Базовый тест Без Delayed durability
Delayed durability включен – Ваши ожидания это ваши проблемы?
Горизонтальное маштабирование наступает и выигрывает
Delayed durability и отложенный санкционный эффект
Кто не рискует, тот не делает бэкап.
В предыдущих частях
Концепция ORM как двигатель прогресса — выдержит ли ее ваша СУБД? / Хабр (habr.com)
Концепция ORM как двигатель прогресса – выявит слабое место Вашей СУБД / Хабр (habr.com)
было показано как неэффективная реализация ORM , порождающая много мелких DML, отражается на производительности СУБД и в особенности на работу Transaction log\Redo log, которые являются узким местом для горизонтального маштабирования.
Вообще горизонтальное маштабирование подразумевает работу с фиксированными наборами данных (пакетами), обработку которых легко распределять по узлам. Это можно эффективно применять даже на платформе 1С как описано тут Язык мой - враг мой. Архитектору о будущем 1С , но текущая архитектура ORM не позволяет развернуться на полную мощность.
Судя по всему, сейчас назревает революционная ситуация когда «низы» (производители СУБД) пытаются исправить проблему, а «верхи» (разработчики ORM) еще не хотят.

Опция Delayed Durability – отложенная транзакция (асинхронная фиксация), есть не только в MS SQL. Термин сложно перевести на русский поэтому лучше читать на английском.
Суть укладывается в одну фразу
«Fully durable transaction commits are synchronous and report a commit as successful and return control to the client only after the log records for the transaction are written to disk. Delayed durable transaction commits are asynchronous and report a commit as successful before the log records for the transaction are written to disk.»
Т.е. это буферизация записи в transaction log – управление программе отдается сразу , ценой которой может быть потеря данных зафиксированной транзакции при сбое. Насколько риск существенен будет описано ниже.
Принцип Работы можно почитать по ссылкам (различаются термины, но суть одна)
Для MS SQL : Тут Control Transaction Durability - SQL Server | Microsoft Learn
Для Oracle : Тут COMMIT_WAIT (oracle.com) . Появился достаточно давно и может устанавливаться на уровне Instance The COMMIT_WRITE parameter | Oracle FAQ (orafaq.com) . Это еще называют асинхронным COMMIT. Термин Durable commit в Oracle применяют к своей In Memory database TimesTen Transaction Management and Recovery (oracle.com)
Для Postgres Тут PostgreSQL: Documentation: 15: 14.5. Non-Durable Settings и Тут PostgreSQL: Documentation: 15: 30.4. Asynchronous Commit , также устанавливается на уровне Instance
Преимущества такого подхода хорошо изложены в документации Oracle in memory DBMS TimesTen (поскольку persistent vs performance для In memory СУБД стоит особенно остро).
«The performance cost for durable commits can be reduced with a group commit of multiple concurrently executing transactions. Many threads executing at the same time, if they are short transactions, may commit at almost the same time. Then, a single disk write commits a group of concurrent transactions durably. Group commit does not improve the response time of any given commit operation, as each durable commit must wait for a disk write to complete, but it can significantly improve the throughput of a series of concurrent transactions.
When durable commits are used frequently, TimesTen can support more connections than there are CPUs, as long as transactions are short. Each connection spends more time waiting to commit than it spends using the CPU. Alternatively, applications that perform infrequent durable commits cause each connection to be very CPU-intensive for the TimesTen portion of its workload.»
Как видно, разработчики СУБД осознают узкое место Transaction log\Redo log в своих решениях и пытаются это исправить. Конечно, в идеале в каждой СУБД хотелось бы иметь аналог Oracle Real application cluster, но пока этот premium доступен не всем. Производительность проверим на той же обработке, что и в предыдущих статьях.
1С 8.3 выбран по следующим причинам
Это ORM с простым интерфейсом для разработчика, но достаточно сложной внутренней организацией.
Это типичный ORM спроектированный для работы не с группой объектов\операций, а с одним объектом\операцией. Java JPA ,например, и многих других такая же ситуация. Как следствие, порождается много DML, ведь при таком подходе трудно их сделать более крупными. А кто нибудь видел «правильный» ORM?
Этот ORM поддерживает 4 СУБД (MS SQL, Oracle, Postgres, IBM DB2) на которую отражается одинаковая структура таблиц. Это позволяет очень удобно сравнивать разные СУБД
Нагрузку легко маштабировать средствами 1С 8.3
В развитии данного ORM заинтересовано большое количество разработчиков из экосистемы 1С, и рано или поздно компания примет меры.
Конфигурация кластера таже что и в первой статье Концепция ORM как двигатель прогресса — выдержит ли ее ваша СУБД? / Хабр (habr.com) - 1С Кластер на отдельном сервере приложений, MS SQL 2019 на сервере СУБД c SSD
Базовый тест Без Delayed durability
Базовый тест запускает обработку c 50 потоками ПЕРЕзаписи , наборов записей в регистре. Т.е. это не просто insert, а еще delete. Причем когда я говорю о записях подразумеваю ORM записи, insert delete в Profiler гораздо больше (раскладка приведена в первой статье)
Сервер базы данных и сервер приложений прежние, с конфигурацией из первой статьи. За это время была обновлена версия операционной системы на более свежую и более свежий релиз 1С 8.3.22.1709

