациентов получают более качественные услуги за меньший промежуток времени, следовательно система успевает принять больше пациентов).
NLP
А что с NLP в медицине? 98% медицинских организаций или уже имеют стратегию использования ИИ или планируют внедрять ИИ, клац. Мечта любого врача получить на стол сразу результаты анализов пациента и предварительный список диагнозов, предлагаемое лечение, чтобы совершить корректировку и назначить успешное лечение. А так ли мы далеки от этого? Какие модели сегодня умеют "понимать" медицинский текст, выдавать предварительный диагноз, выполнять какой-то осмысленный анализ и помогать врачам? Сегодня попробуем прикоснуться к пониманию этого вопроса, похвалить нас рассказать о результатах нашего центра, что конкретно сделал я, и чуть-чуть о наших планах.
Данные - наше всё?
Самое главное для решения большинства supervised (обучение с учителем) ML задач — использование большого количества «хороших» данных. Их использование уже помогает обучению, что было доказано в куче статей, чисто для примера эта (клац). Обычно для серьёзных исследований лаборатории сами собирают дата сеты, вот пример русскоязычных медицинских данных (интернет-посты с мед форума) на hugginface medical_qa_ru_data; в англоязычном сообществе популярен гораздо более полный и основательный поликлинический дата сет MIMIC-III. Однако, в последнее время с развитием отрасли MedTech доступность медицинских данных повышается, улучшается качество ML/DL-моделей. Наиболее популярные англоязычные медицинские дата сеты можно найти, например, здесь ссылка.
MedBench
Некоторые дата сеты стали появляются и для русского языка. Например в рамках одной из таких инициатив был подготовлен ресурс MedBench (Ссылка для ознакомления), включающий четыре типа задач:
RuMedDaNet — измерить способность модели "понимать" медицинский текст и правильно отвечать на уточняющие вопросы.
RuMedNLI — определить тип логической связи между двумя текстами на естественном языке.
RuMedTest — проверка "знаний" модели в рамках специальности "Общая врачебная практика".
ECG2Pathology — оценка качества multilabel-классификации ЭКГ-сигналов.
На момент написания статьи Лидерборд выглядит так:

В сопутствующей этому бенчмарку работе (ссылка на статью) помимо перечисленных задач также представлены дополнительные:
RuMedTop3 — задача прогнозирования диагноза на основании исходного медицинского текста, включающего симптомы и жалобы пациента.
RuMedSymptomRec — учитывая неполный медицинский текст, задача состоит в том, чтобы порекомендовать лучший диагноз для проверки.
RuMedNER — задача распознавания именованных сущностей в отзывах пользователей, связанных с препаратами, лекарствами (классическая задача NLP)
Лидерборд на момент написания статьи выглядел так:

Accuracy базовая метрика для оценки. Для некоторых задач введены дополнительные:
RuMedTop3 and RuMedSymptomRec —
hit@3RuMedNER —
F1-score
Попробуем разобраться, что здесь происходит. Как видно, на тот момент модель RuBioRoBERTa показывает хорошие метрики на RuMedSymptomRec и RuMedNER, Feature-based подход обходит по метрике accuracy, но не hit@3 на задаче RuMedTop3, задачи RuMedDaNet и RuMedNLI остаются за людьми, пока что....
Почему RuBioRoBERTa?
Тут чуть-чуть подробнее об архитектуре, как, что и зачем. С момента появления Трансформеров как архитектуры, а точнее с появления статьи "Attention is all you need" (у которой на сайте paperswithcode.com аж 105 тысяч звёздочек), прошло уже 6 лет. За это время исследователи в области ИИ как только не крутили эту архитектуру, выбрасывали запчасти, добавляли и получили три принципиальные архитектуры: Encoder-Decoder models, Encoder-based models, Decoder-based models. Рассмотрим подробнее Encoder-based модели, куда как раз и относится отец нашего RuBioRoBERTa— BERT. Не хочу сильно перегружать тех, кто не знаком со всем этим зоопарком трансформеров (кто не в теме, вот отличная статья, рекомендую), краткое напоминание: BERT обучается под две задачи — text Classification и Masked Language Modeling (MLM). Тут основной момент в том, что в задаче MLM мы маскируем только определённое количество токенов — 15% и делаем это детерминированно. Попробуем чуть-чуть оптимизировать подбор гиперпараметров, сделаем динамическую маскировку слов и вуаля — RoBERTa. Модель для русского языка — RuRoBERTa была обучена коллегами из отдела NLP R&D SberDevices (ссылка). Уже после этого наши коллеги дообучили эту модель на медицинских текстах и вот она — RuBioRoBERTa.
В чём проблема архитектуры RoBERTa?
Как довольно быстро выяснилось на практике потенциальная проблема такого решения в том, что у BERT и производных от него архитектур детерминированная длина контекста, для классического BERT это 512, а что, если нужно больше? Вот очень красивая схема, на которой видно, что происходит.

