

Каждый из нас воспринимает тексты по-своему, будь это новости в интернете, поэзия или классические романы. То же касается алгоритмов и методов машинного обучения, которые, как правило, воспринимают тексты в математической в форме, в виде многомерного векторного пространства.
Статья посвящена визуализации при помощи t-SNE рассчитанных Word2Vec многомерных векторных представлений слов. Визуализация позволит полнее понять принцип работы Word2Vec и то, как следует интерпретировать отношения между векторами слов перед дальнейшем использованием в нейросетях и других алгоритмах машинного обучения. В статье акцентируется внимание именно на визуализации, дальнейшее исследование и анализ данных не рассматриваются. В качестве источника данных мы задействуем статьи из Google News и классические произведения Л.Н. Толстого. Код будем писать на Python в Jupyter Notebook.
T-distributed Stochastic Neighbor Embedding
T-SNE — алгоритм машинного обучения для визуализации данных на основе метода нелинейного снижения размерности, который подробно описан в оригинальной статье [1] и на Хабре. Базовый принцип работы t-SNE заключается в сокращении попарных расстояний между точками при сохранении их относительного расположения. Иными словами, алгоритм отображает многомерные данные на пространство более низкой размерности, при этом сохраняя структуру соседства точек.
Векторные представления слов и Word2Vec
Прежде всего нам необходимо представить слова в векторном виде. Для этой задачи я выбрал утилиту дистрибутивной семантики Word2Vec, которая предназначена для отображения семантического значения слов в векторное пространство. Word2Vec находит взаимосвязи между словами согласно предположению, что в схожих контекстах встречаются семантически близкие слова. Подробнее о Word2Vec можно прочитать в оригинальной статье [2], а также тут и тут.
В качестве входных данных мы возьмем статьи из Google News и романы Л.Н. Толстого. В первом случае воспользуемся предобученными на датасете Google News (около 100 млрд слов) векторами, опубликованными Google на странице проекта.
import gensim
model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
В дополнение к предварительно обученным векторам при помощи библиотеки Gensim [3] мы обучим еще одну модель на текстах Л.Н. Толстого. Поскольку Word2Vec в качестве входных данных принимает массив предложений, мы используем предобученную модель Punkt Sentence Tokenizer из пакета NLTK для автоматического разбиения текста на предложения. Модель для русского языка можно скачать отсюда.
import re
import codecs
def preprocess_text(text):
text = re.sub('[^a-zA-Zа-яА-Я1-9]+', ' ', text)
text = re.sub(' +', ' ', text)
return text.strip()
def prepare_for_w2v(filename_from, filename_to, lang):
raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read()
with open(filename_to, 'w', encoding='utf-8') as f:
for sentence in nltk.sent_tokenize(raw_text, lang):
print(preprocess_text(sentence.lower()), file=f)
Далее с помощью библиотеки Gensim обучим Word2Vec-модель со следующими параметрами:
- size = 200 — размерность признакового пространства;
- window = 5 — количество слов из контекста, которое анализирует алгоритм;
- min_count = 5 — слово должно встречаться минимум пять раз, чтобы модель его учитывала.
