
В сентябре прошёл шестой Гипербатон — конференция Яндекса обо всём, что связано с технической документацией. Мы опубликуем несколько лекций с Гипербатона, которые, на наш взгляд, могут быть наиболее интересны читателям Хабра.
Светлана Каюшина, руководитель отдела документирования и локализации:
— Кажется, в мире уже не осталось людей, которые переводят вручную. Сегодня мы хотим поговорить об инструментах и подходах, которые помогают компаниям организовывать эффективный процесс локализации, а переводчикам облегчают решение их повседневных задач. Сегодня мы поговорим о машинном переводе, об оценке эффективности машинных движков и о системах автоматизированного перевода для переводчиков.
Начнем с доклада наших коллег. Приглашаю Ирину Рыбникову и Анастасию Пономарёву — они расскажут об опыте Яндекса по внедрению машинного перевода в наши процессы локализации.
Ирина Рыбникова:
— Спасибо. Мы расскажем про историю машинного перевода и про то, как мы используем его в Яндексе.

Еще в XVII веке ученые размышляли о существовании какого-то языка, который связывает между собой другие языки, и наверное, это слишком давно. Давайте поближе вернемся. Все мы хотим понимать людей вокруг — неважно, куда мы приехали, — мы хотим видеть, что написано на вывесках, мы хотим читать объявления, информацию о концертах. Идея вавилонской рыбки бороздит умы ученых, встречается в литературе, кинематографе — везде. Мы хотим сократить то время, за которое мы получаем доступ к информации. Мы хотим читать статьи о китайских технологиях, понимать любые сайты, которые мы видим, и хотим это получать здесь и сейчас.

В разрезе этого невозможно не говорить про машинный перевод. Это то, что помогает решать указанную задачу.

Отправной точкой считается 1954 год, когда в США на машине IBM 701 было переведено 60 предложений по общей тематике органической химии с русского на английский, и в основе всего этого лежало 250 терминов глоссария и шесть грамматических правил. Это называлось Джорджтаунским экспериментом, и это настолько потрясло реальность, что газеты пестрили заголовками, что еще три-пять лет, и проблема будет полностью решена, все будут счастливы. Но как вы знаете, все пошло немного по-другому.
В 70-е годы появился машинный перевод на основе правил. В его основе тоже лежали двуязычные словари, но и те самые наборы правил, которые помогали описывать любой язык. Любой, но с ограничениями.

Требовались серьезные эксперты-лингвисты, которые прописывали правила. Это достаточно сложная работа, она все равно не могла учесть контекст, полностью покрыть какой бы то ни было язык, но они были экспертам, и высокие вычислительные мощности тогда не требовались.

Если говорить про качество, классический пример — цитата из Библии, которая переводилась тогда так. Пока недостаточно. Поэтому люди продолжали дальше работать над качеством. В 90-е годы возникла статистическая модель перевода, SMT, которая говорила о вероятностном распределении слов, предложений, и эта система принципиально отличалась тем, что она вообще ничего не знала про правила и про лингвистику. Она получала на вход огромное количество идентичных текстов, парных на одном языке и другом, и дальше сама принимала решения. Это было легко поддерживать, не нужны были кучи экспертов, не требовалось ждать. Можно было загружать и получать результат.

Требования к входящим данным были достаточно средние, от 1 до 10 млн сегментов. Сегменты — предложения, небольшие фразы. Но оставались свои трудности и не учитывался контекст, все было не очень легко. И в России, например, появились такие случаи.

Мне еще нравится пример переводов игр GTA, великолепный был результат. Все не стояло на месте. Достаточно важным майлстоуном был 2016 год, когда запустился нейронный машинный перевод. Это было достаточно эпохальное событие, которое сильно перевернуло жизнь. Моя коллега, посмотрев переводы и то, как мы их используем, сказала: «Круто, он говорит моими словами». И это было реально здорово.
Какие особенности? Высокие требования на входе, обучающий материал. Внутри компании это сложно поддерживать, но существенный рост качества — это то, ради чего это затевалось. Только качественный перевод позволит решить поставленные задачи и облегчит жизнь всем участникам процесса, тем же переводчикам, которые не хотят исправлять плохой перевод, они хотят делать новые творческие задачи, а рутинные шаблонные фразы давать машине.
В рамках машинного перевода есть два подхода. Экспертная оценка / лингвистический анализ текстов, то есть проверка реальными лингвистами, экспертами на соответствие смыслу, грамотности языка. В некоторых случаях еще сажали экспертов, давали вычитать переведенный текст и оценивали, насколько это эффективно с этой точки зрения.

