Comments 74
Отличная статья!
Похоже, что это перевод этой публикации https://blogs.msdn.microsoft.com/dotnet/2017/07/24/get-started-with-f-as-a-c-developer/
В результате F# и его преимущества становятся понятными и прозрачными!
F# превосходно подходит для описания доменной модели благодаря Discriminated Unions.
Такой код даже выглядит более человекочитаемым для непрограммистов.
На текущем месте работы я придерживаюсь такой схемы:
- ядро, которое не ссылается на другие проекты — на F#. Вся логика, валидация, бизнес-кейсы и преобразования тут.
- инфрастукрура и вся прочая обвязка (ASP.Net, Entity Framework, Akka.Net, работа с очередями) — на C#.
Инфраструктуру проще на C# потому что:
- F# пока что не поддерживает .Net Core
- Ошибки и изменения в инфраструктуре случаются чаще, поэтому бОльшая часть разработчиков сможет исправить эту часть солюшна.
Писать на F# это не элитизм ни разу. Пишется быстрее и ошибок в логике меньше. Рекомендую попробовать.
Сейчас писать код под .Net Core можно в VSCode c плагином Ionide, а в .NET Core CLI есть шаблоны F# проектов.
F# пока что не поддерживает .Net Core
Это утверждение не совсем точное: на самом деле F# поддерживает .NET Core (и вы можете в консоли создать и скомпилировать такой проект), а вот с инструментами (кроме Ionide) пока что не очень.
- VSCode + Ionide в таком режиме работают отлично
- Visual Studio пока не поддерживает, но обещали сделать в Update 3
- Rider пока не поддерживает, но обещали сделать в одном из обновлений версии 2017 (т.е. в этом году)
- про VS for Mac, к сожалению, не знаю
В общем, хочется верить, что это временное явление, и в будущем основные IDE будут поддерживать всё как положено.
По описанию звучит похоже на лекции Брагилевского, посмотреть можно на тытрубе.
Тут уже дали ссылку на них же на youtube.
Я думаю, что понимаю, о чём вы говорите, и поддержки такого уровня для F# пока что нет. Некий потенциал для такой поддержки на самом деле видится (как минимум, можно было бы заставить редактор генерировать ветки для pattern matching), но Idris всё-таки даёт для таких вещей намного больше возможностей благодаря куда более продвинутой системе типов.
- А почему акка не на F#?
- Как преобразуете persistent-типы (EF) к доменным типам для передачи в F# BL?
упс, не сразу понял, что вопрос относится к посту уровнем выше, удалил комментарий
1) Да там смешение по большей части. Инфраструктуру с большим кол-вом мутабельного кода (кеши, стейты, вот это вот всё) проще на C#.
Очень много либ для Akka.Net написано не в функциональном стиле, поэтому для использования в F# какого-нибудь PersistentActor приходится огород городить. Ну а чтобы явно не смешивать два языка для одного фреймворка я просто пишу Akka код на C#, который уже лезет в бизнесовые объекты, сервисы etc в проект, написанный на F#.
2) Бьёте по-больному) Да, для перехода из C# в F# (и наоборот) приходится писать немного мапперов, т.к. Nullable в чистом F# надо заменять на option, например. И не пропускать null внутрь домена вообще.
А в остальном, RecordType из проекта F# в проекте на C# выглядят как класс с конструктором и понятными типами. Если надо хранить его в SQL, то для EF в любом случае надо лепить инфраструктурный класс с описанием индексов и пр. Я не сторонник смешивать доменные модели, DTO и модели для хранения.
Конкретно меня интересуют два вопроса — как легко (то есть без установки IDE) писать свои модули к PowerShell, и можно ли использовать F# для AWS Lambda (сейчас для этого использую Scala, но приходится бороться с очень большим ростом размера бинарника — не получится ли то же самое с F# вместо C#)?
как легко (то есть без установки IDE) писать свои модули к PowerShell
Здесь принцип одинаков как для C#, так и для F#: нужны будут
- сборки от целевой версии PowerShell (Windows PowerShell хранит их в GAC, а для PowerShell Core можно всё скачать из NuGet)
- инструменты для сборки модулей (для Windows PowerShell, вероятно, понадобятся MSBuild и standalone-компилятор, которые можно попробовать установить без IDE вместе с VS Build Tools; для .NET Standard всё проще, потому что ставится из NuGet)
Я бы вам советовал самостоятельно попробовать написать простенький модуль на C#, а потом этот же опыт применить для разработки на F#.
