

Такая романтичная вещь, как звёздное небо, и такая хардкорная вещь, как оптимизация потребления памяти iOS-приложением, вполне могут идти вместе: стоит попробовать запихнуть это звёздное небо в AR-приложение, как тут же встанет вопрос о том самом потреблении.
Минимизировать использование памяти будет полезно и в очень многих других случаях. Так что этот текст на примере маленького проекта показывает методы оптимизации, способные пригодиться и в совершенно других iOS-приложениях (да и не только iOS-).
Пост подготовлен на основе расшифровки доклада Конрада Файлера с конференции Mobius 2018 Piter. Прилагаем его видеозапись, а далее — текстовый вариант от первого лица:
Рад приветствовать всех! Меня зовут Конрад Файлер, а под эффектным названием «Миллион звёзд в одном iPhone» мы обсудим, как вы можете минимизировать размер памяти, занимаемый вашим iOS-приложением. Красочно и в примерах.
Зачем оптимизировать?
Что вообще побуждает нас заниматься оптимизацией, чего именно мы хотели бы достичь? Мы не хотим вот этого:

Мы не хотим, чтобы пользователю приходилось ждать. То есть первая причина — уменьшить время загрузки.
Другая причина — улучшить качество.

Речь тут может идти о качестве изображений, звука и даже AI. «Оптимизированный AI» означает, что можно достичь большего — например, просчитывать игру на большее число ходов вперёд.
Третья причина, очень важная: экономия заряда аккумулятора. Оптимизация помогает меньше разряжать батарею. Вот интересное сравнение, хоть и из мира Android. Здесь сравнили Vulkan и OpenGL ES:

Второй хуже оптимизирован под мобильные платформы. Наблюдая за скоростью расхода энергии батареи, можно видеть, что для аналогичного изображения OpenGL ES тратил намного больше ресурса, чем Vulkan.
Какого рода оптимизация может здесь помочь? Например, в пошаговой игре, когда пользователь думает над своим ходом, можно снижать FPS до нуля. Если у тебя 3D-движок, то совершенно разумно просто отключать всё, пока пользователь просто смотрит на экран.
Кроме того, бывают случаи, когда без оптимизированного подхода вы не будете иметь возможность реализовать ту или иную продвинутую фичу: её попросту будет не потянуть.
Без фанатизма
Говоря об оптимизации, нельзя не вспомнить тезис Дональда Кнута: «Нам следует забывать о небольшой эффективности, скажем, в 97% случаев: преждевременная оптимизация — корень всех зол. Хотя мы не должны отказываться от своих возможностей в этих критических 3%».
В 97% случаев мы должны заботиться не об эффективности, а прежде всего о том, как сделать наш код понятным, безопасным и тестируемым. Мы всё же разрабатываем для мобильных устройств, а не для космических кораблей. Компании, где работаем, не должны переплачивать за поддержку написанного нами кода. Кроме того, рабочее время разработчика имеет стоимость, и если тратишь его на оптимизацию чего-то несущественного, то расходуешь средства компании. Ну а в том, что хорошо оптимизированный код имеет свойство быть более сложным для понимания, вы сможете убедиться и на тех примерах, которые я продемонстрирую вам сегодня.
В общем, осмысленно расставляйте приоритеты и оптимизируйте по мере необходимости.
Подходы
Работая над оптимизацией, мы обычно следим либо за производительностью (читай: загруженностью процессора), либо за объёмами используемой памяти. Зачастую эти два варианта будут конфликтовать, и потребуется искать баланс между ними.
В случае с процессором мы можем снижать количество циклов процессора, требуемых нашими операциями. Как вы понимаете, меньшее количество циклов процессора даёт нам меньшее время загрузки, меньший расход батареи, возможность обеспечить лучшее качество и т.д.
Для iOS-разработчиков в Xcode Instruments есть удобный инструмент Time Profiler. Он позволяет отслеживать число циклов CPU, затрачиваемых разными частями вашего приложения. Этот доклад не об инструментах, так что в детали сейчас погружаться не буду, об этом было хорошее видео с WWDC.
Можно выбрать другую цель — оптимизация ради памяти. Постараемся сделать так, чтобы при запуске наше приложение умещалось в как можно меньшее число ячеек RAM. Помните, что наиболее объёмные приложения становятся первыми кандидатами на принудительное завершение при чистке, которую вынуждена проводить ОС. Поэтому это влияет на то, как долго ваше приложение будет оставаться в фоновом режиме.
Немаловажно и то, что ресурс RAM у разных устройств тоже разный. Если вы, скажем, решили разрабатывать под Apple Watch, то там памяти мало, и это тоже заставляет оптимизировать.
Наконец, порой маленький объём памяти ещё и делает программу очень быстрой. Приведу пример. Перед вами структуры различного объёма в байтах:

Element8 содержит 8 байт, Element16 — 16, и так далее.