Какие особенности этого метода? Не требуется образец перевода, мы смотрим на готовый переведенный текст сейчас и оцениваем объективно по любому разрезу. Но это дорого и долго.

Есть второй подход — автоматические референсные метрики. Их много, у каждой есть плюсы и минусы. Не буду углубляться, про эти ключевые слова потом можно почитать детальнее.
Какая особенность? По факту это сравнение переведенных машинных текстов с каким-то образцовым переводом. Это количественные метрики, которые показывают расхождение между образцовым переводом и тем, что получилось. Это быстро, дешево и можно сделать достаточно удобно. Но есть особенности.

По факту чаще всего сейчас используют гибридные методы. Это когда изначально оценивается что-то автоматически, потом анализируется матрица ошибок, потом на более мелком корпусе текстов проводится экспертный лингвистический анализ.

Последнее время еще распространена практика, когда мы туда не лингвистов зовем, а просто пользователей. Делается интерфейс — покажите, какой вам перевод больше нравится. Или когда вы ходите в онлайн-переводчики, вы вводите текст, и можете часто проголосовать, что вам больше нравится, подходит этот подход или нет. По сути, все мы сейчас обучаем эти движки, и все, что мы им даем на перевод, они используют для обучения и работают над своим качеством.
Хотелось бы рассказать, как мы в работе используем машинный перевод. Передаю слово Анастасии.
Анастасия Пономарёва:
— Мы в Яндексе в отделе локализации поняли достаточно быстро, что возможности у технологии машинного перевода большие, и решили попробовать использовать его в наших ежедневных задачах. С чего мы начали? Мы решили провести небольшой эксперимент. Мы решили перевести одни и те же тексты через обычный нейросетевой переводчик, а также собрать обученный машинный переводчик. Для этого мы подготовили корпуса текстов в паре русский-английский за те годы, что мы в Яндексе занимались локализацией текстов на эти языки. Далее мы пришли с этим корпусом текстов к нашим коллегам из Яндекс.Переводчика и попросили обучить движок.

Когда движок был обучен, мы перевели очередную порцию текстов, и как сказала Ирина, с помощью экспертов оценили полученные результаты. Переводчиков мы просили посмотреть на грамотность, стиль, правописание, передачу смысла. Но самый поворотный момент был, когда один из переводчиков сказал, что «я узнаю свой стиль, узнаю свои переводы».
Чтобы подкрепить эти ощущения, мы решили посчитать уже статистические показатели. Сначала мы посчитали коэффициент BLEU для переводов, сделанных через обычный нейросетевой движок, и получили такую цифру (0,34). Казалось бы, ее надо с чем-то сравнить. Мы снова пошли к коллегам из Яндекс.Переводчика и попросили объяснить, какой коэффициент BLEU считается пороговым для переводов, сделанных реальным человеком. Это от 0,6.
Потом мы решили проверить, какие результаты на обученных переводах. Получили 0,5. Результаты действительно обнадеживающие.

Привожу пример. Это реальная русская фраза из документации Директа. Потом она была переведена через обычный нейросетевой движок, а потом через обученный нейросетевой движок на наших текстах. Уже в первой же строчке мы замечаем, что традиционный для Директа, вид рекламы, не распознан. А уже в обученном нейросетевом движке появляется наш перевод, и даже аббревиатура практически верная.
Мы были очень воодушевлены полученными результатами, и решили, что наверное, стоит использовать машинный движок в других парах, на других текстах, не только на том базовом наборе технической документации. Дальше проводили несколько месяцев ряд экспериментов. Столкнулись с большим количеством особенностей и проблем, это самые частые проблемы, что нам приходилось решать.

Про каждую расскажу подробнее.

Если вы так же, как и мы, соберетесь сделать кастомизированный движок, вам понадобится достаточно большое количество качественных параллельных данных. Большой движок можно обучить на количестве от 10 тыс. предложений, в нашем случае мы подготовили 135 тыс. параллельных предложений.