Насколько я понимаю, сегодня есть рекомендация писать портабельные модули на .NET Standard, и их можно будет использовать и для старого, и для нового PowerShell. Это сильно упрощает задачу «писать модули без установки IDE», причём без привязки к языку.
Вот ещё нагуглился какой-то небольшой пост, который описывает опыт разработки модуля с .NET Core (без IDE). Опять же, повторюсь, история с F# принципиально не отличается; F# официально поддерживает .NET Core уже в течение некоторого времени.
Какой может быть мотивация написать следующий проект именно на F# (Lisp, Haskell, %your_option%), а не на C#?
F# — это инструмент, а не религия. Как инструмент он больше подходит для определённого круга задач.
Для меня этот круг задач выглядит так:
- многопоточная молотилка данных
- доменные модели, ядро
- веб-сервис вида Pipeline (получил инпут, отдал аутпут)
- скрипты (билд скрипты для FAKE, Azure Functions и т.д.)
Мотивация в том, что F# умеет решать задачи из круга выше проще, быстрее и лучше.
Почему быстрее и лучше могу написать в отдельном посте.
Почему быстрее и лучше могу написать в отдельном посте.
Было бы интересно послушать. Напишите, пожалуйста :)
Каждый пункт из моего списка выполняется на F# проще из-за комбинации языковых фич F#, которые я перечислю ниже.
1) Type Inference + Automatic Generalization.
Поясню для C# разработчиков. У вас есть var, который позволяет "наследовать" (или правильнее сказать "вывести") тип для переменной слева из выражения справа. Представим что можно использовать var не только в выражениях объявления переменной, но и для объявления сигнатур функций.
При этом var != dynamic, т.е. мы не теряем сильную типизацию, мы просто говорим — пусть у функции будет такой выходной тип, который получается из тела функции. А входные параметры будут такого минимально необходимого типа, который требуется чтобы выполнить тело функции.
Подобное есть в C# в лямбдах, где можно написать (x => 1), где можно не указывать ни тип x (он будет унаследован из контекста применения лямбды), ни тип возврата (цифра 1 означает что возвращаемый тип int или его потомок). Но до размаха наследования типов и генерализации C# отстаёт на годы.
В F# можно писать функции без бойлерплейта в сигнатурах, типы за вас выведет компилятор. В начале они будут любыми дженериками, а затем он сам наложит констрейны на аргументы и выведет более чёткий интерфейс, тип или ограничения на операторы (дада, в F# можно наложить констрейн на возможность складывать).
2) Immutable Types + Record Types
Для начала попробуйте создать по-настоящему Immutable type в C#. Многие скажут что достаточно сделать один конструктор и кучу полей с приватными сеттерами. И рано или поздно попадутся на этом, т.к. ImmutableArray не является неизменяемым как только я получаю ссылку на объект MutableClass и начинаю его изменять как мне вздумается.
F# гарантирует трудности при написании такого кода :)
Зачем нужны Immutable типы, я думаю рассказывать не надо.
Так же, я уверен многие делали value object типы в C#, которые сравниваются по значению, а так же являются неизменяемыми. Да, решарпер берёт часть бойлерплейта на себя в виде переопределения GetHashCode, Equals и т.д. но каждый такой тип надо выделять в отдельный файл из-за безумного кол-ва бесполезного кода в нём.
Record Type в F# решает все эти проблемы разом и далее программист думает только о правильном создании доменной модели, а не о правильном переопределении GetHashCode
3) Создание DSL
F# умеет создавать инлайн операторы на лету для более выразительного кода.
let (>>=) f g x = {залогировать вызов и скомбинировать вызов функций}
пример (очень даже реальный:
getData >>= validate >>= transform >>= publish
А так же новые паттерны для паттерн матчинга:
match x with
| North ->…
| South ->…
etc
А так же свои монадные преобразования с помощью workflow синтаксиса.
maybe {
let! a = doDangerousOp1()
let! b = doDangerousOp2(a)
let! c = doDangerousOp2(b)
}
примерный смысл написанного выше — на каждом шаге операции оборачивать результат выражений в Maybe (это монада вида что-то есть или чего-то нет) и проверять, если в результате уже ничего нет, то ничего не делать. На выходе вернётся развёрнутая монада. Описывать сколько ж надо кода на c# написать для похожего функционала — страшно. Есть готовые библиотеки, но создание подобных монад в f# упрощено из-за встроенного в язык workflowBuilder. Собственно async или seq в F# — это и есть те самые workflow.