Заведём массивы, по одному для каждого из наших видов структур. Размерность всех массивов одинаковая — по 10 000 элементов. В каждой структуре содержится разное количество полей (по нарастающей); поле n является первым полем и, соответственно, присутствует во всех структурах.
А теперь попробуем следующее: для каждого массива будем производить расчёт суммы всех его полей n. То есть мы каждый раз будем суммировать одинаковое количество элементов (10 000 штук). Разница только в том, что для каждой суммы переменная n будет добываться из разных по размеру структур. Нас интересует то, одинаковое ли время займёт суммирование.
Результат получаем следующий:
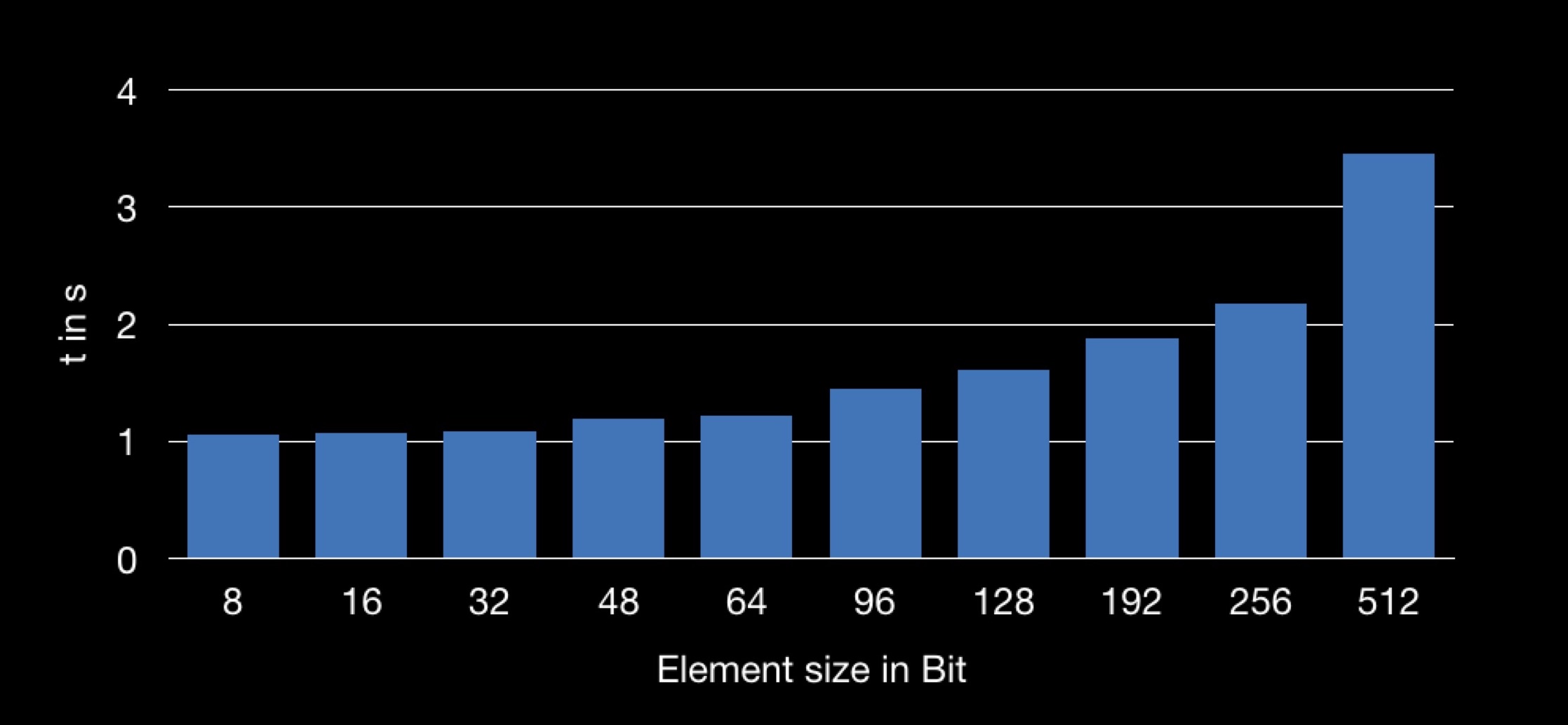
На графике показана зависимость времени суммирования от размера структуры, использованной в массиве. Получается, что добывать поле n из большей по размеру структуре — дольше, а потому и операция суммирования занимает больше времени.
Многие из вас уже поняли, почему так происходит.
У процессора есть кэши L1, L2 (иногда ещё L3 и L4). К этому типу памяти процессор обращается непосредственно и быстро.
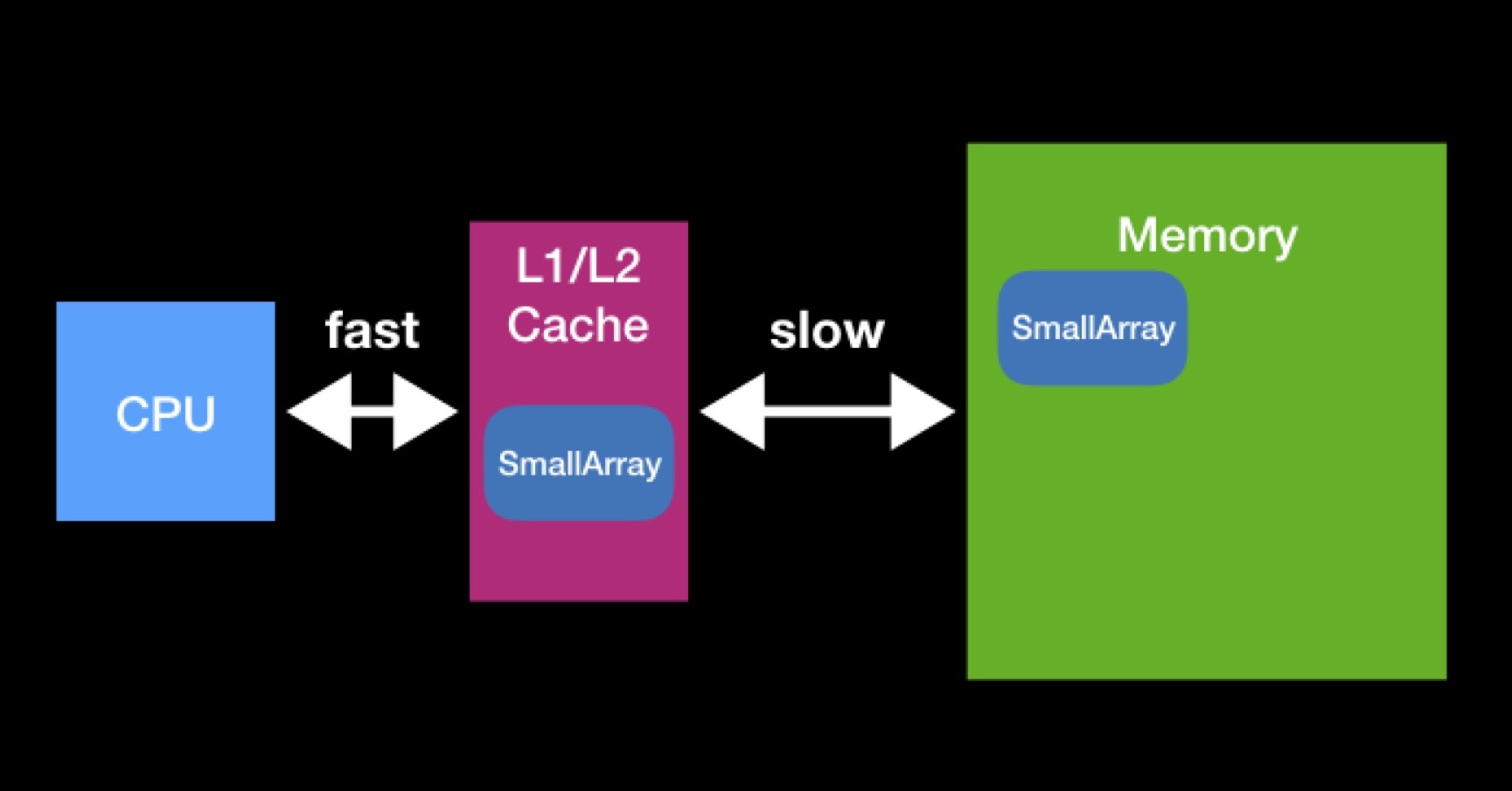
Кэши существуют для ускорения повторного использования данных. Предположим, мы работаем с массивами. Если нужный процессору массив уже присутствует в каком-либо из кэшей, значит он уже требовался процессору ранее. В тот момент он запросил их у основной памяти, поместил в кэш, выполнил с ними все необходимые операции, после чего эти данные остались лежать (не успели затереться другими).
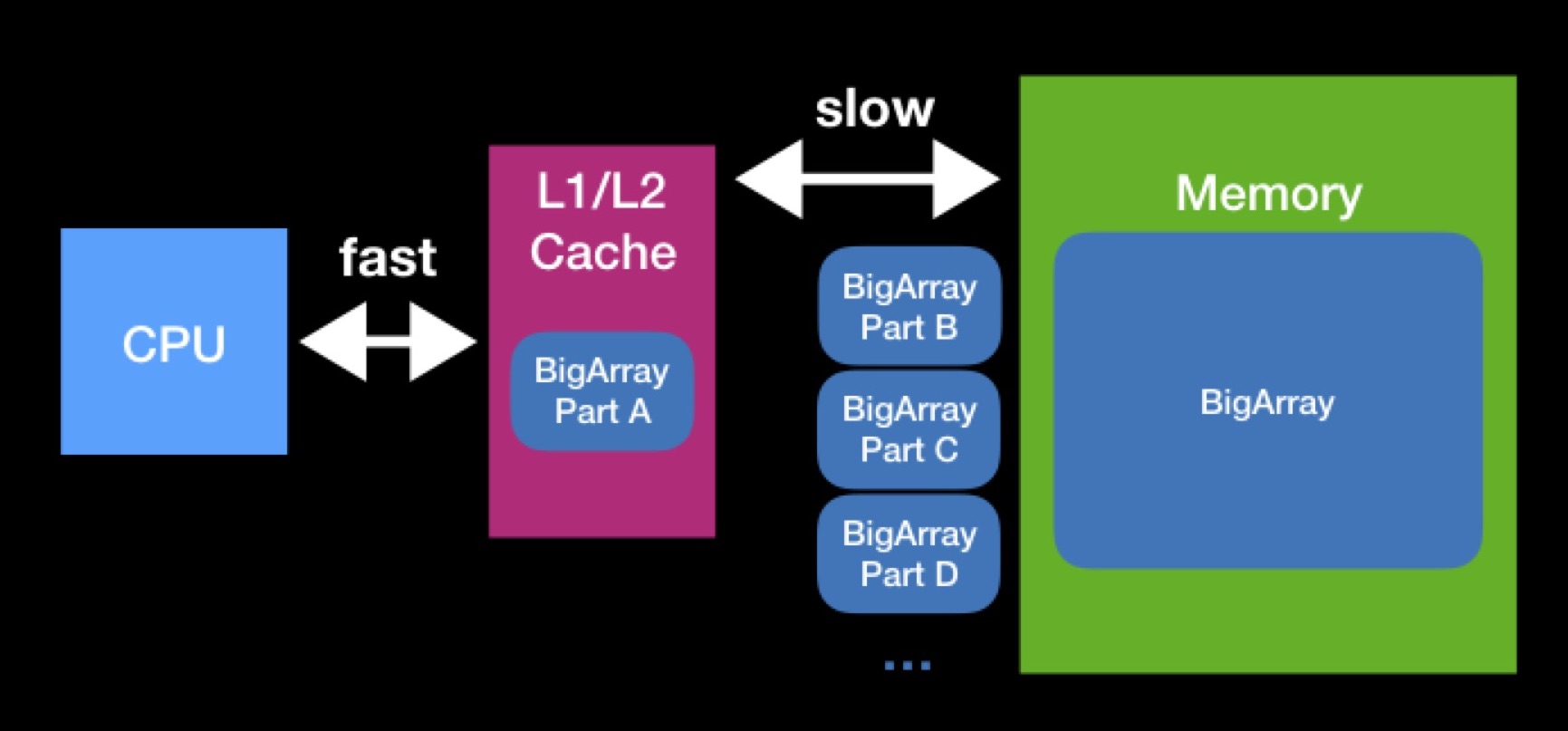
Размеры кэшей L1, L2 не так велики. Массив, необходимый процессору для работы, может оказаться и больше. Чтобы полностью выполнить операцию над таким массивом, нам придётся выгружать его в кэш по частям и оперировать этими частями поочерёдно. Из-за постоянных запросов в основную память обработка нашего массива займёт значительно больше времени.
Программируя структуры данных, старайтесь помнить о механизме работы кэшей. Вполне возможно, что, уменьшив размер своей структуры данных, вы добьётесь её удачной вместимости в кэш и ускорите те операции, которые будут над ней производиться в дальнейшем. Взаимодействие с основной памятью всегда было, есть и, вероятней всего, останется значимым фактором производительности — даже когда вы пишете на Swift для современных высокопроизводительных устройств.
CPU против RAM: ленивая инициализация
Хотя в части случаев при уменьшении используемой памяти программа начинает работать быстрее, есть и случаи, когда эти две метрики, наоборот, конфликтуют. Приведу пример с концепцией ленивой инициализации.
Пусть у нас есть метод makeHeavyObject(), возвращающий некоторый крупный объект. Этим методом будем инициализировать переменную lazilyCalculated.