В отличии от предыдущих тестов, сервер приложений 1С немного оптимизирован, отмечены следующие параметры, чтобы дополнительными процессами распределить нагрузку по ядрам и это понадобится при увеличении нагрузки.
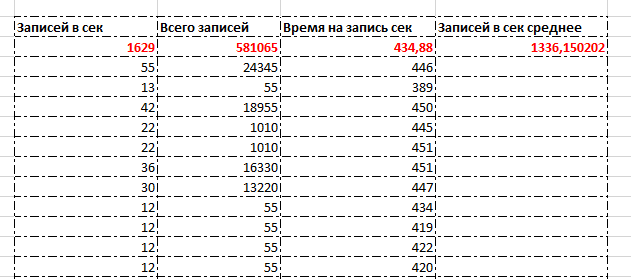
Если посмотреть замеры – они не сильно отличаются от предыдущих тестов, значит ничего существенно не поменялось. Ниже результаты ДО включения Delayed durability

Ниже приведена статистика задержек, обратите внимание – как много занимает Writelog . Это означает что дальнейшее наращивание нагрузки будет затруднительно. Внимательный читатель заметить что в предыдущих тестах с такими же условиями % задержек на логе был еще больше (50%). Возможно это объясняется тем что база была в режиме совместимости c MS SQL 2008R2 хотя и на SQL 2019, либо обновлениями ОС, но на итоговый результат это сильно не повлияло

Delayed durability включен – Ваши ожидания это ваши проблемы?
Теперь включим Delayed durability в базе данных как указано по ссылке , причем не забудем это сделать и в tempdb. Перезапустите кластер 1С чтобы сессии рабочих процессов переконнектились.
Запускаем c 50 фоновыми заданиями … результат 11% прироста. И это все на что он способен?
Смотрим статистику Waits, а там красота – задержки по write log ушли полностью. Такое было видно только когда увеличивали длину транзакции тут в 20 раз Концепция ORM как двигатель прогресса – выявит слабое место Вашей СУБД / Хабр (habr.com) но это чревато дедлоками на практике.

Значит если барьер снят, можно увеличить нагрузку без последствий.
Горизонтальное масштабирование наступает и выигрывает
Здесь я увеличу количество фоновых заданий до 75 , но я делал и 100 . Просто уже при 75 фоновых заданий загрузка сервера приложений выглядит так

И дальше кластер 1C будет просто ставить в очередь фоновые задания.
Что бы равномерно распределить фоновые задания между двумя и более серверами приложений 1С - нужно использовать механизм требований с параметрами как описано тут Назначение конкретных фоновых заданий на конкретный рабочий сервер , это уже более сложный вариант, который нужно запрограммировать.
Итак запускаем 75 фоновых заданий