import multiprocessing
from gensim.models import Word2Vec
def train_word2vec(filename):
data = gensim.models.word2vec.LineSentence(filename)
return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Визуализация векторных представлений слов с помощью t-SNE
T-SNE крайне полезен для визуализации сходства между объектами в многомерном пространстве. С увеличением количества данных становится всё сложнее и сложнее построить наглядный график, поэтому на практике близкие слова объединяют в группы для дальнейшей визуализации. Возьмем для примера несколько слов из словаря предварительно обученной на Google News Word2Vec-модели.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive',
'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war']
embedding_clusters = []
word_clusters = []
for word in keys:
embeddings = []
words = []
for similar_word, _ in model.most_similar(word, topn=30):
words.append(similar_word)
embeddings.append(model[similar_word])
embedding_clusters.append(embeddings)
word_clusters.append(words)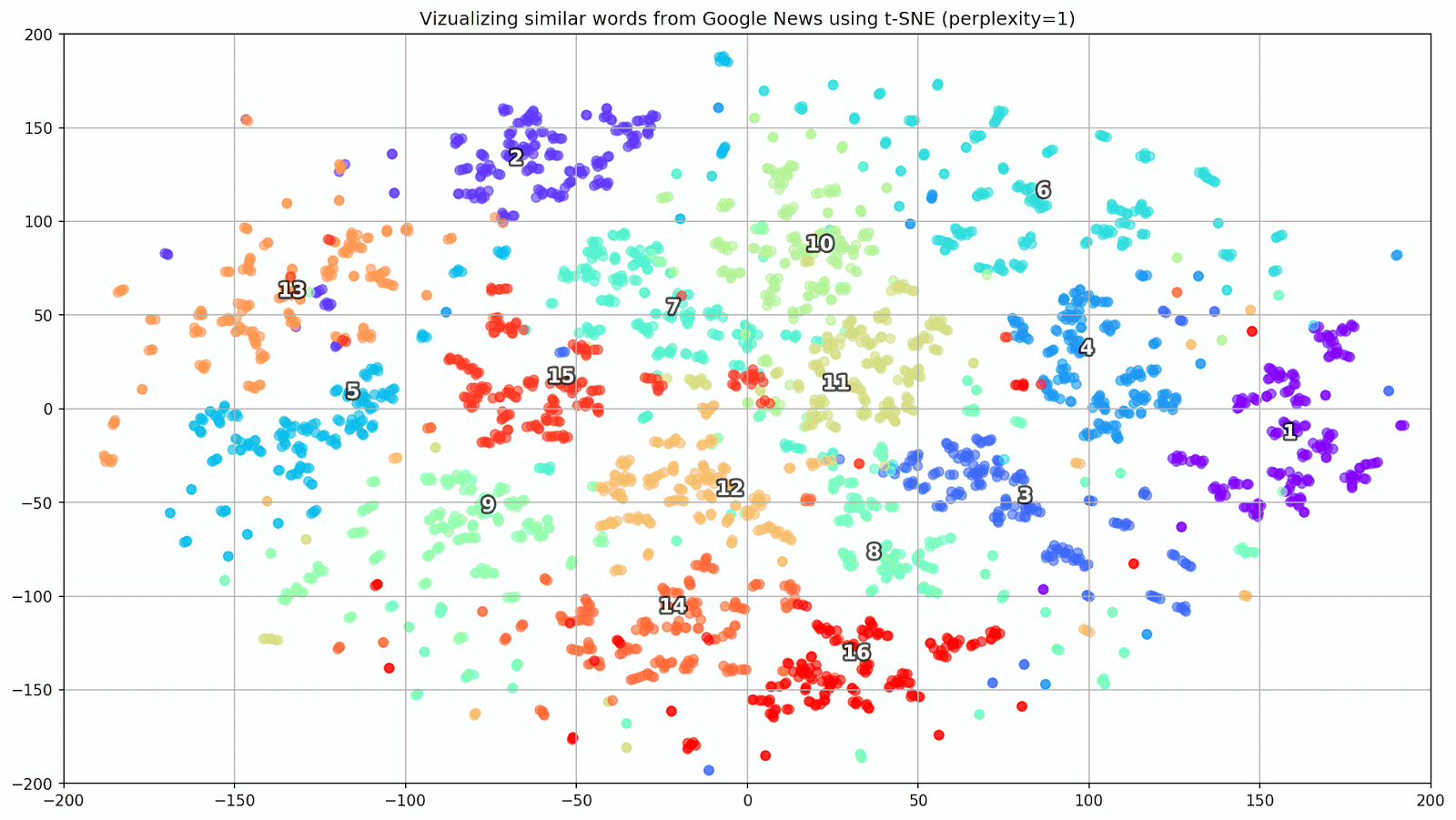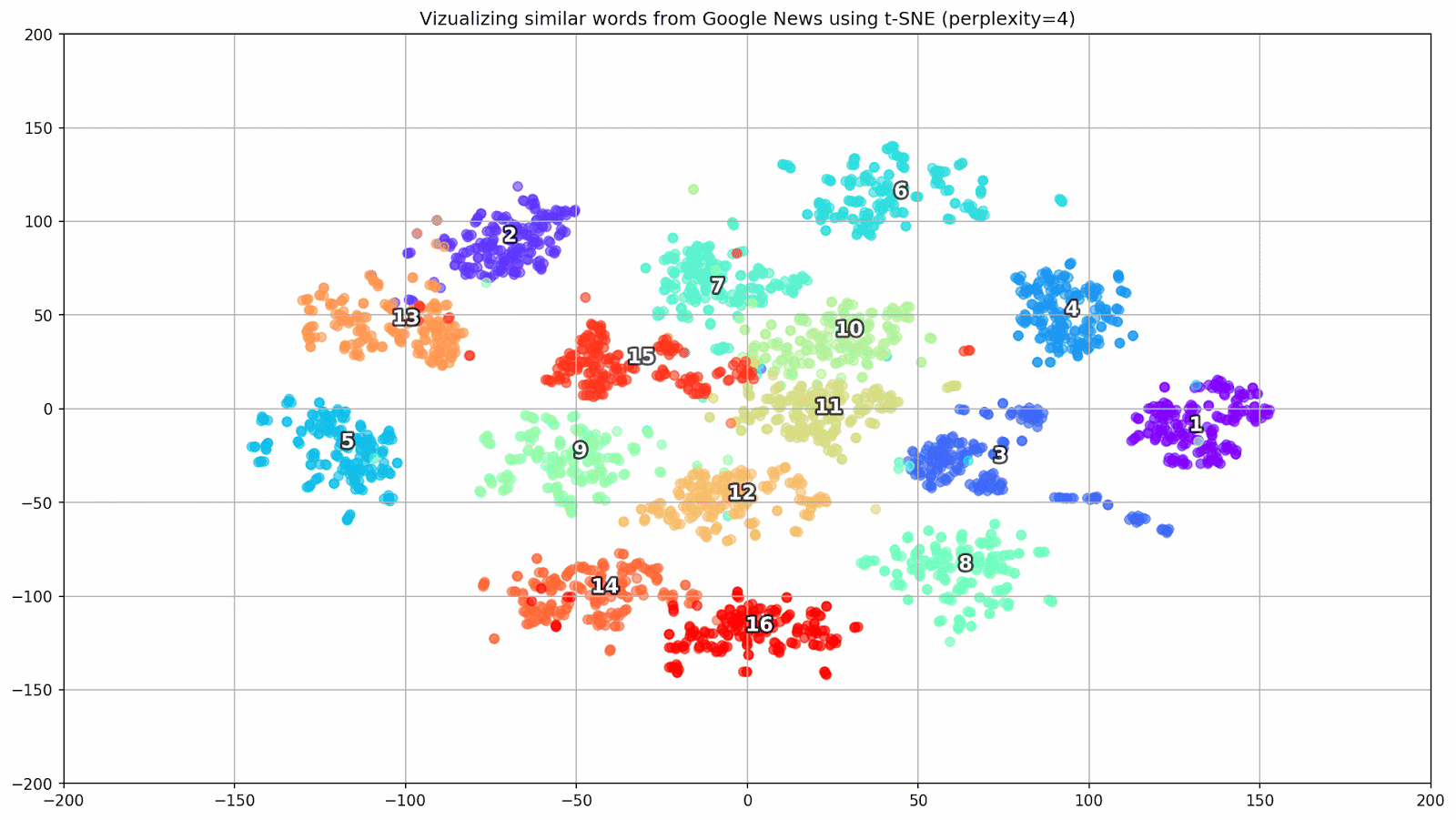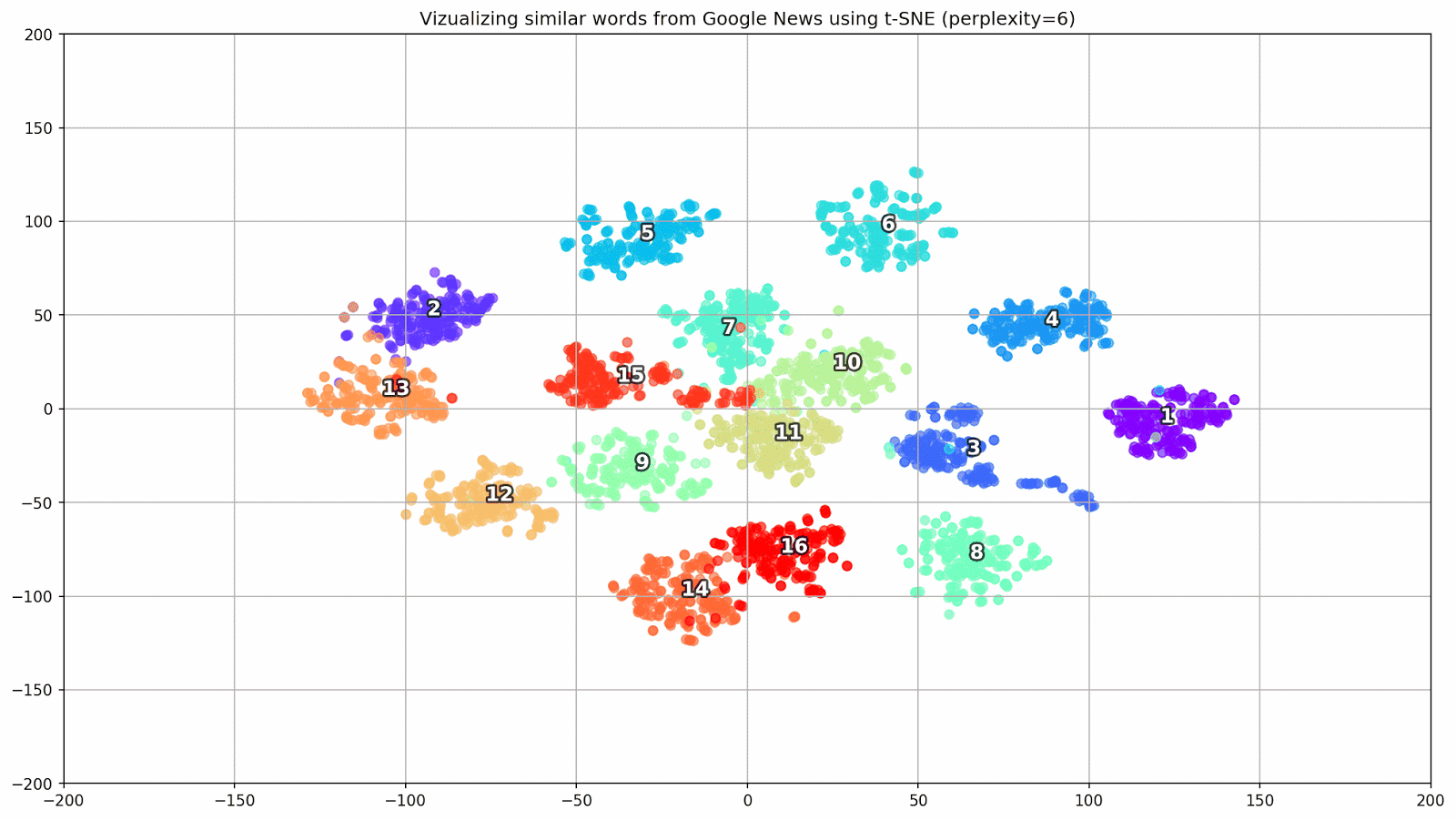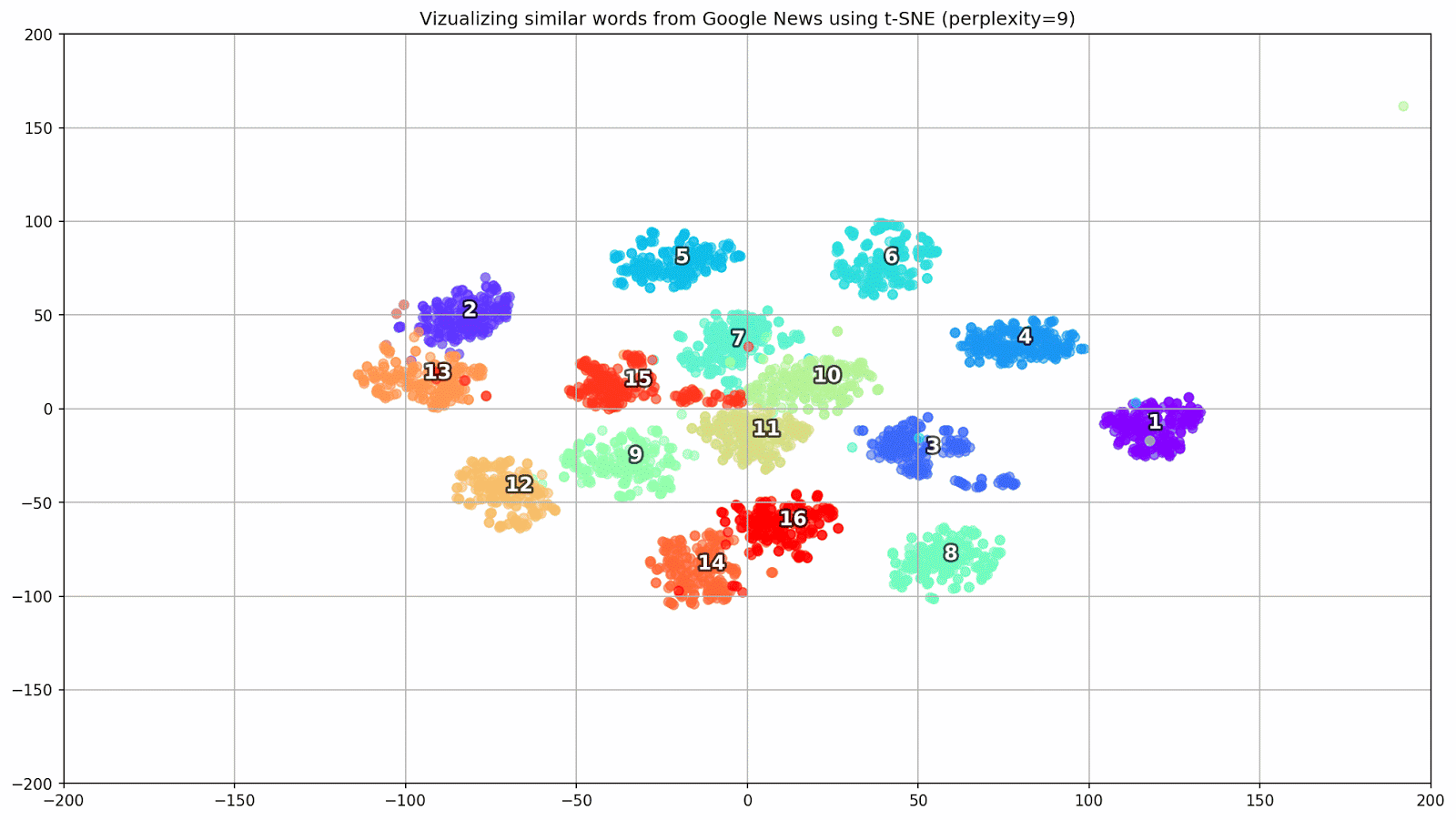
Рисунок 1. Группы схожих слов из Google News с разным значением параметра preplexity.
Далее переходим к самому примечательному фрагменту статьи — конфигурации t-SNE. Здесь в первую очередь следует обратить внимание на следующие гиперпараметры:
- n_components — количество компонентов, т.е., размерность пространства значений;