Не на всех типах текста ваш движок покажет одинаково хорошие результаты. В технической документации, где есть длинные предложения, структура, пользовательская документация и даже в интерфейсе, где есть короткие, но однозначные кнопки, скорее всего, у вас все будет хорошо. Но возможно, как и у нас, вы столкнетесь с проблемами в маркетинге.
Мы проводили эксперимент, переводя плейлисты музыки, и получили такой пример.

Вот что думает машинный переводчик про звездных фабриканток. Что это ударники труда.

При переводе через машинный движок контекст не учитывается. Тут уже не такой смешной пример, а вполне реальный, из технической документации Директа. Казалось бы, тех — понятно, когда ты читаешь техническую документацию, тех — это техническое. Но нет, машинный движок не попал.

Еще придется учитывать, что качество и смысл перевода будет сильно зависеть от языка-оригинала. Переводим фразу на французский с русского, получаем один результат. Получаем похожую фразу с таким же смыслом, но с английского, и получаем другой результат.

Если у вас, как и в нашем тексте, большое количество тегов, разметки, каких-то технических особенностей, скорее всего вам придется их отслеживать, править и писать какие-то скрипты.
Вот примеры реальной фразы из браузера. В круглых скобках техническая информация, которая не должна переводиться, в частности множественные формы. В английском они на английском, и в немецком тоже должны остаться на английском, но они переведены. Вам придется отслеживать эти моменты.

Машинный движок ничего не знает про ваши особенности именования. Например, у нас есть договоренность, что Яндекс.Диск мы везде называем на латинице во всех языках. Но на французском он превращается в диск на французском.
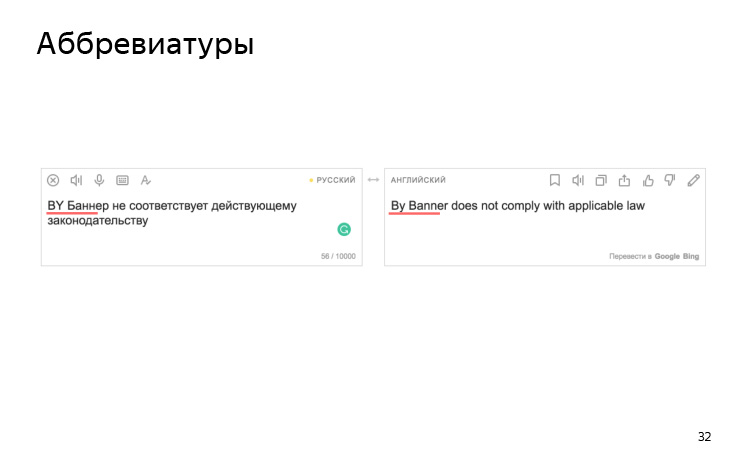
Аббревиатуры иногда распознаются корректно, иногда нет. В данном примере BY, обозначая принадлежность к белорусским техническим требованиям по размещению рекламы, превращается в предлог в английском.

Один из моих любимых примеров — новые и заимствованные слова. Тут классный пример, слово дисклеймер, «исконно русский». Терминологию придется выверять для каждой части текста.
И еще одна, уже не такая значительная проблема — устаревшее написание.
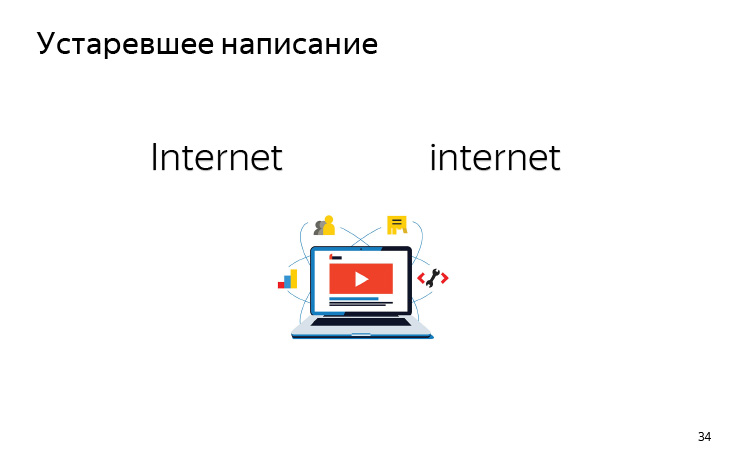
Раньше интернет был новинкой, во всех текстах писался с большой буквы, и когда мы обучали наш движок, везде интернет был с большой буквы. Сейчас новая эра, интернет уже пишем с маленькой буквы. Если вы хотите, чтобы ваш движок продолжал писать интернет с маленькой буквы, вам придется его переобучать.

