When building any kind of application, it is often seen that a certain functionality is needed again and again at different points. It could be the functionality to display something in a certain way or retrieve data from a source, to name a few examples. Such a common case like this can appear in all kinds of development, be it front-end or back-end. A robust front-end development framework like Angular handles such a case by allowing the development of objects that can be imported by any part as needed. These objects can extract some common logic or data are known as services.
This article helps you understand what Angular services are and what are the different kinds of use-cases they can be used in. Angular services are not limited to one particular type of job and can contain methods that are repeatedly required by different components of the application. Afterward, this article will show what it is like to code service and what makes it accessible to any of the components.
The Gist Of What Angular Services Are
Given how fundamental components are to Angular applications, it is important to briefly go through them to further understand any other concept, like services. Apart from that, components and services are often confused with each other as well. Hence, it is necessary to refresh our understanding of components.
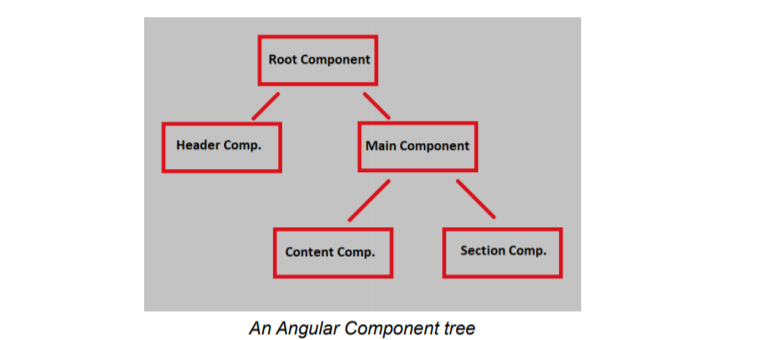
Components are the very backbone of Angular applications. All the different functionalities or visual elements of the application are attributed to a component. Every component contains the working logic for the functionality or visual element and the instructions for its visual rendering. Every Angular application is based on a tree of components. In the component tree, every component working is dependent on or consists of, other component(s).




 -bit counter allows to take into account no more than
-bit counter allows to take into account no more than  events.
events.