… результат

2138 vs 1459 объектных записей в секунду , это на 47% больше!
Смотрим задержки

Они растут только на запись в базу, а по логу их НЕТ. Супер значит можно нажать еще в следующих сериях и узнать границу возможного на данном оборудовании.
Внимательный читатель спросит - а сколько будет время у 75 фоновых заданий без delayed durability ? Смотрите ниже формально 1797 т.е. 23% прироста, но при этом wait на writelog уже предельные и дальнейшее увеличение нагрузки просто поставит фоновые задания в очередь и никакого true параллелизма не будет

Далее приведены сравнения замеров для 75 фоновых заданий с Delayed durability и для 50 фоновых БЕЗ Delayed durability для понимания - есть ли узкие места для дальнейшего увеличения нагрузки.
Обратите внимание что Batch request (фиолетовая) линия, стала ровной с Delayed durability и без явных провалов, Disk transfers \sec (синяя) примерно таже, а загрузка процессора (красная ) увеличилась

Без Delayed durability обработка запросов более рваное, даже при меньшей нагрузке с явными провалами

Картинка очередей на SSD (disk queue length - бежевая) не поменялась (здесь график для 75 фоновых заданий) при включенном Delayed durability , так должно и быть – ведь запись в лог и запись в базу это разные подсистемы в SQL

А вот график LogFlush очень интересен
Log Flush waits (фиолетовый) – при включенном Delayed durability исчез. Log Flushes\sec (синий )стал меньше даже при большей нагрузке. Т.е. узкое место исчезло

Без Delayed durability картина более печальна даже на меньшем количеств потоков

Как видите, при использовании горизонтального маштабирования Delayed durability позволяет Вам расширить пределы производительности значительно. Но конечно это не самый лучший вариант о чем поговорим ниже.

Delayed durability и отложенный санкционный эффект
С учетом известных событий, в России придется забыть о новых лицензионных инсталляциях MS SQL Server или Oracle Database. Легальный софт - это не машина которую можно пригнать из дружественной страны. Сейчас даже некоторые уровни RAID у HP требуют ввода спецключей лицензии. Будет ли Postgres полноценным импортозамещением еще предстоит выяснить, но пока правильно делать регулярный image серверов, чтобы не иметь проблем с переустановкой и перегистрацией софта .
Если смотреть стратегически, для серьезных задач , где требуется контроль над системой я вижу 4 варианта (может кто то предложит больше?)
Развивать альтертанивные СУБД открытым кодом, например Postgres .
Вести серый импорт кода, а не софта. Если почитать историю советской ПРО Рождение советской ПРО. Юдицкий строит суперкомпьютер (topwar.ru) , в СССР всегда удавалось делать специализированные машины, на нетрадиционных принципах и эти технологии до сих пор защищают. Но для массового уровня нужна продукция двойного назначения, а это возможно только при госучастии, как делают в США. История советского ИТ https://topwar.ru/user/Sperry/ читается как роман, но даже при поверхностном взгляде видно, что цикл «догнать и перегнать» требует прежде всего социальных изменений (Что не смог сделать СССР) , которые позволят быть эффективными технически. Когда это будет ? - точно не в этом солнечном цикле
Использовать ЦОД и облака в дружественных странах – нормальный вариант для бизнеса, которому проверенные решения нужны уже вчера, но и риски понятны.
Выжать из существующей системы максимум возможного, до наступления светлого будущего.
О последним пункте можно упомянуть поподробнее. Хорошо спроектированная система, с запасом на маштабирование может жить достаточно долго . Просто посмотрите сколько старых систем в США Американский парадокс: почему в США устаревшая IT-инфраструктура, а план Байдена не лишен смысла | Forbes.ru работает до сих пор.
Система спроектированная, под горизонтальное маштабирование Язык мой - враг мой. Архитектору о будущем 1С, может достаточно долго работать за счет добавления новых узлов и это проверено на практике . Однако в случае 1С узким местом будет именно СУБД, и особенно для операций записи.
С чтением все проще – какая бы не была СУБД, за счет репликации можно выделить дополнительные узлы\разгрузить систему для сложной отчетности и подобной работы. С распределением нагрузки по операциями записи такой трюк не пройдет, если не использовать Oracle real application cluster . Поэтому сейчас единственный путь попытаться оптимизировать работу подсистемы транзакционного логгирования, это позволит снять ограничения по маштабированию на время.
Далее два варианта: либо 1С оптимизирует свой код под более крупные DML и границы отодвинутся, либо на горизонте появятся решения альтернативные Oracle real application cluster ведь импортозамещение нужно не только России, но и Китаю , и другим странам которые хотят сохранить технологическую независимость в современных реалиях.
Кто не рискует, тот не делает бэкап
Поскольку отложенная транзакция (асинхронная фиксация) подразумевает возможность потери данных при сбое даже для зафиксированной транзакции – нужно быть готовым к сюрпризам. В официальной документации никто не указывает количество потерянной информации и последствия . Конечно все зависит от нагрузки, конфигурации сервера и т.д.