Мы не отчаивались, решали эти проблемы. Во-первых, меняли корпусы текстов, пробовали на других тематиках переводить. Мы передавали наши замечания коллегам из Яндекс.Переводчика, повторно обучали нейросеть и смотрели на результаты, оценивали, и просили доработать. Например, распознавание тегов, обработку HTML разметки.
Я покажу реальные варианты использования. У нас хорошо идет машинный перевод для технической документации. Это реальный кейс.

Вот фраза на английском и на русском. Переводчик, который занимался этой документацией, был очень воодушевлен адекватным выбором терминологии. Еще пример.

Переводчик оценил выбор is вместо тире, что тут поменялась структура фразы на английскую, адекватный выбор термина, которая является верным, и слово you, которого нет в оригинале, но он делает этот перевод именно английским, естественным.

Еще один кейс — переводы интерфейсов на лету. Один из сервисов решил не заморачиваться с локализацией и переводить тексты прямо во время загрузки. Но после изменения движка примерно раз в месяц слово «доставка» менялось по кругу. Мы предложили команде подключить не обычный нейросетевой движок, а наш, обученный на технической документации, чтобы использовался всегда один и тот же термин, согласованный с командой, который уже есть в документации.
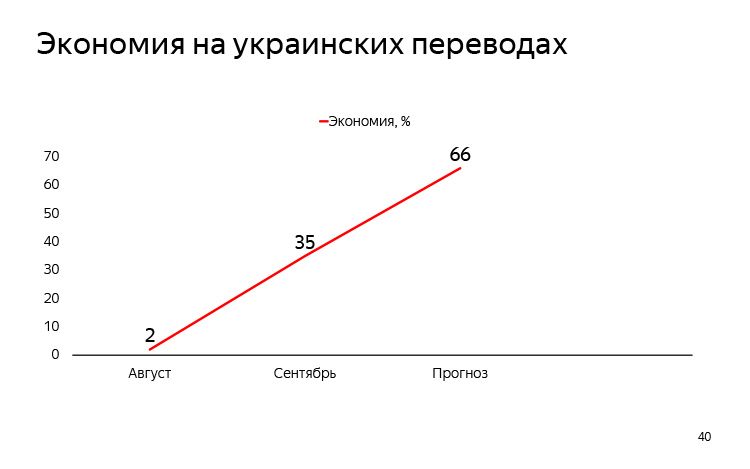
Как это все действует на денежный момент? Исконно так сложилось, что в паре русский-украинский требуется минимальная редактура украинского перевода. Поэтому мы пару месяцев назад решили перейти на систему постэдитинга. Вот как растет наша экономия. Сентябрь еще не закончился, но мы прикинули, что мы сократили наши затраты на постэдитинг приблизительно на треть на украинском, и дальше собираемся редактировать практически все, кроме маркетинговых текстов. Слово Ирине для подведения итогов.
Ирина:
— Для всех становится очевидным, что пользоваться этим надо, это уже является нашей реальностью, и исключать это из своих процессов и интересов нельзя. Но нужно подумать о нескольких вещах.

Определитесь с тем типов документов, контекста, с которым вы работаете. Подходит ли эта технология конкретно для вас?
Второй момент. Мы разговаривали про Яндекс.Переводчик, потому что мы в хороших отношениях, у нас прямой доступ к разработчикам и так далее, но по факту вам нужно определиться — какой из движков будет наиболее оптимальным для вас конкретно, для вашего языка, вашей тематики. Этой теме будет посвящен следующий доклад. Будьте готовы, что пока еще есть трудности, разработчики движков все вместе работают над решением трудностей, но пока они еще встречаются.