Input'ами в архитектуре BERT является сумма Positional embedding (отвечает за позицию слова в контексте), Segment embeddings (какому сегменту принадлежит токен для задачи классификации), Token Embeddings (токенизированные слова). У архитектуры типа BERT positional embedding — обучаемые параметры, следовательно, более 512 токенов наша модель не может обработать за раз, а это может быть критично при обработке длинной истории пациента, или при обработке длинного медицинского текста.
Так что же делать? Попробуем Longformer!
Longformer
Longformer — архитектура и модель, призванные решить проблему ограниченного контекста и как-то его расширить. В основе всё так же лежит архитектура RoBERTa, однако предлагается разделение механизма attention на две части: глобальное и локальное.

В локальном внимании «токен смотрит» на N соседей с каждой стороны, это могут быть как ближайшие соседи, так и взятые с каким-то шагом для увеличения длины покрываемого контекста (но так делается только на верхних слоях, нижние обрабатывают узкий локальный контекст). N растёт линейно с ростом номера слоя. У глобального и локального внимания свои отдельные веса для подсчёта матриц Q-query, K-key и V-value, которые участвуют в расчёте внимания (обычно названия этих матриц не переводят на русский язык). Как видно из графика выше, модель способна обрабатывать более длинный контекст эффективно, а это нам и нужно!
Теперь осталось только посмотреть, что же получится, как долго это обучается, и будет ли лучше?
Имплементация решений
Под каждую задачу бенчмарка я буду дообучать модель longformer. Начнём с общего подхода к обучению. (далее будет достаточно много технических деталей, кому не интересно смотреть на графики — смотрите сразу вывод)
Seed
Сиды для сравнимости результатов будут браться из предыдущих результатов моих коллег, а именно: 3558, 2375, 1906, 1042, 2960, 70, 1785, 3502, 3411, 3527. Метрики будут усредняться, а также будет рассчитываться СКО (средне-квадратичное-отклонение, по-английски — std), чтобы понимать насколько стабильно ведёт себя модель.
Гиперпараметры
epochs = 25, batch_size = 16, lr = 3e-5, оптимизатор — adamw_torch_fused.
Ускорение обучения
Чтобы сделать код более читаемым и универсальным была использована библиотека huggingface и их замечательный Trainer, в котором уже реализованы многие методы ускорения обучения, о которых мы сейчас поговорим.
AdamW vs AdamW_torch_fused более быстрая версия Адама реализованная на torch, чуть легче по параметрам.
Torch_compile нестабильно работающая фича, когда-то может ускорить и уменьшить потребление памяти, когда-то выбрасывает кучу warning'ов.
fp16 vs tf32 отсылаю вас к данной статье на сайте Nvidia link. Вкратце: используем тензорные ядра — специальная архитектура Ampere, позволяющая сократить precision при хранении чисел до 10 bit вместе 23 в стандартном fp32. По скорости уступает fp16, но сходится лучше.
Вот сравнение в виде графиков, которое я провёл для одного из сидов:
Время обучения
График отражает время обучения для одной эпохи, нормированное на default (время обучения с оптимизатором adamw + torch.float32).