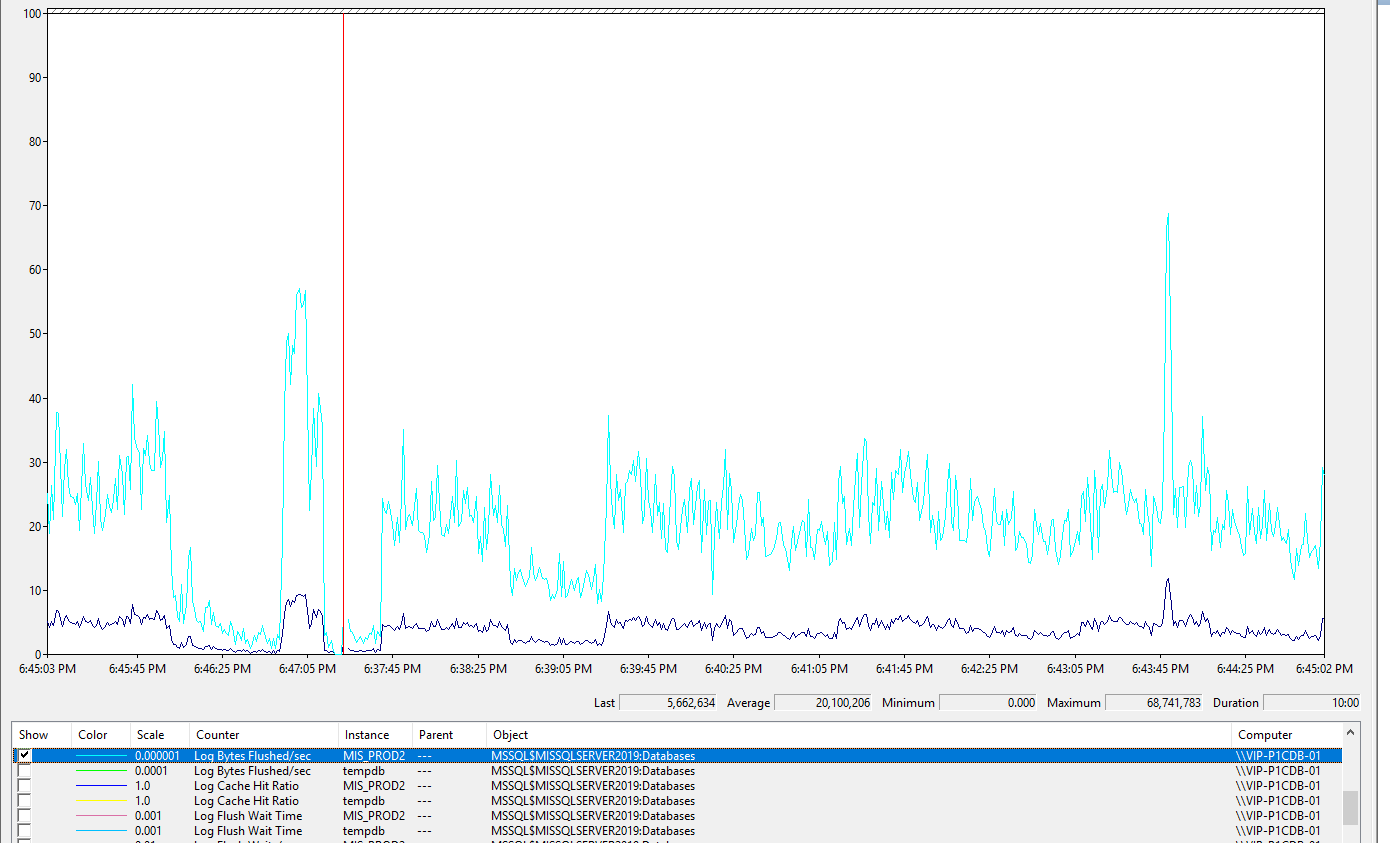
Для нашего теста я могу лишь косвенно оценить . На графике указан количество Log Flash в байт\сек. В среднем где-то 20 мебагайт в секунду.
И есть Log Flashes\сек в среднем 500 в сек. Если поделить, 20МБ/500 =
40кб что близко к размеру Flash block , см
интересную статью IO Block Size for SQL Server, Disk
Block Size - Pure Storage
Т.е. если будет неудачный сбой, и мы потеряем 0.1 секунды это 2 мегабайта. Целостность по ACID в базе данных мы возможно не нарушим, но в ORM 1С есть еще целостность на уровне объектов. Например объект «Документ» часто связан с объектами «Регистрами сведений» или «Регистрами накопления», мы их можем грузить\изменять в разных транзакциях и может случится так, что регистры сведений обновились, а документ не загрузился или не обновился (транзакция формально в Commit,но не попала на диск).
Далее уже варианты:
Если документ не создался для 1С это будет битая ссылка в регистре сведений и перезагрузка документа ее не вылечит, только спец процедура удаления битых ссылок. Для 5 терабайтной базы стандартными методами такие проблемы искать долго.
Если документ не обновился, то будет логическое несоответствие данных в регистрах с документом. Это найти еще труднее.
Таким образом нужно разрабатывать свои процедуры проверки целостности, например маркеры обработанности для группы объектов ORM (что то подобное ACID но для объектов), либо закладываться на обязательное восстановление бэкапа в случае сбоя.
Остановка Instance тоже должна идти особенным образом Правила остановки с Delayed durability.