Модификатор lazy задаёт переменной lazilyCalculated ленивую инициализацию. Это означает, что значение ей будет присвоено только тогда, когда случится первое обращение к ней во время исполнения. Именно тогда отработает метод makeHeavyObject() и полученный объект будет присвоен переменной lazilyCalculated.
В чём здесь плюс? С момента инициализации (пускай и позже, но она выполнится) мы имеем размещённый в памяти объект. Его значение сосчитано, он готов к использованию — достаточно сделать запрос. Другое дело, что наш объект крупный и с момента инициализациям будет занимать в памяти свою львиную долю ячеек.
Можно пойти по другому пути — не хранить значение поля вообще:

При каждой ссылке на поле lazilyCalculated метод makeHeavyObject() будет исполняться заново. Значение будет возвращаться в точку запроса, при этом помещаться в память оно не будет. Как видите, хранить переменную необязательно.
Что же затратнее — хранить в памяти крупный объект, но зато не расходовать процессорное время, или же вызывать метод каждый раз, когда нам нужно наше поле, экономя при этом память? Иметь ли под рукой готовое значение или вычислять его на лету? Такого рода дилемма возникает довольно часто, где бы вы ни выполняли свои вычисления — на удалённом сервере или на своей локальной машине, с каким бы кэшем вам ни пришлось работать. Принимать решение вам придётся исходя из имеющихся в данном конкретном случае системных ограничений.
Цикл оптимизации

Что бы вы ни оптимизировали, ваша работа, как правило, будет строиться по одному и тому же алгоритму. Вначале вы исследуете код, профилируете/измеряете (в Xcode с помощью соответствующих инструментов), стараясь выявить его «узкие места». По сути, упорядочиваете методы по тому, сколько времени они исполняются. И дальше смотрите на верхние строчки, чтобы определить, что оптимизировать.
Выбрав объект, вы ставите себе задачу (или, говоря по-научному, выдвигаете гипотезу): применив те или иные методы оптимизации, вы сможете заставить выбранный кусок кода работать быстрее.
Далее вы пробуете оптимизировать. После каждой модификации вы смотрите на показатели эффективности, оценивая то, насколько результативной оказалась модификация, насколько вы сумели продвинуться.
Прямо как в научной работе: предположение, эксперимент, анализ результатов. Вы проходите этот цикл действий раз за разом. Практика показывает, что работа, построенная таким образом, действительно позволяет устранять боттлнеки один за другим.
Unit-тесты

Коротко о unit-тестах: у нас есть некоторая функция, которую мы тестируем, некоторые входные данные input и выходные данные output; получая на вход input, наша функция должна всегда возвращать output, и никакие наши оптимизации не должны нарушать это свойство.
Unit-тесты помогают нам отследить поломку. Если в ответ на input наша функция перестала возвращать output, значит, прямым либо косвенным образом, мы изменили старый ход работы нашей функции.
Даже не пробуйте начинать оптимизировать, если вы не написали к вашему коду щедрой порции unit-тестов. Вы должны иметь возможность регрессионного тестирования. Если вы посмотрите на GitHub мои коммиты в моём примере приложения, к которому я дальше перейду, можете увидеть, что некоторые из моих оптимизаций привносили с собой баги.
А теперь самое интересное — перейдём к звёздам.
Миллион звёзд
Имеется большая (огромная) база данных, описывающая миллион звёзд. Поверх неё я создал несколько приложений. Одно из них использует дополненную реальность, в реальном времени дорисовывая звёзды поверх изображения с камеры телефона. Сейчас продемонстрирую его в действии:
В условиях отсутствия городских огней человек может различить в небе до 8000 звёзд. На хранение 8000 записей мне понадобилось бы около 1.8 Мб. В принципе, приемлемо. Но мне хотелось добавить и те звёзды, которые человек может видеть в телескоп — получилось порядка 120 000 звёзд (по так называемому каталогу Hipparcos, ныне устаревшему). На это требовалось уже 27 Мб. А среди современных каталогов в открытом доступе можно найти такой, который будет насчитывать порядка 2 500 000 звёзд. Такая база данных заняла бы уже около 560 Мб. Как видите, требуется уже много памяти. А мы ведь хотим не просто базу данных, а основанное на ней приложение, где будут ARKit, SceneKit и другие вещи, также требующие памяти.
Что же делать?
Будем оптимизировать звёзды.
Инструмент MemoryLayout
Можно оценивать размер программы в целом. Но для такой ювелирной работы, как оптимизация, вам понадобятся инструменты оценки размера каждой отдельной структуры данных.
Swift позволяет сделать это достаточно просто — с помощью объектов MemoryLayout<>. Вы объявляете MemoryLayout<>, указывая в качестве дженерик-типа интересующую вас структуру данных. Теперь, обращаясь к свойствам полученного объекта, вы можете получать самую разную полезную информацию о своей структуре.