Для всех задач формат fp16 и tf32 с оптимизатором adamw_fused показывают хорошие значения по времени, значительно (более чем в 2 раза ускоряя процесс обучения). Следовательно, мы получаем хорошие инструменты для оптимизации скорости, что не может не радовать, а всё ли хорошо с точностью? Всё-таки отбрасывание знаков после запятой не всегда приводит к точным результатам, а это может ухудшить сходимость! В абсолютных значениях, например, для задачи MedTop3 мы получаем уменьшение с 1000 секунд до 417.
Accuracy

А почему мы вообще можем использовать точность (accuracy) ? Это ведь не очень хорошая метрика для задач классификации, а что если классы несбалансированные ? Во-первых, да, метрика на несбалансированных классах не очень репрезентативная, но так как дата сеты сбалансированы по количеству классов, всё ок! Во-вторых для задачи MedNER использовалась также метрика F1-score, которая ведёт себя идентично. В абсолютных значениях, например для задачи Top3 мы имеет уменьшение hit@3 метрики с 62.77 до 1.21 для fp16. Вывод: для формата fp16 точность получается низкой для некоторых задач, иногда же различий с tf32 нет, но мы хотим, чтобы модель вела себя стабильно, поэтому возьмём fp16 на карандаш.
Memory

Видим ожидаемый график: fp16 занимает меньше памяти, чем tf32 и float32, tf32 меньше чем обычный float32, добавить тут особо нечего, это то, чего мы и хотели достичь. Разница получилась не столь огромной для fp16 и fp32 — около 25%, в абсолютных значениях для той же MedTop3 задачи снижение с 29.1 Гб до 24.2 Гб.
Вывод: как можно заметить, самым оптимальным сочетанием является tf32 + adamw_torch_fused, это позволяет заметно прибавить в скорости (сокращение времени в 2 раза), и не потерять в точности по сравнению с оригинальным adamW, fp16 работает нестабильно для некоторых задач, мы не хотим, чтобы наш оптимизатор не сходился в угоду скорости, так что между очень лёгким, но нестабильным и стабильным, но более тяжёлым мы выберем стабильность, tf32 — наш друг. Про torch_compile добавить нечего, вещь нестабильная, надеюсь, в будущем это поправят.
Вперёд к обучению
Предобученный Longformer обучается на Кристофари в течении 3-х месяцев на медицинских текстах (от наших партнёров). В нашем распоряжении были 6 чекпоинтов: 80k шагов, 120k, 180k, 220k, 260k, 300k. Обучение заняло достаточно много времени. Под каждую задачу модель дообучалась отдельно. Из 25 эпох брался чекпоинт модели, который показывал лучшие метрики на валидации. На всех графиках бралось среднее значение + СКО на 10 сидах БЕЗ УЧЁТА ВЫБРОСОВ.
RuMedTop3
В самом начале модель ведёт себя нестабильно и разброс большой — недообучение, однако при дальнейшем обучении мы видим минимум и далее рост, скорее всего где-то здесь и находится максимальная точность.