4) Dicriminated Union + Tuples
Широко применяемая фича языка — это DU. Это очень прокачанные enum из C#, которые могут иметь разные типы (а не только int), включать сами себя, быть generic и т.д.
Как правило именно они используются для описания работы приложения через описания возможных состояний, правил перехода, вида входных параметров и т.д. Комппилятор всегда подскажет что вы сделали не так с DU (например не рассмотрели все случаи), поэтому ошибится в логике сразу становится намного сложнее.
Про кортежи подробно рассказывать не буду. Просто скажу что в F# их применение выглядит естественно (в основном благодаря type inference) и поэтому используются повсеместо.
Можно описывать ещё кучу фич типа разнообразного кол-ва паттеров в паттерн матчинге, typeProviders (дают статическую типизацию к динамическому внешнему контенту) но лучще сразу перейду к основному.
Почему многопоточная молотилка?
- иммутабельность
- меньше бойлерплейта с value type
Почему доменные модели, ядро?
- DU описывают все возможные состояния системы. Сделать её неконсистентной при использовании DU — крайне сложно
- легко написать свой DSL с помощью своих операторов, монад и пр. вот пример:
let example =
trade {
buy 100 "IBM" Shares At Max 45
sell 40 "Sun" Shares At Min 24
buy 25 "CISCO" Shares At Max 56
}
Почему веб-сервисы вида pipeline?
- функциональные преобразования проще, т.к. меньше бойлерплейта, можно композировать функции, частично их применять, кода меньше.
- typeProviders позволяют быстро и без ошибок писать хоть SQL код, хоть обращаться к CSV, сохраняя типы и проверяя всё во время компиляции
Почему скрипты?
- Опять таки из-за легкого написания DSL получается человекочитаемый код даже для непосвящённых в F# девопсов или дата-аналитиков. Пример деплой билда на FAKE:
"Clean"
==> "Build"
==> "Deploy"
Ну и далее, скрипт можно править на лету тем же девопсам или аналитикам не погружаясь в F#.
1) Type Inference + Automatic Generalization.
Ну, с выводом типов в ФП не поспоришь, это круто. С другой стороны, в больших приложениях где используют шарп сигнатуры метода желательно видеть явно + можно случайно что-то поломать. Давно не писал на F#, пример из головы: взяли, поменяли что-то в теле функции, тип int поменялся на string и получили ошибки во всех местах вызова, хотя хотелось бы получить одну ошибку, что возвращаемое значение не соответствует декларируемому типу. В лямбдах это не проблема, потому что они обычно не переиспользуются, хотя и там циклически идет вывод типа и карсным подчеркивается пол-экрана. Тут же ситуация усугубляется. Вывод нелокальных типов был специально так задуман и реализован, как с точки зрения производительности компилятора, так и с точки зрения того, чтобы ошибка не ускакивала за 10 слоев абстракции от того места, где ты реально накосячил.
2) Immutable Types + Record Types
Что такое "по-настоящему Immutable" довольно холиварная вещь. Можно посмотреть выступление Скита на дотнексте на эту тему, довольно занятно. В любом случае, сделать Immutable-types в шарпе спокойно можно, типичный пример — структура с get-only свойствами. Но работать с ними больнее, это конечно никто не спорит. Иммутабельность в ФП очевидно будет лучше, чем в C-like ООП языке.
3) Создание DSL
F# умеет создавать инлайн операторы на лету для более выразительного кода.
Ну, тут и спорить не о чем, фича очень полезная.
А так же новые паттерны для паттерн матчинга:
Паттерн матчинг плохенький завезли в C# 7.0. В 8.0 должен появиться помощнее + он должен быть expression, а пока что обходимся statement'ом. В итоге в некотором виде есть уже.
А так же свои монадные преобразования с помощью workflow синтаксиса.
Не вопрос и в шарпе
```сsharp
var c = doDangerousOp1()?.. doDangerousOp2()?.doDangerousOp2();
Не так мощно, но 99,9% потребностей покрывается.
> 4) Dicriminated Union + Tuples
Таплы есть и в шарпе (не те, которые System.Tuple, а нормальный), ну а DU мб завезут когда-нибудь...
Скрипты имхо идеально пишутся на powershell, тут F# не сильно выигрывает у C#.
Лично мой опыт с F# что без мутабельных операций некоторые вещи очень сложно писать. Причем как раз-таки алгоритмы придуманные в 50-80 годах, которые описываются как "а теперь сюда перезапишем вон то, а потом и вон то". И либо приходится мутировать переменны и быть редиской и "грязным" парнем, либо очень сильно извращаться. Я пошел по второму пути (потому что иначе зачем писать на ФП и на каждом шагу его хачить?) и в итоге забил. Но на шарпе стал намного лучше и дженериками пользоваться, и лямбдами.