Свойство size даёт нам количество байт, занимаемое одним экземпляром структуры.
Теперь о свойстве stride. Возможно, вы замечали, что размер массива, как правило, не равен сумме размеров составляющих его элементов, а превосходит её. Очевидно, между элементами в памяти оставляется некоторый «воздух». Для оценки расстояния между последовательными элементами в смежном массиве, мы и используем свойство stride. Если умножить его на число элементов массива, то получится его размер.
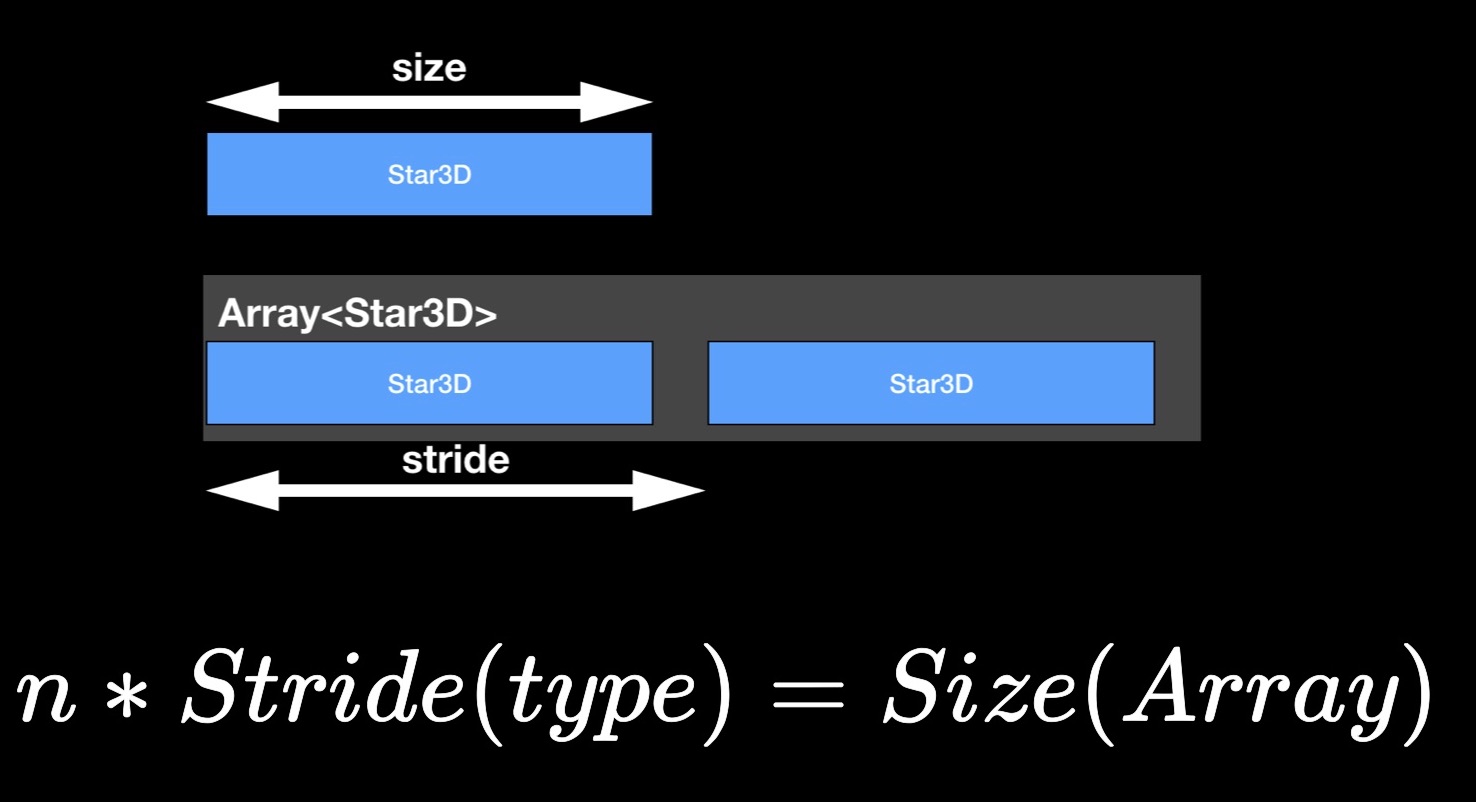
StarData, наша подопытная структура, в своём исходном неоптимизированном состоянии:
Перед вами структура данных, предназначенная для хранения данных об одной звезде. Вам не обязательно вникать в то, что означает каждый из этих элементов. Важнее сейчас обратить внимание на типы: переменные Float, хранящие координаты звезды (по сути, широта и долгота), несколько Int32 для различных ID, String для хранения имён и названий различных классификаций; есть расстояние, цвет и некоторые другие величины, нужных для правильного отображения звезды.
Запросим свойство stride:

На данный момент наша структура весит 208 байт. Миллион же таких структур потребует 250 Мб — это, как вы понимаете, чересчур. Следовательно, необходимо оптимизировать.
Правильные Int
О том, что есть разные разновидности Int, рассказывают ещё на первых уроках программирования. Самый привычный для нас Int в языке Swift носит название Int8. Он занимает 8 бит (1 байт) и может хранить значения от -128 до 127 включительно. Также есть и другие Int-ы:
- Int16 размером в 2 байта, диапазон значений — от -32 768 до 32 767;
- Int32 размером в 4 байта, диапазон значений — от -2 147 483 648 до 2 147 483 647;
- Int64 (или просто Int) размером в 8 байт, диапазон значений — от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807.
Вероятно, те из вас, кто занимался веб-разработкой и имел дело с SQL, об этом уже думает. Но да, первым делом подберите себе оптимальные Int. Я в этом проекте ещё до того, как подойти оптимизацией по уму, немного занялся преждевременной оптимизацией (чего, как только что вам говорил, делать не надо).
Посмотрим, к примеру, на поля с ID. Мы знаем, что звёзд у нас будет порядка миллиона — не несколько десятков тысяч, но и не миллиард. Значит, для таких полей оптимальней всего выбрать Int32. Затем я понял, что и для Float тут достаточно 4 байт. Double займут по 8, String по 24, сложим это всё — получается 152 байта. Если помните, раньше MemoryLayout сказал нам, что 208. Почему? Надо закопаться глубже.
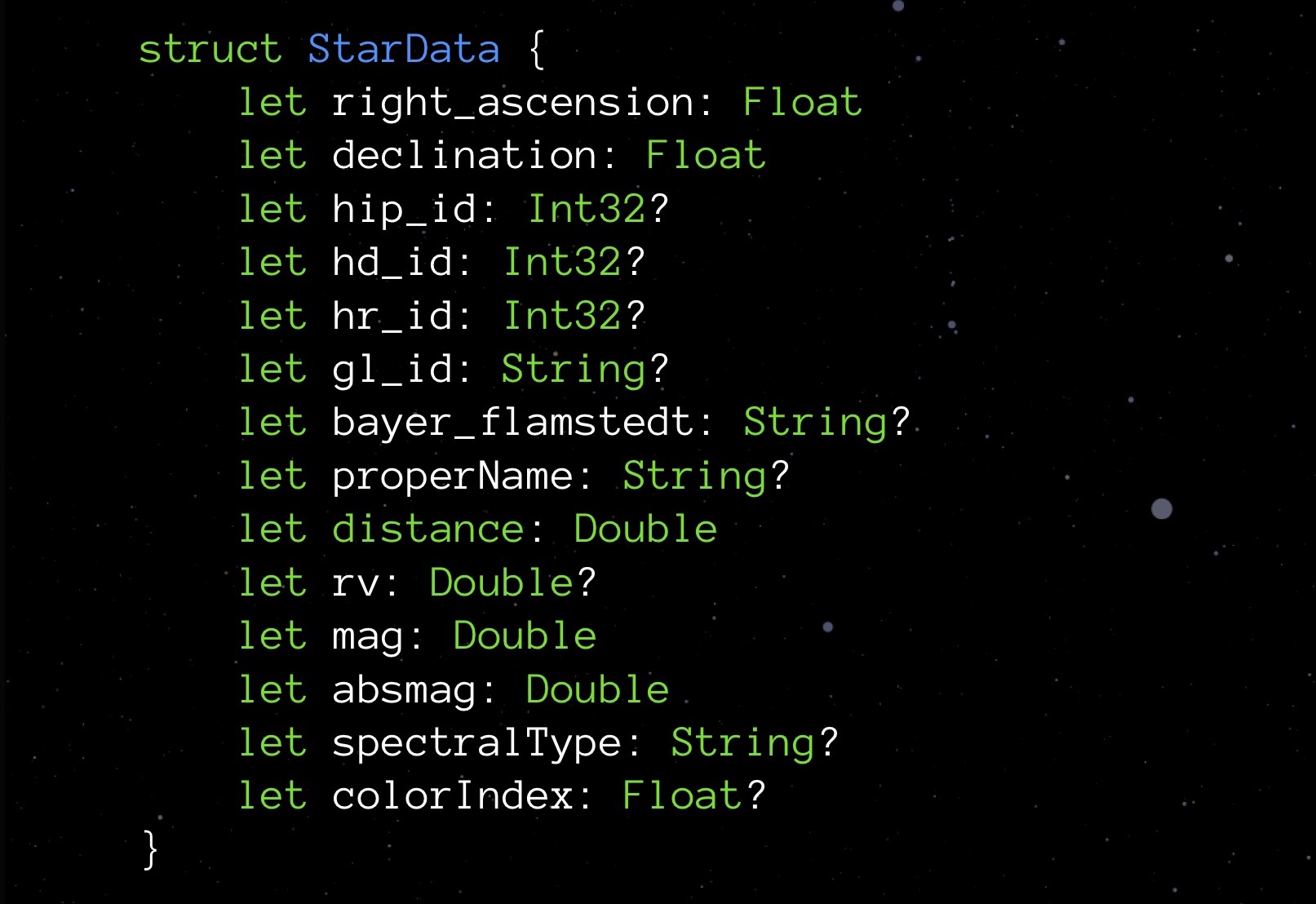
Для начала посмотрим на Optional. Опциональные типы отличаются тем, что в случае отсутствия присвоенного значения хранят nil. Этим достигается безопасность во взаимодействии с объектами. Но как вы понимаете, такая мера не обходится бесплатно: запросив свойство size у любого опционального типа, вы увидите, что такой тип всегда занимает на один байт больше. Мы платим за возможность прописать для поля nil.
Нам бы не хотелось расходовать по лишнему байту на переменную. При этом идея, заложенная в optional, нам очень даже нравится. Что же придумать? Попробуем реализовать свою структуру.
Выберем какое-нибудь значение, которое для данного поля резонно считать «невалидным», при том подходящее под заявленный тип. Для getHipId (Int32) это может быть, например, значение «-1». Оно и будет означать, что наше поле не проинициализировано. Вот такой велосипедный optional, обходящийся без лишнего байта на nil.
Ясно, что при такой хитрости у нас возникает и потенциальная уязвимость. Чтобы обезопасить себя от ошибки, создадим для поля геттер, который будет самостоятельно управляться с нашей новой логикой и проверять значение поля на валидность.

Такой геттер полностью абстрагирует от нас сложность придуманного решения.
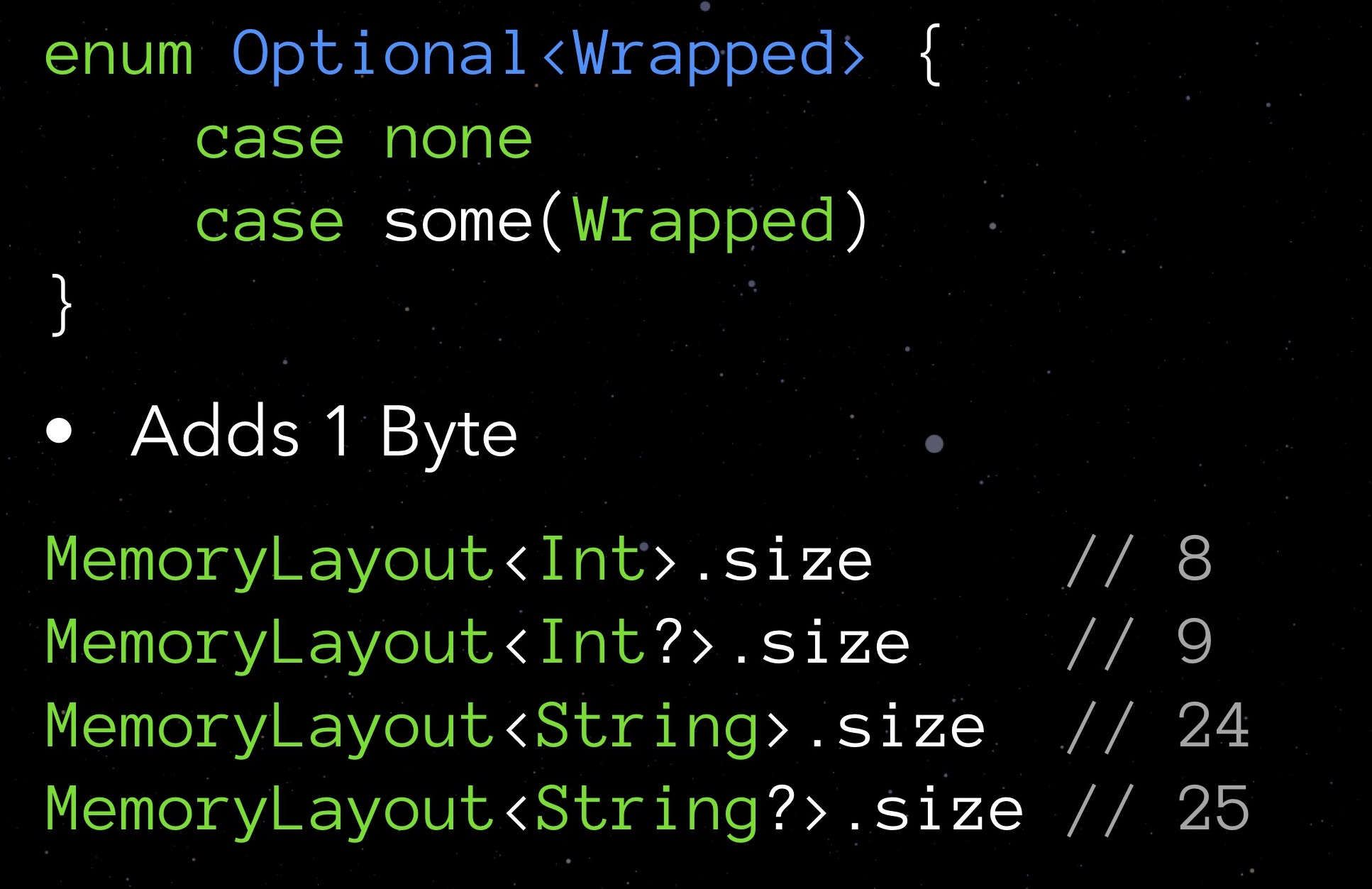
Обратимся к нашей StarData. Заменим все опциональные типы на обычные и посмотрим, что покажет stride:
Оказывается, ликвидировав опционалы, мы сэкономили не 9 байт (по байту на каждый из девяти опционалов), а целых 48. Сюрприз приятный, но хотелось бы знать, почему так произошло. А произошло так из-за выравнивания данных в памяти.
Выравнивание данных
Вспомним, что до Swift мы писали на Objective-C, а он отталкивался от C — и эта ситуация тоже уходит своими корнями в C.
Помещая какие-либо структуры в память, современные процессоры размещают их элементы не в сплошной поток (не «плечо к плечу»), а в некоторую неоднородно прореженную пустотами сетку. Это и есть выравнивание данных. Оно позволяет упростить и ускорить доступ к нужным элементам данных в памяти.
Правила выравнивания данных применяются к каждой переменной в зависимости от её типа:
- переменная типа char может начинаться с 1-го, 2-го, 3-го, 4-го и т.д. байта, поскольку сама по себе занимает всего один байт;
- переменная типа short занимает 2 байта, поэтому может начинаться со 2-го, 4-го, 6-го, 8-го и т.д. байта (то есть с каждого чётного байта);
- переменная типа float занимает 4 байта, а значит может начинаться с каждого 4-го, 8-го, 12-го, 16-го и т.д. байта (то есть с каждого четвёртого байта);
- переменные типов Double и String занимают по 8 байт, поэтому могут начинаться с 8-го, 16-го, 24-го, 32-го и т.д. байта;
- и т.д.
У объектов MemoryLayout<> есть свойство alignment, возвращающее для указанного типа соответствующее ему правило выравнивания.
Не сможем ли мы применить знание правил выравнивания для оптимизации кода? Посмотрим на примере. Имеется структура User: для firstName и lastName используем обычный String, для middleName — опциональный String (такого имени у пользователя может и не быть). В памяти экземпляр такой структуры разместится следующим образом:

Как видите, поскольку опционал middleName занимает 25 байт (вместо кратных 8-ми 24-х байт), правила выравнивания обязывают пропустить следующие за ним 7 байт и затратить на всю структуру не 73, а 80 байт. Здесь, как ни переставляй местами блоки со строками, на меньшее количество байт рассчитывать невозможно.
А теперь пример неудачного выравнивания:

Структура BadAligned вначале объявляет isHidden типа Bool (1 байт), затем size типа Double (8 байт), isInteractable типа bool (1 байт) и наконец age типа Int (тоже 8 байт). Объявленные в таком порядке, наши переменные будут размещены в памяти таким образом, что суммарно структура займёт 32 байта.
Попробуем поменять порядок объявления полей — расположим их в порядке возрастания занимаемого объёма и посмотрим, как изменится картина в памяти.
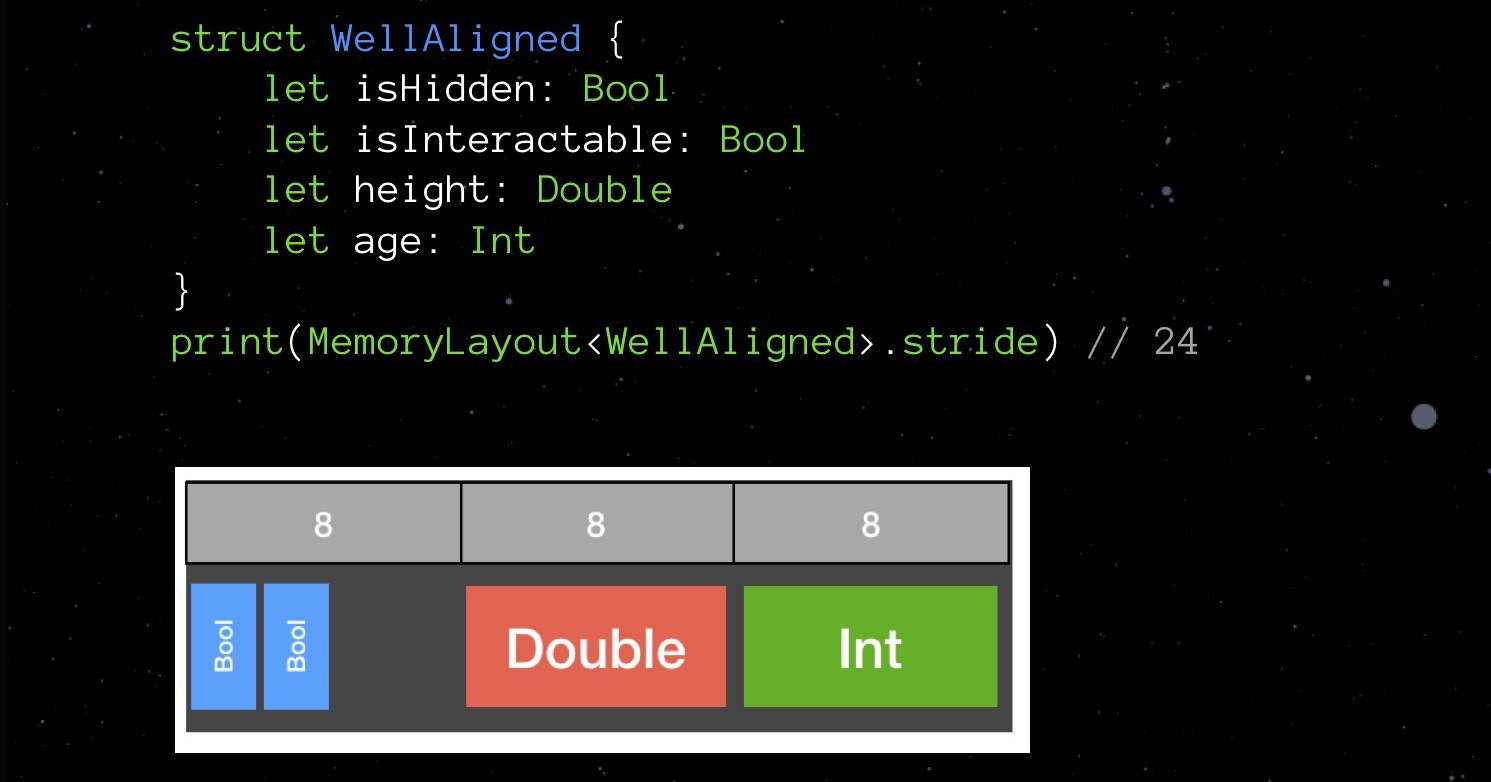
Наша структура занимает не 32 байта, а 24. Экономия на 25%.
Похоже на игру в Тетрис, неправда ли? Таким низкоуровневым вещам Swift обязан языку C — своему предку. Объявляя поля в большой структуре данных беспорядочно, вы с высокой вероятностью используете больше памяти, чем могли бы, учитывая правила выравнивания. Поэтому старайтесь помнить о них и учитывать при написании кода — не так-то это и сложно.
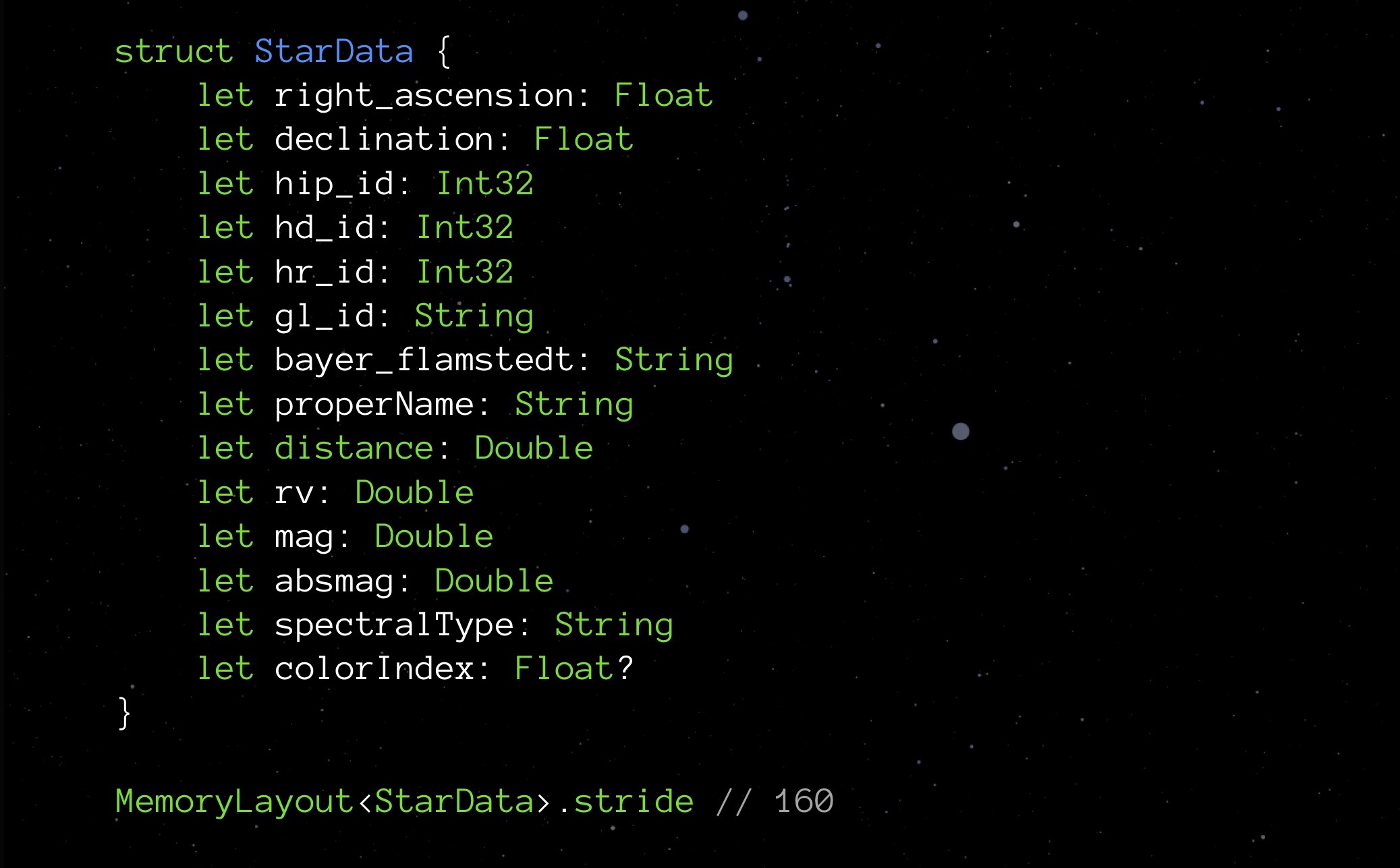
Снова обратимся к нашей StarData. Попробуем расставить её поля в порядке возрастания занимаемого объема.
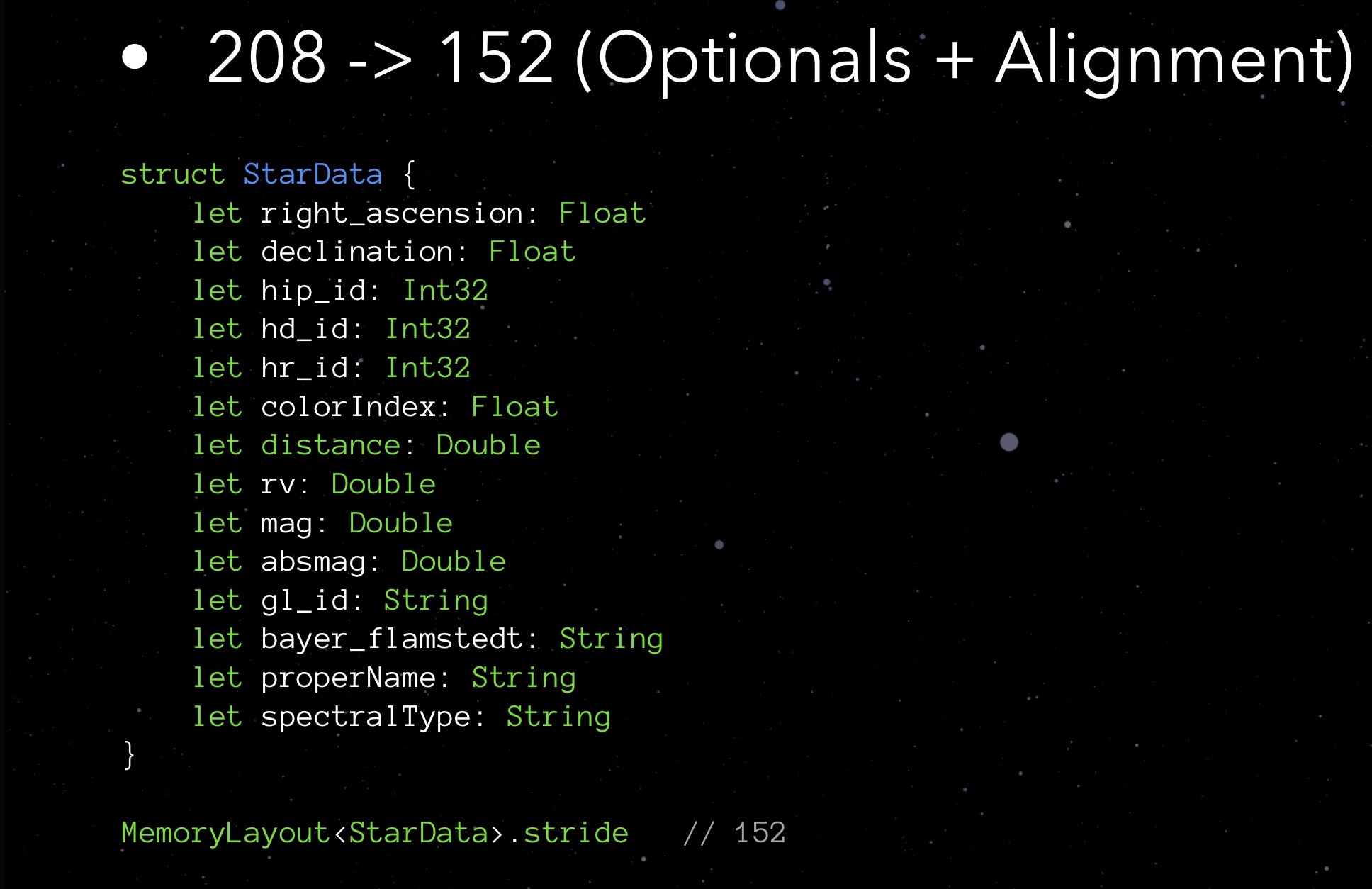
Сначала Float и Int32, затем уже Double и String. Не такой уж и замысловатый Тетрис!
Полученный нами stride составляет 152 байта. То есть, оптимизировав реализацию опционалов и поработав с выравниванием, мы сумели снизить объём структуры с 208 до 152 байт.