- perplexity — перплексия, значение которой в t-SNE можно приравнять к эффективному количеству соседей. Она родственна количеству ближайших соседей, которое используется в других моделях, обучающихся на базе многообразий (см. картинку выше). Ее значение рекомендуется [1] устанавливать в диапазоне 5—50;
- init — тип первоначальной инициализации векторов.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32)
embedding_clusters = np.array(embedding_clusters)
n, m, k = embedding_clusters.shape
embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)Ниже представлен скрипт для построения двухмерного графика с помощью Matplotlib, одной из самых популярных библиотек для визуализации данных на Python.
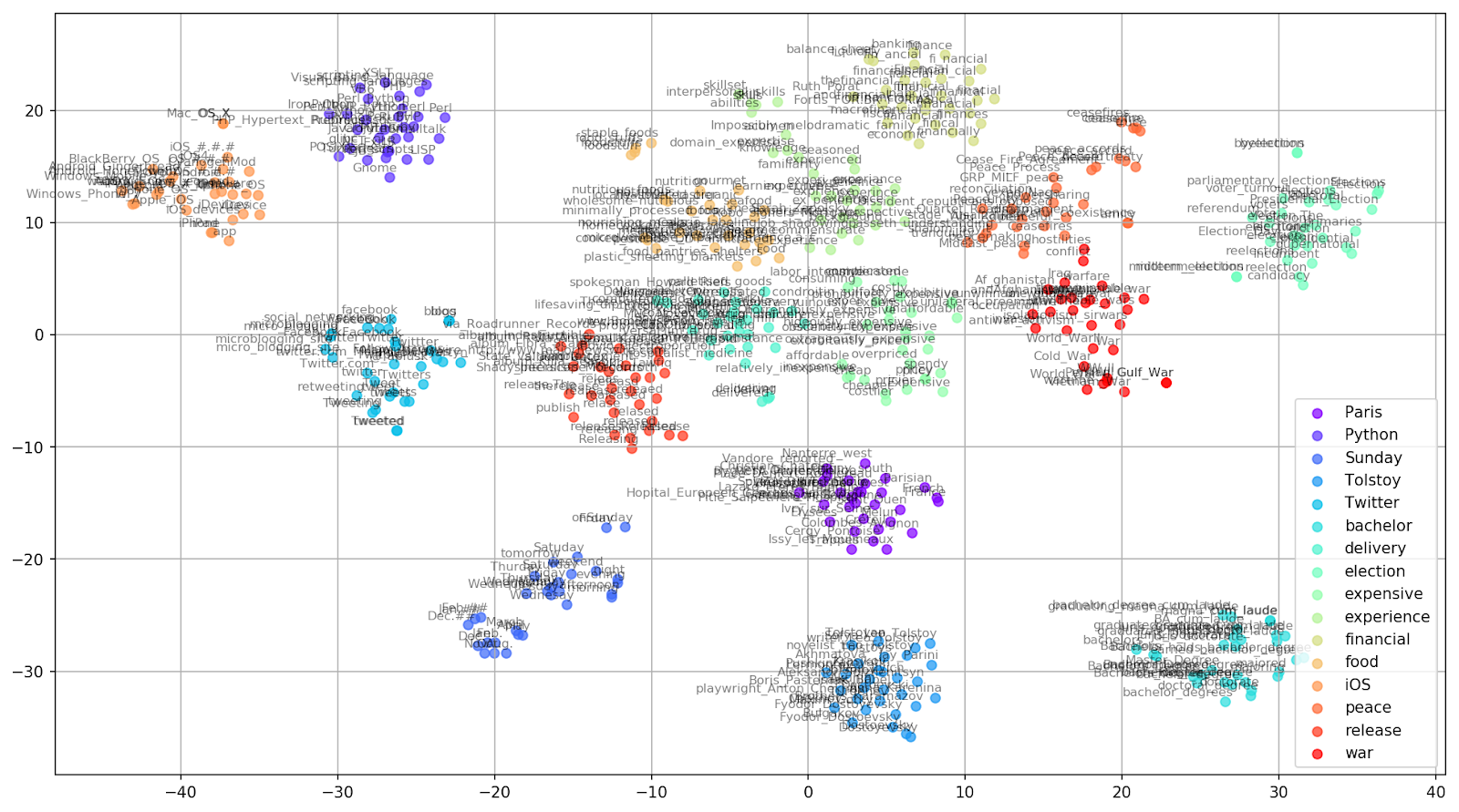
Рисунок 2. Группы схожих слов из Google News (preplexity=15).
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
% matplotlib inline
def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7):