В итоге возможно я F# немного не понял, но во многом он выглядит как более мощный шарп (который постепенно у него фичи и ворует), но на котором писать сложнее во многих случаях. Опять же, может я просто не умею его готовить.Давно не писал на F#, пример из головы: взяли, поменяли что-то в теле функции, тип int поменялся на string и получили ошибки во всех местах вызова, хотя хотелось бы получить одну ошибку, что возвращаемое значение не соответствует декларируемому типу.
А если это не ошибка, а какой-нибудь глобальный рефакторинг? Тогда как раз удобно будет во всех местах вызова исправлять.
- В большинстве случаев это ошибка, а язык должен покрывать основные сценарии использования, а не крайне редкие. В Хаскелле поэтому границы вывода ограничены именно по этой причине, чтобы ошибка не утекала в какое-то левое место. Очень неприятно 2 часа сидеть искать, где же развалилось. Не сильно удобнее, чем читать 300-страничные сообщения об ошибке в плюсовых темлейтах.
- Если вдруг это глобальный рефакторинг, достаточно заменить слово int на string в одном месте и получить желаемый результат. Причем упадут вызовы этой функции, а не вызовы вызовы вызовов. А у нас получается, с полным выводом типов упадет самая верхняя функция, вернувшая неподходящий тип, а не самая близкая к месту реального изменения
тем, что алгоритм устроен так, что место ошибки определить невозможно
хм строит систему из пицотыщ уравнений и потом начинает ее решать унификацией
то есть он берет какоето уравнение, подставляет туда абстрактный аргумент, по нему подставляет в другое у-е и т.д. — в каком-то у-е на аругмент накладывается ограничение, аргумент становится более конкретным
если где-то ошибка — то В НЕКОТОРОМ месте в графе возникнет противоречие — будет наложено ограничение, которому аргумент уже не может удовлетворить (из-за другого ограничения, которое было наложено раньше, например сперва сказали, что должна быть строка, а потом — что число, при этом неизвестно где именно ошибка — там где фиксирована строка, или там где фиксировано число, и в зависимости от хода реализации алгоритма он выведет ошибку или в том месте или в другом)
и ты бай дезигн не можешь указать, в какой точке графа ошибка — в какой-то
в любой
ты можешь только сказать, что «вот в этом месте мой вывод обломался», при чем для одного и того же кода то место, в котором он обломается, зависит от деталей реализации алгоритма, и при малейших вариациях кода — оно может прыгать через десятки файлов, сквозь тыщи строк кода
хачкелисты решают эту проблему например так, что считают отсутствие типов у топлевел ф-й кодесмеллом — если типы конкретные для ф-и указаны, то граф фиксируется на границе ф-и и значит ошибка точно внутри, алгоритм гарантированно обломается при пересечении границы ф-и (если ошибка в ней)
при это офк твоя ошибка может быть где-то в середине ф-и, а проблему тебе покажет в том, что возвращаемое значение не соответствует (например)
но это все же не выходит уже за пределы юзабельности
Отвечу про F#. Я уже в течение некоторого времени решаю некоторые научные и инженерные задачи с помощью F#, и могу сказать следующее: F# мешает писать приложение неправильно, и в этом его основное преимущество.
F# мешает вам использовать мутабельные переменные (синтаксис для этого есть, но его надо вспоминать, и выглядит громоздко). F# мешает вам делать запутанную многостороннюю архитектуру в проекте благодаря линейному порядку файлов в проекте и определений внутри файла (есть синтаксис для того, чтобы сделать нелинейный порядок, но выглядит это некрасиво и его нужно вспоминать). F# мешает вам сделать у объекта несколько конструкторов, и тем самым мешает делать большие объекты, нарушающие SRP (ну вы поняли, да, синтаксис для этого есть, но вспоминать его редко когда хочется). F# мешает вам перепутать единицы измерения в физической формуле (или загнать туда неопределённые единицы) после того, как вы начинаете их использовать в программе.
Мне он напоминает мудрого наставника, который указывает мне недостатки программы ещё во время написания кода. И это очень, очень удобно.
Ну и чуть меньшее преимущество F# заключается уже в том, что он помогает писать программы в функцональном стиле, с применением операторов типа |>, композиции функций, паттерн-матчинга.