Хотелось бы понять, что нас ждет в дальнейшем. Но по факту, это уже не дальнейшее, а наше нынешнее время, то, что происходит здесь и сейчас. Нам всем скорее нужна кастомизация под нашу терминологию, под наши тексты, и это то, что сейчас становится публичным. Теперь все работают над тем, чтобы вы не ходили внутрь компании, не договаривались с разработчиками конкретного движка, как бы это оптимизировать под вас. Вы сможете это получать в публичных открытых движках по API.
Кастомизация идет не только по текстам, но и по терминологии, по настройке терминологии под ваши собственные нужны. Это достаточно важный момент. Вторая тема — интерактивный перевод. Когда переводчик переводит текст, технология позволяет ему предсказывать следующие слова с учетом исходного языка, исходного текста. Это оже существенно может облегчать работу.
О том, что сейчас действительно дорого. Все думают, как меньшими объемами текста обучить какие-то движки гораздо более эффективно. Это то, что происходит везде и запускается повсеместно. Думаю, тема очень интересная, а дальше будет еще интереснее.
Мы собрали несколько статей, которые могут заинтересовать вас. Спасибо!
— Две модели лучше одной. Опыт Яндекс.Переводчика
— Как Яндекс применил технологии искусственного интеллекта для перевода веб-страниц
— Машинный перевод. От холодной войны до диплернинга
Светлана Каюшина, руководитель отдела документирования и локализации:
— Кажется, в мире уже не осталось людей, которые переводят вручную. Сегодня мы хотим поговорить об инструментах и подходах, которые помогают компаниям организовывать эффективный процесс локализации, а переводчикам облегчают решение их повседневных задач. Сегодня мы поговорим о машинном переводе, об оценке эффективности машинных движков и о системах автоматизированного перевода для переводчиков.
Начнем с доклада наших коллег. Приглашаю Ирину Рыбникову и Анастасию Пономарёву — они расскажут об опыте Яндекса по внедрению машинного перевода в наши процессы локализации.
Ирина Рыбникова:
— Спасибо. Мы расскажем про историю машинного перевода и про то, как мы используем его в Яндексе.

Еще в XVII веке ученые размышляли о существовании какого-то языка, который связывает между собой другие языки, и наверное, это слишком давно. Давайте поближе вернемся. Все мы хотим понимать людей вокруг — неважно, куда мы приехали, — мы хотим видеть, что написано на вывесках, мы хотим читать объявления, информацию о концертах. Идея вавилонской рыбки бороздит умы ученых, встречается в литературе, кинематографе — везде. Мы хотим сократить то время, за которое мы получаем доступ к информации. Мы хотим читать статьи о китайских технологиях, понимать любые сайты, которые мы видим, и хотим это получать здесь и сейчас.

В разрезе этого невозможно не говорить про машинный перевод. Это то, что помогает решать указанную задачу.

Отправной точкой считается 1954 год, когда в США на машине IBM 701 было переведено 60 предложений по общей тематике органической химии с русского на английский, и в основе всего этого лежало 250 терминов глоссария и шесть грамматических правил. Это называлось Джорджтаунским экспериментом, и это настолько потрясло реальность, что газеты пестрили заголовками, что еще три-пять лет, и проблема будет полностью решена, все будут счастливы. Но как вы знаете, все пошло немного по-другому.
В 70-е годы появился машинный перевод на основе правил. В его основе тоже лежали двуязычные словари, но и те самые наборы правил, которые помогали описывать любой язык. Любой, но с ограничениями.

Требовались серьезные эксперты-лингвисты, которые прописывали правила. Это достаточно сложная работа, она все равно не могла учесть контекст, полностью покрыть какой бы то ни было язык, но они были экспертам, и высокие вычислительные мощности тогда не требовались.

Если говорить про качество, классический пример — цитата из Библии, которая переводилась тогда так. Пока недостаточно. Поэтому люди продолжали дальше работать над качеством. В 90-е годы возникла статистическая модель перевода, SMT, которая говорила о вероятностном распределении слов, предложений, и эта система принципиально отличалась тем, что она вообще ничего не знала про правила и про лингвистику. Она получала на вход огромное количество идентичных текстов, парных на одном языке и другом, и дальше сама принимала решения. Это было легко поддерживать, не нужны были кучи экспертов, не требовалось ждать. Можно было загружать и получать результат.