RuMedSymptomRec
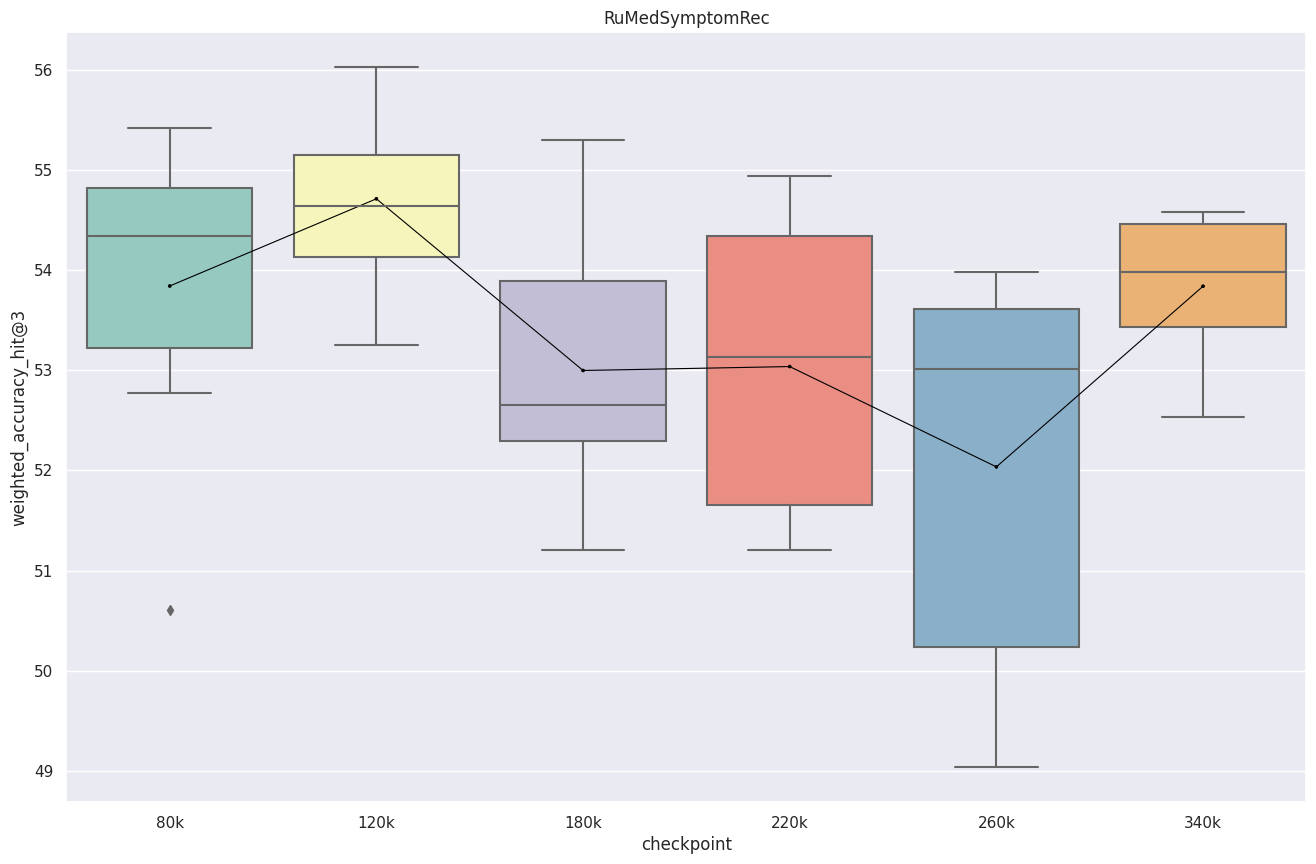
Видно очень нестабильное поведение, на некоторых задачах модель выдаёт очень низкую точность порядка 5-6%, также большие значения СКО не внушают доверия. Чекпоинты 120k и 220k были стабильны на всех 10 сидах.
RuMedDaNet
Тут также заметно очень нестабильное поведение модели, СКО то большое, то маленькое. В начале обучения разброс большой, к чекпоинту 180k точность достигает минимума, а далее растёт.

RuMedNLI
Вот тут интересно, модель сначала показывает большой СКО и низкую точность, дальше точность растёт и СКО падает, отлично, а далее опять растёт, по всем канонам машинного обучения здесь и находится оптимальная глубина обучения.