Еще есть CsvProvider, смысл примерно тот же: выводятся типы для каждого поля csv.
Минус: это пока не работает на .NET Core.
F# применяю лет 5-6 для внутренней аналитики, DSL, простых poore-IO сервисов и бизнес логики по причинам, упомянутым Szer. Например F# у меня удачно вписывается в создание вью-моделей WPF в связке с вивером Fody.PropertyChanged, который бесплатно даёт F#-рекордам с mutable полями наследование IPropertyChanged. Весьма удобная опция для доменных модели WPF/UWP приложений, где F# имеет много шансов сиять.
Вообще по впечатлениям F# простой и практичный язык. В качестве не недостатков, но расстановки точек над И для тех кто планирует в F# отмечу
как функциональный язык F# не поддерживает (или поддерживает ограниченно ) многие хайтек парадигмы ФП из Haskel/Erldng, что имеет как плюсы так и минусы.
- иногда при программирования на F# я сталкивался с тем, что мне требовался бОльший контроль над низкоуровневыми частями системы, чем может предоставить язык. В этом случае приходилось делать полный или частичный откат в C#. После 2-3 кейсов я был готов к такому варианту развития событий и особых проблем не возникало, благо C# и F# имеют много общего.
как функциональный язык F# не поддерживает (или поддерживает ограниченно ) многие хайтек парадигмы ФП из Haskel/Erldng
Правильно ли я понимаю, что
- зная C# можно сначала перейти на F#
- а затем изучив F# можно перейти на Haskel или Erlang?
Знание C# (из чего автоматом следует знание инфраструктуры .Net) сильно поможет освоить F# — можно сразу переходить от теории к практике.
Изучить Haskell определённо проще, зная F#, поскольку оба языка из семейства ML и предполагают те же функциональные концепты — каррирование аргументов, неизменяемость, пайплайнинг, ФВП, cписковые включения, построители выражений (do-нотация Haskell, вычислительные выражения F#). Но шагов от F# до Haskell предстоит сделать на много больше, чем от C# к F#. Ленивость по умолчанию и классы типов делают Haskell значительно более сложным для изучения, чем F#
Имхо F# не много даст для практического освоения Erlang, динамического языка со специфическим синтаксисом, если вообще что-то даст. Слишком сильно языки и среды выполнения отличаются.
А какие есть ORM для использования с F#? И как они поддерживают discriminated unions?
Отвечаю на первую половину вашего вопроса: для F# можно пробовать использовать те же ORM, что и для C#, но без поддержки discriminated unions. Вот тут есть довольно старая статья, по которой можно примерно оценить, с какими сложностями предстоит столкнуться.
А по второй половине: в F# распространена парадигма работы с БД, отличная от использования обычных ORM, к которым мы с вами привыкли по C#. Тут часто используют т.н. провайдеры типов. Вот руководство от Microsoft, которое описывает работу с FSharp.Data.TypeProviders. Есть и другие провайдеры, которые могут вас заинтересовать: SqlClient, SQLProvider.
Немного дополню.
Руководство от Microsoft подходит для ознакомления с провайдерами типов, однако использовать FSharp.Data.TypeProviders не рекомендуется, эта библиотека устарела. Чаще всего используют упомянутый SQLProvider. Я недавно встретил пару неплохих статей о том, как это работает в Linux под Mono:
Следует еще упомянуть про Rezoom.SQL. Это новый провайдер типов для SQL, обладающий прекрасной документацией.
В этой истории есть ложка дегтя. К сожалению, провайдеры типов пока не работают под .NET Core. Поэтому приходится использовать стандартные решения, например, Dapper.
То ли проекты неподходящие, то ли я его не воспринимал… Да и с интеграцией F# и С# проекта есть определённые сложности. А с развитием C# и вовсе его «функциональщины» стало хватать.
Но, на текущей работе вдруг понадобилась разработка для Apache Spark, и… открыл для себя Scala, и в принципе, воспринял :)
Хотя от Java и всего с ней связанного ранее воротило…
Не могу сказать, что Scala лучше F# или хуже, но синтаксис F# сложнее, что-ли.
Например, let add x y = x + y, на Scala можно написать и в более привычном (для C#) виде def add(x:Int,y:Int) = x + y. Да, F# запись проще, но не цепляет, приходится вглядываться.
Мнение сугубо личное и, возможно, после более длительного знакомства со Scala я пересмотрю его и F# мне тоже понравится…
Например, let add x y = x + y, на Scala можно написать и в более привычном (для C#) виде def add(x:Int,y:Int) = x + y. Да, F# запись проще, но не цепляет, приходится вглядываться.