plt.figure(figsize=(16, 9))
colors = cm.rainbow(np.linspace(0, 1, len(labels)))
for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors):
x = embeddings[:,0]
y = embeddings[:,1]
plt.scatter(x, y, c=color, alpha=a, label=label)
for i, word in enumerate(words):
plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom', size=8)
plt.legend(loc=4)
plt.grid(True)
plt.savefig("f/г.png", format='png', dpi=150, bbox_inches='tight')
plt.show()
tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)Иногда бывает нужно построить не отдельные кластеры слов, а весь словарь целиком. Для этой цели давайте проанализируем «Анну Каренину», великую историю страсти, измены, трагедии и искупления.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian')
model_ak = train_word2vec('train_anna_karenina_ru.txt')
words = []
embeddings = []
for word in list(model_ak.wv.vocab):
embeddings.append(model_ak.wv[word])
words.append(word)
tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32)
embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1):
plt.figure(figsize=(16, 9))
colors = cm.rainbow(np.linspace(0, 1, 1))
x = embeddings[:,0]
y = embeddings[:,1]
plt.scatter(x, y, c=colors, alpha=a, label=label)
for i, word in enumerate(words):
plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom', size=10)
plt.legend(loc=4)
plt.grid(True)
plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight')
plt.show()
tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)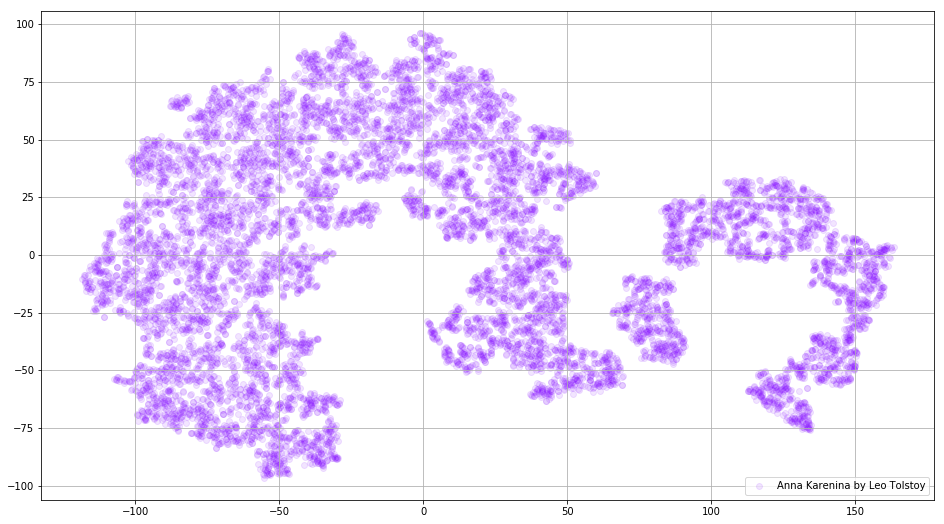

Рисунок 3. Визуализация словаря Word2Vec-модели, обученной на романе «Анна Каренина».