RuMedNER
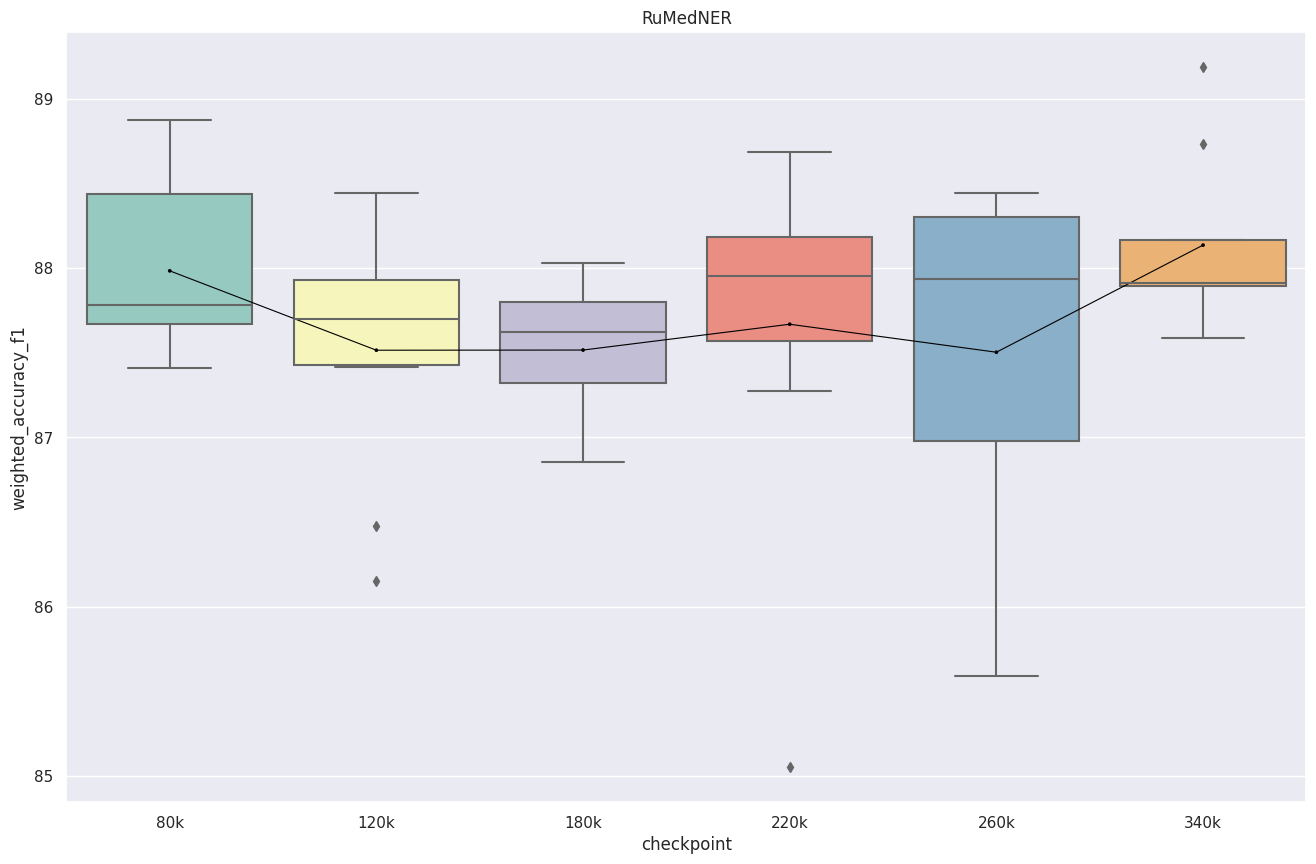
Модель стабильна и мы видим примерно одинаковый результат на всех чекпоинтах, кроме 260k. Модель переобучилась? Далее видим рост метрик.
Overall
Таблица результатов по всем сидам:

Лучшим для Longformer'a оказался чекпоинт 120k шагов. На нём модель показывает себя наиболее стабильно на всех задачах, поэтому в качестве итоговой модели возьмём его. Можно заметить, что на задачах RuMedSymptomRec мы видим значительные улучшения по сравнению с предыдущими результатами! А на задаче RuMedNER F1-score вырос, хотя точность чуть хуже чем у RuBioRoBERTa, интересно…. А почему на задаче RuMedDaNet результат такой плохой?