«For delayed durability, there is no difference between an unexpected shutdown and an expected shutdown/restart of SQL Server. Like catastrophic events, you should plan for data loss. In a planned shutdown/restart, some transactions that have not been written to disk may be saved to disk before shutdown, but you should not plan on it. Plan as though a shutdown/restart, whether planned or unplanned, loses the data the same as a catastrophic event.»
т.е. sp_flush_log обязателен.
Если подвести итоги – Delayed durability имеет смысл включать, когда вы можете увеличивать нагрузку и скорость обработки через горизонтальное маштабирование, высокую степень параллелизма фоновых заданий. Это хорошая практика, которая позволяет жить архитектуре многие годы, даже если сам код не совсем оптимальный. Без этого те 11% прироста за счет простого включения Delayed durability не стоят вероятных потерь данных при сбое и более сложного администрирования. А при горизонтальном маштабировании у Вас есть все возможности сделать прирост более 50%, поскольку узкое место расширяется.
Оптимизация кода ORM на более крупные DML даст прирост больше. Почему я так предполагаю? Во первых отдельные тесты в сети. Во вторых я запускал тест со 100 фоновыми заданиями и там уже видно, что начали появляться SQL Server LOGBUFFER Wait (sqlskills.com) . Очень вероятно ,что на мелких DML уже 2 сервера приложений 1С в текущем кластере, уже создадут проблемы с обработкой DML на сервере СУБД (даже не с записью на диск). Ведь когда DML идет по кэшированному плану, и не рекомпилится - все равно есть накладные расходы на привязку параметров , запуск на исполнение и т.д. Делайте ставки – что первым сдаться на SQL сервере – CPU или предел по IOPS на SSD ? 1C без ограничений на нашем канале t.me/Chat1CUnlimited