Требования к входящим данным были достаточно средние, от 1 до 10 млн сегментов. Сегменты — предложения, небольшие фразы. Но оставались свои трудности и не учитывался контекст, все было не очень легко. И в России, например, появились такие случаи.

Мне еще нравится пример переводов игр GTA, великолепный был результат. Все не стояло на месте. Достаточно важным майлстоуном был 2016 год, когда запустился нейронный машинный перевод. Это было достаточно эпохальное событие, которое сильно перевернуло жизнь. Моя коллега, посмотрев переводы и то, как мы их используем, сказала: «Круто, он говорит моими словами». И это было реально здорово.
Какие особенности? Высокие требования на входе, обучающий материал. Внутри компании это сложно поддерживать, но существенный рост качества — это то, ради чего это затевалось. Только качественный перевод позволит решить поставленные задачи и облегчит жизнь всем участникам процесса, тем же переводчикам, которые не хотят исправлять плохой перевод, они хотят делать новые творческие задачи, а рутинные шаблонные фразы давать машине.
В рамках машинного перевода есть два подхода. Экспертная оценка / лингвистический анализ текстов, то есть проверка реальными лингвистами, экспертами на соответствие смыслу, грамотности языка. В некоторых случаях еще сажали экспертов, давали вычитать переведенный текст и оценивали, насколько это эффективно с этой точки зрения.

Какие особенности этого метода? Не требуется образец перевода, мы смотрим на готовый переведенный текст сейчас и оцениваем объективно по любому разрезу. Но это дорого и долго.

Есть второй подход — автоматические референсные метрики. Их много, у каждой есть плюсы и минусы. Не буду углубляться, про эти ключевые слова потом можно почитать детальнее.
Какая особенность? По факту это сравнение переведенных машинных текстов с каким-то образцовым переводом. Это количественные метрики, которые показывают расхождение между образцовым переводом и тем, что получилось. Это быстро, дешево и можно сделать достаточно удобно. Но есть особенности.

По факту чаще всего сейчас используют гибридные методы. Это когда изначально оценивается что-то автоматически, потом анализируется матрица ошибок, потом на более мелком корпусе текстов проводится экспертный лингвистический анализ.

Последнее время еще распространена практика, когда мы туда не лингвистов зовем, а просто пользователей. Делается интерфейс — покажите, какой вам перевод больше нравится. Или когда вы ходите в онлайн-переводчики, вы вводите текст, и можете часто проголосовать, что вам больше нравится, подходит этот подход или нет. По сути, все мы сейчас обучаем эти движки, и все, что мы им даем на перевод, они используют для обучения и работают над своим качеством.
Хотелось бы рассказать, как мы в работе используем машинный перевод. Передаю слово Анастасии.
Анастасия Пономарёва:
— Мы в Яндексе в отделе локализации поняли достаточно быстро, что возможности у технологии машинного перевода большие, и решили попробовать использовать его в наших ежедневных задачах. С чего мы начали? Мы решили провести небольшой эксперимент. Мы решили перевести одни и те же тексты через обычный нейросетевой переводчик, а также собрать обученный машинный переводчик. Для этого мы подготовили корпуса текстов в паре русский-английский за те годы, что мы в Яндексе занимались локализацией текстов на эти языки. Далее мы пришли с этим корпусом текстов к нашим коллегам из Яндекс.Переводчика и попросили обучить движок.

Когда движок был обучен, мы перевели очередную порцию текстов, и как сказала Ирина, с помощью экспертов оценили полученные результаты. Переводчиков мы просили посмотреть на грамотность, стиль, правописание, передачу смысла. Но самый поворотный момент был, когда один из переводчиков сказал, что «я узнаю свой стиль, узнаю свои переводы».
Чтобы подкрепить эти ощущения, мы решили посчитать уже статистические показатели. Сначала мы посчитали коэффициент BLEU для переводов, сделанных через обычный нейросетевой движок, и получили такую цифру (0,34). Казалось бы, ее надо с чем-то сравнить. Мы снова пошли к коллегам из Яндекс.Переводчика и попросили объяснить, какой коэффициент BLEU считается пороговым для переводов, сделанных реальным человеком. Это от 0,6.
Потом мы решили проверить, какие результаты на обученных переводах. Получили 0,5. Результаты действительно обнадеживающие.