на F# можно и так, и вглядываться не надо:
let add (x: int, y: int) = x + y
Только это не нужно, т.к. VS Code над такой функцией напишет int -> int -> int:
let add x y = x + y
Так что это скорее в плюс F#

ошибся веткой
Для меня основная проблема F# я не понимаю что будет внутри в IL и какая будет производительность этого всего + как влепить туда ограничения.
Например тот же пример суммы квадратов, что будет если дать инпут который вернет больше int.MaxValue или long.MaxValue?
например:
let square x = x * x
let sumOfSquares n =
[1..n] // Создадим список с элементами от 1 до n
|> List.map square // Возведем в квадрат каждый элемент
|> List.sum // Просуммируем их!
printfn «Сумма квадратов первых 5 натуральных чисел равна %d» (sumOfSquares 5)
printfn «Сумма квадратов первых 100000000000 натуральных чисел равна %d» (sumOfSquares 100000000000)
что покажет компилятор для типа sumOfSquares?
Ниже ваши же примеры на C# (кроме типов, не могу сейчас это переписать).
Это можно копирнуть как в console app, так и в C#Script .csx если вам хочется ближе к интерпретатору.
int square(int x) => x * x;
int sumOfSquares(int n) =>
Enumerable.Range(1, n) // Создадим список с элементами от 1 до n
.Select(square) // Возведем в квадрат каждый элемент
.Sum(); // Просуммируем их!
void Sample1() =>
Console.WriteLine($«Сумма квадратов первых 5 натуральных чисел равна {sumOfSquares(5)}»);
// 'getMessage' — это функция, и `name` — ее входной параметр.
string getMessage(string name) => name == «Phillip»? «Hello, Phillip!»: «Hello, other person!»;
string phillipMessage => getMessage(«Phillip»); // getMessage, при вызове, является выражением. Его значение связано с именем 'phillipMessage'.
string alfMessage => getMessage(«Alf»); // Это выражение связано с именем 'alfMessage'!
// Создадим список квадратов первых 100 натуральных чисел
List first100Squares => Enumerable.Range(1, 100).Select(x => x * x).ToList();
// То же самое, но массив!
int[] first100SquaresArray => Enumerable.Range(1, 100).Select(x => x * x).ToArray();
// Функция, которая генерирует бесконечную последовательность нечетных чисел
//
// Вызывать вместе с Seq.take!
bool isOdd(int i) => i % 2 != 0;
IEnumerable odds() => Enumerable.Range(1, int.MaxValue).Where(isOdd);
void printfn() => Console.WriteLine($«Первые 3 нечетных числа: [{string.Join(»; ", odds().Take(3))}]");
// Вывод: «Первые 3 нечетных числа: seq [1; 3; 5]
IEnumerable getOddSquares(IEnumerable items) =>
items
.Where(isOdd)
.Select(square);
{kind=link}
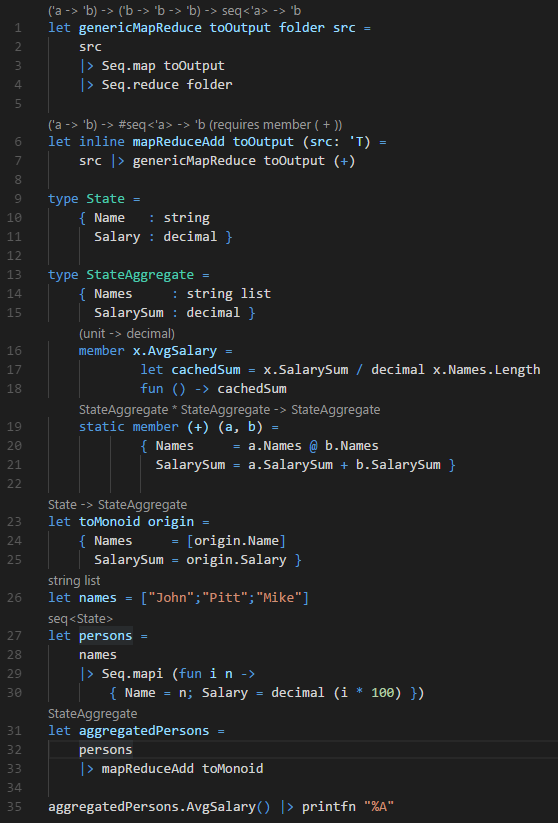
Я не могу конвертнуть ваши 35 строчек, потому что я не читаю F# даже со словарём и понятия не имею что такое
let inline
или
static member (+) (a, b)
1) a.Names @ b.Names
2) x.SalarySum / decimal x.Names.Length
3) Ну и как раз про типы было бы удобно видя примеры сайд бай сайд сравнить что проще.