Приближаемся ли мы к пределу наших оптимизационных возможностей? Вероятно, что да. Однако есть ещё кое-что, что мы с вами не пробовали — кое-что на порядок сложней, но способное иной раз поразить своим результатом.
Учёт доменной логики
Попробуйте сосредоточиться на том, какая специфика присуща вашему сервису. Вспомните мой пример с шахматами: идея варьирования показателя FPS, когда на экране ничего не меняется — это как раз оптимизация путём учёта доменной логики приложения.
Снова взглянем на StarData. Наше явное «узкое место» — поля типа String, они действительно занимают очень много места. И тут специфика в следующем: во время рантайма большинство этих строк остаются пустыми! Всего лишь у 146 звёзд есть «настоящее» название, которое указывается в поле properName. А gl_id — ID звезды в соответствии с каталогом Глизе, который насчитывает 3801 звезду, тоже далеко не миллион. bayer_flamstedt — обозначения Флемстида — будут присвоены 3064-м звёздам. Спектральный тип spectralType — 4307-ми. Получается, что для большинства звёзд заведённые строковые переменные будут пустовать, при этом занимая по 24 байта каждая.
Я придумал следующий выход из положения. Заведём в качестве дополнительной структуры ассоциативный массив. В качестве ключа — уникальный числовой идентификатор типа Int16, в качестве значения, в зависимости от наличия строки-характеристики — либо её значение, либо -1.
В нашей StarData напротив properName, gl_id, bayer_flamstedt и spectralType будем прописывать индекс, соответствующий ключу в массиве. При необходимости получить ту или иную строку-характеристику, будем запрашивать значение у массива посредством индекса. Делать это вручную незачем — лучше реализуем удобный безопасный геттер:

Геттер здесь очень важен — он скрывает от нас сложность собственной реализации. Массив же можно прописать как private, о его существовании теперь знать необязательно.
Разумеется, у такого решения есть и минус. Экономия памяти не может не сказаться на процессорной нагрузке. При такой схеме мы вынуждены постоянно выполнять обращения к нашему ассоциативному массиву; причём в большинстве случаев — впустую, так как большинство строк останутся незаполненными и запросы будут возвращать «-1».
Поэтому мне пришлось чуть изменить концепцию работы приложения. Было решено предоставлять пользователю информацию о звезде лишь при нажатии им на эту звезду — только тогда выполнится запрос к ассоциативному массиву и полученные данные отобразятся на экране.
Несмотря на абстракцию геттером, надо признать, что введением ассоциативного массива мы всё же значительно усложнили код. Так обычно и бывает при оптимизации. Поэтому важно провести качественный unit-тестинг — удостовериться, что наш ассоциативный массив не подведёт нас в неожиданный момент.
Итого: stride теперь выдаёт нам 64 байта!
На этом всё? Нет, теперь надо снова вспомнить про правила выравнивания: переставляем поля типа Int16 повыше.

Вот теперь всё. Как видите, при помощи небольшого числа простых по своей сути методов нам удалось снизить объём структуры StarData с 208 до 56 байт. Миллион звёзд теперь занимает не 500 Мб, а 130. В четыре раза меньше!
Не забываем о вреде преждевременной оптимизации. Если ваша структура данных User будет использоваться для каких-то 20 пользователей, вы там не выиграете столько, чтобы вообще был смысл этим заниматься. Куда важнее, чтобы следующему разработчику после вас удобно было поддерживать код. Пожалуйста, не говорите потом «этот чувак на конференции сказал, что порядок должен быть именно таким»! Не делайте этого просто ради развлечения. Ну, для меня такие вещи — неплохое развлечение, не знаю, как для вас.
Оптимизация компилятора Swift
Большинству программистов хорошо знакома боль долгой (невыносимо долгой) пересборки проекта. Вы всего лишь внесли в код небольшое изменение, и вот опять сидите и ждёте, пока закончит выполняться сборка.
А ведь процесс сборки может кое-что рассказать вам о вашем коде. Это прекрасный индикатор боттлнеков, надо только приспособить его для работы.
Лично я исследовал компиляцию в Xcode. В качестве инструмента я использовал следующую команду:

Данная команда распоряжается, чтобы xCode отслеживал время компиляции каждой функции и записывал его в файл culprits.txt. Содержимое файла попутно сортируется.

Используя свой простенький инструмент, я мог наблюдать интересные вещи. Некоторые методы могли компилироваться аж по 2 секунды, содержа при этом всего три строчки кода. Что может стать причиной?
К примеру, такая вещь, как вывод компилятором типов. Если вы не указываете типы явно, то Swift вынужден выявлять их самостоятельно. Для этой (надо сказать, нетривиальной) операции требуется процессорное время, поэтому, с точки зрения компилятора, всегда лучше указать тип. Всего лишь прописав явно типы, я однажды смог снизить время сборки приложения с 5 до 2 (!) минут.
Но есть одно «но»: код без типов всё же читабельнее. А о приоритетах мы с вами уже говорили. Не оптимизируйте раньше времени: на первых порах читабельность кода будет стоить дороже.
Серверный вариант
До сих пор я упоминал лишь о своём приложении с дополненной реальностью. Но на основе миллиона звёзд я также создал и серверное приложение на Swift. Можете увидеть и его само, и его код на GitHub. Это API-сервис, позволяющий вам получать информацию о любых звёздах из моей огромной базы. Оптимизировать его я смог при помощи тех же самых методов, какие использовал для приложение на ARkit. Результат в данном случае стал для меня в буквальном смысле материальным: снизив объём до отметки в 500 Мб, я получил возможность поместить его на бесплатный сервер Bluemix. В итоге, мой сервис обходится мне совершенно бесплатно.
Подводя итог
В завершение, небольшое резюме главных мыслей, которые я хотел адресовать вам сегодня:
- Подходите аккуратно к выбору целей для борьбы. Оптимизация всегда будет стоить вам усилий. Вы можете усердно биться над тем, чтобы ваши переменные вычислялись только один раз за время рантайма, но стоит ли оно того, если в коде каждая из этих переменных запрашивается всего пару раз?
- Не позволяйте себе оптимизировать, если у вас нет unit-тестов. Помните, что каждый шаг оптимизации вы должны щедро покрывать имеющимися unit-тестами. Вы должны быть уверенными, что не навели беспорядка и случайно не поломали существующую логику. Unit-тесты нужны не для галочки, а для вашего же спокойствия.
- Пакуйте структуры компактно. Если вы всё же решили оптимизировать, то начните с безобидной с игры в Тетрис. Правило здесь одно, и оно простое: малые переменные — вперёд больших.
- Работайте с доменной логикой вашего приложения. Мощнейшим инструментом оптимизации является умелая работа с доменной логикой. Знайте особенности работы, специфику своего приложения — пробуйте учитывать их, ищите свои «персональные» решения.
- RAM vs. CPU. Старайтесь изо всех сил соблюдать баланс использования ресурсов памяти и процессора. Это всегда представляет большую сложность, однако найти некий оптимум в каждом конкретном случае всё же возможно.
Если вам понравился этот доклад с конференции Mobius — обратите внимание, что 8-9 декабре пройдёт Mobius 2018 Moscow, где тоже будет много интересного. С 1 ноября цены билетов возрастают, так что есть смысл принять решение сейчас!