Привожу пример. Это реальная русская фраза из документации Директа. Потом она была переведена через обычный нейросетевой движок, а потом через обученный нейросетевой движок на наших текстах. Уже в первой же строчке мы замечаем, что традиционный для Директа, вид рекламы, не распознан. А уже в обученном нейросетевом движке появляется наш перевод, и даже аббревиатура практически верная.
Мы были очень воодушевлены полученными результатами, и решили, что наверное, стоит использовать машинный движок в других парах, на других текстах, не только на том базовом наборе технической документации. Дальше проводили несколько месяцев ряд экспериментов. Столкнулись с большим количеством особенностей и проблем, это самые частые проблемы, что нам приходилось решать.

Про каждую расскажу подробнее.

Если вы так же, как и мы, соберетесь сделать кастомизированный движок, вам понадобится достаточно большое количество качественных параллельных данных. Большой движок можно обучить на количестве от 10 тыс. предложений, в нашем случае мы подготовили 135 тыс. параллельных предложений.

Не на всех типах текста ваш движок покажет одинаково хорошие результаты. В технической документации, где есть длинные предложения, структура, пользовательская документация и даже в интерфейсе, где есть короткие, но однозначные кнопки, скорее всего, у вас все будет хорошо. Но возможно, как и у нас, вы столкнетесь с проблемами в маркетинге.
Мы проводили эксперимент, переводя плейлисты музыки, и получили такой пример.

Вот что думает машинный переводчик про звездных фабриканток. Что это ударники труда.

При переводе через машинный движок контекст не учитывается. Тут уже не такой смешной пример, а вполне реальный, из технической документации Директа. Казалось бы, тех — понятно, когда ты читаешь техническую документацию, тех — это техническое. Но нет, машинный движок не попал.

Еще придется учитывать, что качество и смысл перевода будет сильно зависеть от языка-оригинала. Переводим фразу на французский с русского, получаем один результат. Получаем похожую фразу с таким же смыслом, но с английского, и получаем другой результат.

Если у вас, как и в нашем тексте, большое количество тегов, разметки, каких-то технических особенностей, скорее всего вам придется их отслеживать, править и писать какие-то скрипты.
Вот примеры реальной фразы из браузера. В круглых скобках техническая информация, которая не должна переводиться, в частности множественные формы. В английском они на английском, и в немецком тоже должны остаться на английском, но они переведены. Вам придется отслеживать эти моменты.
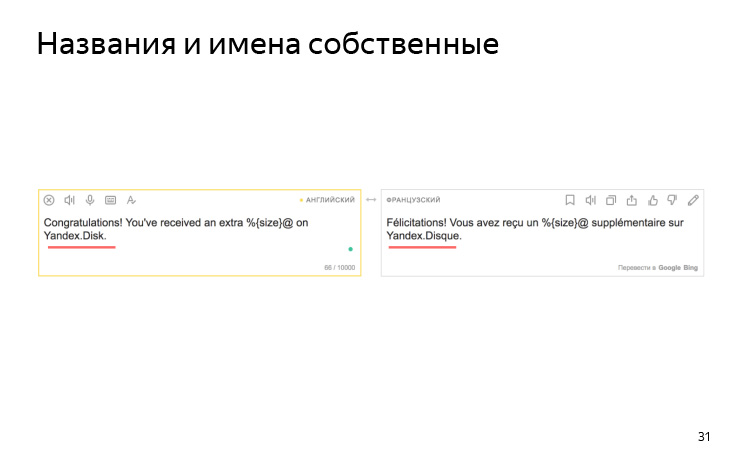
Машинный движок ничего не знает про ваши особенности именования. Например, у нас есть договоренность, что Яндекс.Диск мы везде называем на латинице во всех языках. Но на французском он превращается в диск на французском.

Аббревиатуры иногда распознаются корректно, иногда нет. В данном примере BY, обозначая принадлежность к белорусским техническим требованиям по размещению рекламы, превращается в предлог в английском.

Один из моих любимых примеров — новые и заимствованные слова. Тут классный пример, слово дисклеймер, «исконно русский». Терминологию придется выверять для каждой части текста.
И еще одна, уже не такая значительная проблема — устаревшее написание.