Я уже давно не задаюсь вопрос «как легко что-либо написать», основные вопросы на нормальном уровне приложений «как легко это будет понять если не трогать это год» «как легко это будет понять другому девелоперу» «как легко это будет поменять».
4) По поводу неявных типов к вашему джисту у меня сразу как у C# девелопера вопросы:
let genericMapReduce toOutput folder src
folder это string или System.IO.DirectoryInfo? как это должен понять девелопер, который читает этот код на гитхабе?
5) каким образом можно понять что в этом примере
let toReport person =
{ Names = [person.Name]
SalarySum = person.Salary }
person это type Person и соотв. F# даёт использовать .Name, .Salary?
6) вот это похоже на то же самое что в C#
Seq.mapi (fun i n ->
{ Name = n; Salary = decimal (i * 100) })
Я так понимаю F# считает что i это int иначе зачем писать decimal(i*100)
Кстати попозже мб попробую написать это в C# 7, с использованием кортежей. Вполне может быть выйдет столько же букв.
Я тоже не пишу на F#, но разобраться в коде элементарно.
- let inline — подсказка компилятору, что надо встраивать метод
- static member (+) (a, b) — в C# это operator+
- a.Names @ b.Names — из контекста: результат конкатенации списков. (Concat в C#)
- x.SalarySum / decimal x.Names.Length — приведение типов
Единственная проблема при переносе на C# в том, что он не поддерживает ограничение (+) в дженериках.
Приведенный пример больше напоминает шаблоны С++.
Вопрос: можно ли mapReduceAdd использовать в другом модуле?
2. я тоже так подумал, но это ппц такое делать в реальном коде, и уж тем более как пример (для классов типа PersonReport)
3. a.Names b.Names это List, т.е. @ это a.Union(b).ToList() или без ToList()?
4. это сделано чтобы дать hint типу cachedSum чтобы делать деление без округления? C# скомпилится и так и так.
- Не совсем для оптимизации. Особенность компилятора при работе с дженериками. Не стоит на этом заморачиваться, это не главное
- Это обычное дело при работе с моноидными типами и агрегацией большого кол-ва данных в разных срезах.
- List в F# это действительно список (в C# List — это массив вообще-то), но односвязный.
Конкатенация списков в F# почти бесплатная (ссылку у последнего элемента подменить, причём для этого ему не надо проходить один из списков до конца из-за внутренней оптимизации). Полный аналог в C# — это работа с LinkedList, но для данной цели это тоже неважно, можно и в массивах. - F# не допускает неявных преобразований, даже из int в decimal. Их можно сделать, но по умолчанию их нет. В C# их тоже можно сделать (implicit operator), но по умолчанию они есть.
2. мб, как C# девелопер понятия не имею что такое моноидный тип
3. они мутабл или иммутабл?
если написать
let a (PersonReport)
let b (PersonReport)
let c (PersonReport)
let ab = a+b
let abc = ab+c
что будет в ab.Names?
4. C# не делает преобразований когда ничего не указывается, он возвращает округленный int, когда один из аргументов кастуется в decimal то возвращается decimal. в IL будет разный код для деления интов и деления децималов и будет разный перформанс этих операций.
чтобы было понятнее 1 / 2 это так сказать Int32.Divide(1, 2)
1m / 2 это decimal.Divide(1, 2)
Это очень большая тема, но именно она (с примерами на C#) изложена здесь.
Вкратце — в IL нет констрейна на (+), поэтому мы не можем скомпилировать отдельную функцию с таким ограничением. Но можно изхитриться и не компилировать такую "функцию" отдельно, а воспользоваться инлайнингом и разрешать проблемы с типами в контексте CallSite.
Именно это и позволяет делать F#. Эти дополнительные констрейны, которых нет в C#, не магия и не костыль, а всего лишь хитрое использования инлайнинга.
Это из теории категорий. Пример — у вас триллион твитов и вам надо по нажатию кнопочки сформировать срез "среднее кол-во лайков".
Сама по себе сущность tweet — неагрегируема, да и слишком много там ненужной инфы. Поэтому мы создаём дополнительный тип, который содержит нужные нам поля для агрегации и является агрегируемым.