А что если...
К концу написания статьи хочется подметить один интересный момент, почему на некоторых сидах модель ведёт себя как наивный алгоритм? точность 33% в задаче с тремя классами, хмм... возможно модель недостаточно «прогрелась». Как мы все знаем, влияние warmup'a на сходимость Adam'a особенно критично в архитектурах типа трансформеры. В этот раз мы ещё раз в этом убедились. Ниже представлены boxplot'ы для чекпоинта 80k с warmup_steps = 1000 в тех местах, где оптимизатор решил не сходиться:

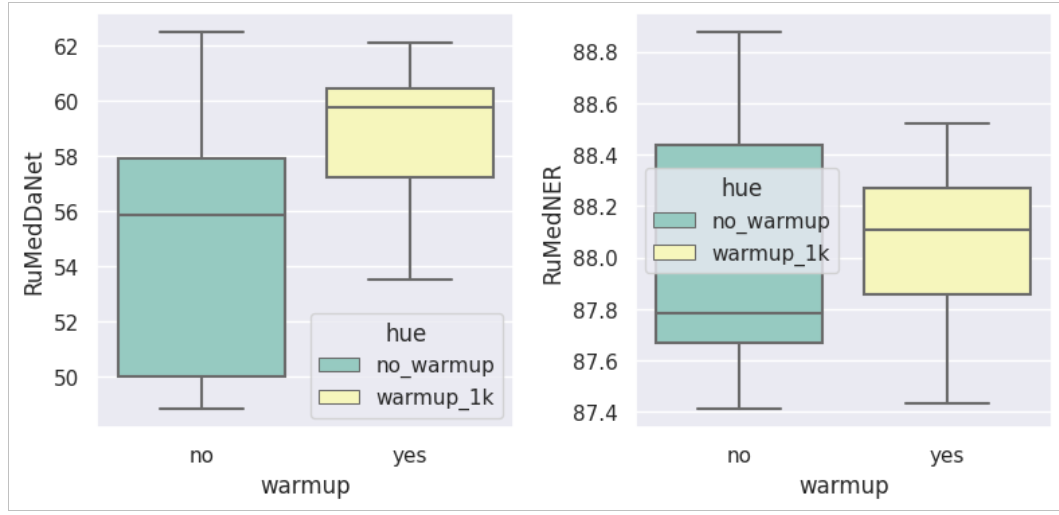

Как можно заметить, даже на сидах, где модель сходится достаточно хорошо, мы видим прирост точности, что не может не радовать. Очевидно, что при увеличении warmup steps необходимо обучать на большем количестве эпох, так как оптимизатор не успевает «сходиться».
Вернёмся к реальности
Эти результаты выглядят конечно хорошо (или нет?), а что эти цифры значат для реальных врачей, терапевтов, больниц? Давайте рассмотрим несколько примеров анамнез пациента и предложенные диагнозы нашей модели из тестового дата сета, который модель не видела при обучении:
RuMedSymptomRec
idx "q6fb3825" : "Жалобы осиплость голоса, повышение температуры до 38 кашель , першение в горле, заложенность носа"
реальный диагноз : "сухой кашель"
3 предсказания модели с наибольшей уверенностью: "насморк", "боль в горле", "озноб"
idx "qb53a600": "Боли в правой лопатки, в правом плечевом суставе, мышцах плеча несколько уменьшились. Период. боли в правом т\бедренном суставе с иррад. в ногу. Утренняя скованность 30 минут."
реальный диагноз : "боль в эпигастрии"
3 предсказания модели с наибольшей уверенностью: "боль в эпигастрии", "сухость во рту", "боль в области лопатки"
idx "q45f6321": "на головные боли давящего характера, усиливающиеся при эмоциональном перенапряжении,"
реальный диагноз : "боль в шее"
3 предсказания модели с наибольшей уверенностью: "тошнота", "головная боль в теменной области", "ощущение дурноты"
Если посмотреть отдельно наhit@3,то для задачи SymptomRec это значение на уровне 62%, что уже станет отличным помощником. Чаще всего среди трёх предсказаний модели будет именно то, что нужно врачу.
RuMedTop3
В этой задаче болезни представлены в МКБ формате.
idx "qaf1454f": "Головную боль, "мелькание мушек перед глазами " на фоне повышения цифр АД до 150\100 мм.рт.ст., учащенное сердцебиение"
реальный диагноз : "I11" — Гипертензивная болезнь сердца [гипертоническая болезнь сердца с преимущественным поражением сердца]
3 предсказания модели с наибольшей уверенностью:
"I11"— Гипертензивная болезнь сердца [гипертоническая болезнь сердца с преимущественным поражением сердца]
"I20" — Стенокардия [грудная жаба]
"I25" — Хроническая ишемическая болезнь сердца