Раньше интернет был новинкой, во всех текстах писался с большой буквы, и когда мы обучали наш движок, везде интернет был с большой буквы. Сейчас новая эра, интернет уже пишем с маленькой буквы. Если вы хотите, чтобы ваш движок продолжал писать интернет с маленькой буквы, вам придется его переобучать.

Мы не отчаивались, решали эти проблемы. Во-первых, меняли корпусы текстов, пробовали на других тематиках переводить. Мы передавали наши замечания коллегам из Яндекс.Переводчика, повторно обучали нейросеть и смотрели на результаты, оценивали, и просили доработать. Например, распознавание тегов, обработку HTML разметки.
Я покажу реальные варианты использования. У нас хорошо идет машинный перевод для технической документации. Это реальный кейс.

Вот фраза на английском и на русском. Переводчик, который занимался этой документацией, был очень воодушевлен адекватным выбором терминологии. Еще пример.

Переводчик оценил выбор is вместо тире, что тут поменялась структура фразы на английскую, адекватный выбор термина, которая является верным, и слово you, которого нет в оригинале, но он делает этот перевод именно английским, естественным.

Еще один кейс — переводы интерфейсов на лету. Один из сервисов решил не заморачиваться с локализацией и переводить тексты прямо во время загрузки. Но после изменения движка примерно раз в месяц слово «доставка» менялось по кругу. Мы предложили команде подключить не обычный нейросетевой движок, а наш, обученный на технической документации, чтобы использовался всегда один и тот же термин, согласованный с командой, который уже есть в документации.

Как это все действует на денежный момент? Исконно так сложилось, что в паре русский-украинский требуется минимальная редактура украинского перевода. Поэтому мы пару месяцев назад решили перейти на систему постэдитинга. Вот как растет наша экономия. Сентябрь еще не закончился, но мы прикинули, что мы сократили наши затраты на постэдитинг приблизительно на треть на украинском, и дальше собираемся редактировать практически все, кроме маркетинговых текстов. Слово Ирине для подведения итогов.
Ирина:
— Для всех становится очевидным, что пользоваться этим надо, это уже является нашей реальностью, и исключать это из своих процессов и интересов нельзя. Но нужно подумать о нескольких вещах.

Определитесь с тем типов документов, контекста, с которым вы работаете. Подходит ли эта технология конкретно для вас?
Второй момент. Мы разговаривали про Яндекс.Переводчик, потому что мы в хороших отношениях, у нас прямой доступ к разработчикам и так далее, но по факту вам нужно определиться — какой из движков будет наиболее оптимальным для вас конкретно, для вашего языка, вашей тематики. Этой теме будет посвящен следующий доклад. Будьте готовы, что пока еще есть трудности, разработчики движков все вместе работают над решением трудностей, но пока они еще встречаются.

Хотелось бы понять, что нас ждет в дальнейшем. Но по факту, это уже не дальнейшее, а наше нынешнее время, то, что происходит здесь и сейчас. Нам всем скорее нужна кастомизация под нашу терминологию, под наши тексты, и это то, что сейчас становится публичным. Теперь все работают над тем, чтобы вы не ходили внутрь компании, не договаривались с разработчиками конкретного движка, как бы это оптимизировать под вас. Вы сможете это получать в публичных открытых движках по API.
Кастомизация идет не только по текстам, но и по терминологии, по настройке терминологии под ваши собственные нужны. Это достаточно важный момент. Вторая тема — интерактивный перевод. Когда переводчик переводит текст, технология позволяет ему предсказывать следующие слова с учетом исходного языка, исходного текста. Это оже существенно может облегчать работу.
О том, что сейчас действительно дорого. Все думают, как меньшими объемами текста обучить какие-то движки гораздо более эффективно. Это то, что происходит везде и запускается повсеместно. Думаю, тема очень интересная, а дальше будет еще интереснее.
Мы собрали несколько статей, которые могут заинтересовать вас. Спасибо!
— Две модели лучше одной. Опыт Яндекс.Переводчика
— Как Яндекс применил технологии искусственного интеллекта для перевода веб-страниц
— Машинный перевод. От холодной войны до диплернинга