Картина может стать еще более информативной, если мы используем трехмерное пространство. Взглянем на «Войну и мир», один из главных романов мировой литературы.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian')
model_wp = train_word2vec('train_war_and_peace_ru.txt')
words_wp = []
embeddings_wp = []
for word in list(model_wp.wv.vocab):
embeddings_wp.append(model_wp.wv[word])
words_wp.append(word)
tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12)
embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D
def tsne_plot_3d(title, label, embeddings, a=1):
fig = plt.figure()
ax = Axes3D(fig)
colors = cm.rainbow(np.linspace(0, 1, 1))
plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label)
plt.legend(loc=4)
plt.title(title)
plt.show()
tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)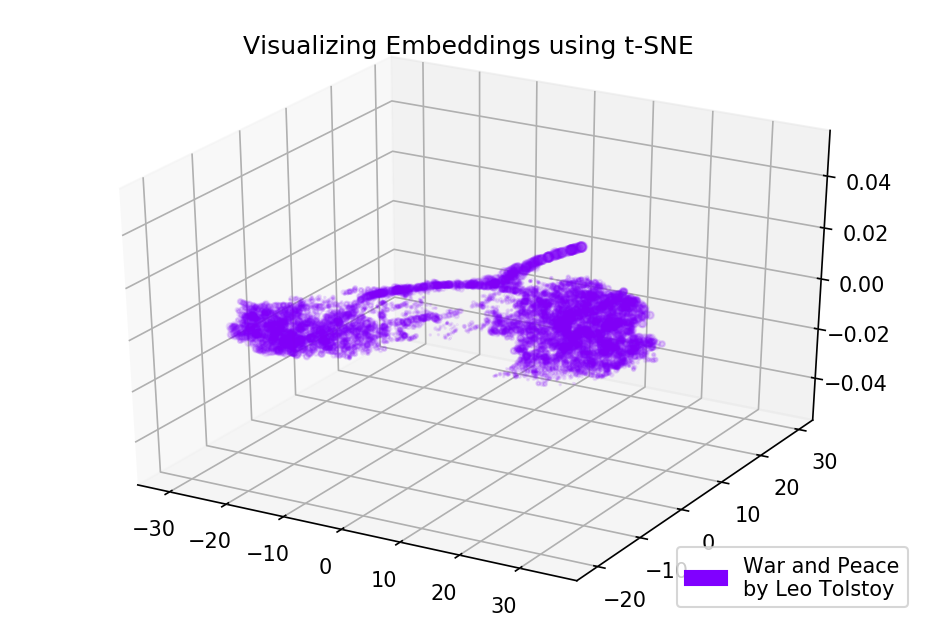
Рисунок 4. Визуализация словаря Word2Vec-модели, обученной на романе «Война и Мир».
Исходники
Код доступен на GitHub. Там же вы можете найти код для отрисовки анимаций.
Источники
- Maaten L., Hinton G. Visualizing data using t-SNE //Journal of machine learning research. – 2008. – Т. 9. – С. 2579-2605.
- Distributed Representations of Words and Phrases and their Compositionality //Advances in Neural Information Processing Systems. – 2013. – С. 3111-3119.
- Rehurek R., Sojka P. Software framework for topic modelling with large corpora //In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. – 2010.