idx "q28fa7aa": "Кашель приступообразный, на протяжении 3-х месяцев, эпизоды дистанционно слышимых хрипов при кашле, отделяется небольшое количество вязкой желтоватой мокроты. Ощущение диспноэ при вдыхании холодного воздуха, не ветре."
реальный диагноз: "J42" — Хронический бронхит не уточненный
3 предсказания модели с наибольшей уверенностью:
"J42"— Хронический бронхит не уточненный
"J45" — Астма с преобладанием астматического компонента
"J84" — Другие интерстициальные легочные болезни
Рассмотрим неудачный пример:
idx "qe64eefb": "Жалобы на сердцебиение приступами, при этом головокружение, в течение 2-3 дня, купируется приемом донормила 1/2 т , с положительным эффектом, учащение мочеиспускания."
реальный диагноз : "J84" — Другие интерстициальные легочные болезни
3 предсказания модели с наибольшей уверенностью:
"I49" — Другие нарушения сердечного ритма
"I11" — Гипертензивная болезнь сердца [гипертоническая болезнь сердца с преимущественным поражением сердца]
"I10" — Эссенциальная (первичная) гипертензия
Видно, что во всех этих случаях модель была близка к пониманию болезни, но истинный диагноз оказался слишком специфичен и сложен для модели.
Если посмотреть отдельно на hit@3 то для задачи RuMedTop3 это значение на уровне 70-75%, что впечатляет! Чаще всего среди трёх предсказаний модели будет именно то, что нужно врачу! А это значит такая модель будет хорошим ассистентом врача, но лишь ассистентом. Мнение врача специалиста критически важно и остаётся решающим.
Итог для врачей!
Модель хорошо справляется с предсказанием диагнозов и выводит их с большой точностью. А там, где модель не угадывает точный диагноз, она даёт очень близкие по классификации болезни. Такое отличное дополнение сможет ускорить время выставления диагнозов для пациентов, сократить время работы врача и в какой-то степени облегчить его работу, оптимизировать процесс работы.
Итог для разработчиков!
Как мы видим, использование Longformer'a позволяет превзойти RuBioRoBERTa почти на всех задачах. Так как задача изначально стояла в сравнении моделей при одних и тех же параметрах, я решил не использовать warmup, так как при обучении RuBioRoBERTa использован warmup не был. Используя warmup и подобрав гиперпараметры — мы получаем новую SOTA модель бенчмарка MedBench.
Будущие идеи
Тут хотелось бы рассказать, что можно попробовать ещё, чтобы улучшить качество модели.
Ещё одним улучшением архитектуры BERT является DeBERTa, которая сочетает в себе плюсы двух других сильных архитектура: RoBERTa и ELECTRA. Хочется протестировать данную модель.
Также хочется протестировать другие улучшения скорости сходимости и обучения по типу sophia(ссылка), LoRA (ссылка).
Подбор гиперпараметов для Longfomer'a и RuBioRoBERTa.
Благодарю тебя, наш читатель, комментарии всегда открыты для тебя.