Затем мы преобразуем tweet в новую сущность (map)
И агрегируем новые сущности (reduce)
А чтобы всё это работало в кластере с возможностью разбиения на чанки и инкрементальным добавлением к уже сагрегированым данным новой инфы надо добавить ещё пару ограничений:
1) операция агрегации должна быть ассоциативна — (a+b)+c=a+(b+c)
2) тип для агрегации должен иметь некий Zero элемент: Z+a=a, a+Z=a.
И тогда внезапно выясняется что это моноид!
Списки в F# иммутабл
В ab.Names будут два имени. Но сами значения, которые содержатся в элементах списка заново аллоцироваться не будут.
Пример с комментариями
- 1m / 2 — это деление явного decimal на явный int, который почему-то преобразуется в decimal.Divide(). А почему не в Int32.Divide()?
2. ну это тот же .Select + .Aggregate с несколько большим количеством сахара?
3. по примеру интересно что будет после 21-й строки в
abList.Tail.Tail.Head.Equals ( c )
compile error, runtime error?
если abList не меняется, то получается всё же что референсы на элементы abList копируются и abList.Tail != abcList.Tail
т.е. это типичный List where T: class, но не List where T: struct.
Что опять же не отвечает на что такое @ — .Union() (=итератор) или .Union().ToList() (=копии референсов на все элементы обоих списков)
4. да согласен в этом случае, int приводится в decimal автоматически.
2) Так точно. Всё то же самое в С# можно сделать.
Select -> map
Aggregate -> fold
аналога reduce в C# нет, но это тот же fold, но без указания начального стейта (т.е. мы сразу агрегируем данные, без нулевого элемента)
3) abList.Tail.Tail вернёт пустой список, поэтому abList.Tail.Tail.Head даст рантайм ошибку — System.InvalidOperationException: The input list was empty.
можно ли mapReduceAdd использовать в другом модуле?
Да, конечно. Он максимально generic.
На C# его сигнатура выглядит так:
TOutput mapReduceAdd <TInput, TOutput, TSource>
(Func<TInput, TOutput> toOutput, TSource src)
where TOutput: + //да, в C# так не получится
where TSource: IEnumerable<TInput>Для меня основная проблема F# я не понимаю что будет внутри в IL и какая будет производительность этого всего + как влепить туда ограничения.
В большинстве случаев производительность будет страдать. При применении различных идиом ФП деградация перформанса практически неизбежна. Насколько это допустимо и оправдано бонусами, которые даёт F#, надеюсь сами понимаете — зависит от задачи. Если опыт и интуиция подсказывают вам, что код может стать узким местом — не задумываясь пишите его на C#.
Но тут надо сказать, что автор F# очень много сделал чтобы деградация перформанса была минимально возможной и всегда об этом много пёкся. Например, рекорды в F# не плоские как haskell, а древовидные в b-tree. Что делает их весьма полезными персистентными структурами данных в приложениях с интенсивным IO
дать инпут который вернет больше int.MaxValue или long.MaxValue?
будут ошибки компиляции что-то вроде "число вне допустимого диапазона" и "надо int64, а получен long" соотв. F# очень строго следит за такими вещами и никаких глупых казусов со слабыми неявными преобразованиями чисел не допустит. Даже по мнению некоторых программистов — слишком строго)
sumOfSquares
Это у них крайне не удачный пример. Я бы на вашем месте написал на С# следующим образом
static int SumOfSquaresOfNormalHuman(int n)
{
var a = 0;
for (int i=0; i<n; i++)
{
a += i * i;
}
return a;
}Подобные глупости с якобы "учебными" примерами очень сильно дискредитируют F# в глазах опытных инженеров C#. У последних сразу возникает ощущение впаривания фуфла.
К счастью, никто не может "прикрыть" F#. Язык поддерживается сообществом и F# Software Foundation, исходный код компилятора открыт под лицензией Apache 2.0. Насколько мне известно, компания Microsoft также не собирается отказываться от поддержки F# в Visual Studio.
Планы Microsoft относительно F# изложены в The .NET Language Strategy.
Если перевод "Get Started with F# as a C# developer" очень хорош (на мой взгляд, взаимозаменяем с оригиналом), то, к сожалению, перевод "The .NET Language Strategy" огорчает.
Очень похоже на машинный перевод, или дословный перевод человеком, далеким от разработки:
"подписи API" — в оригинале это "API's signatures", т.е., сигнатуры, декларации, заголовки API, но никак не подписи;
и множество подобных моментов.
Погружение в F#. Пособие для C#-разработчиков