
Как-то, решая проблему лингвистического анализа в Power BI и заодно подыскивая примеры для моей предыдущей статьи, я вспомнил о задаче, которую пытался решить в Excel ещё несколько лет назад: нужно было внедрить в аналитическую систему словарь русского языка для лингвистического анализа большого количества запросов на естественном языке. Причём желательно было использовать стандартные офисные инструменты. Подавляющее большинство людей сразу взялись бы решать эту задачу в Excel, и я когда-то пошёл по тому же пути. В качестве словаря использовал открытый корпус русского языка (http://opencorpora.org/).
Но меня ждало разочарование — словарь состоял из 300 тыс. словоформ, более 5 млн записей, а для Excel это в принципе невозможный объём. Даже если запихнуть в него «всего лишь» 1 млн строк, то выполнять с ними какие-то манипуляции или, упаси боже, вычисления, сможет только очень терпеливый человек, который вообще никогда и никуда не торопится. Но в этот раз я решил натравить на задачу более подходящий инструмент — Power BI.
Что собой представляет Power BI?
Я считаю этот продукт во многом недооценённым профессиональным сообществом. Power BI — это набор инструментов бизнес-анализа, который создавался для пользователей, владеющих Excel на чуть более высоком уровне, чем «подбить сумму по колонкам». Если человек способен написать в Excel формулы средней сложности, то освоит Power BI за пару вечеров.
Это не единый продукт с какой-то внутренней программистской логикой, а система из трёх компонентов:

- Power Query. Это ETL, в котором для написания запросов используется свой полноценный функциональный язык программирования — М. Справедливости ради надо отметить, что, скорее всего, программировать на нём обычному пользователю вряд ли придётся: большинство функций доступно прямо через меню или визард в интерфейсе компонента. Язык M совершенно не похож на язык запросов DAX (PowerPivot). Тем не менее, Microsoft собрал их вместе. В этом есть определенный смысл с точки зрения разработки: ETL заточен под получение и первоначальное насыщение данных (небыстро), а DAX — под вычисления, которые помогают нам эти данные визуализировать (быстро). То есть DAX предназначен для фронтенда, а Power Query для бэкенда, для процесса извлечения и форматирования данных.
- PowerPivot. Модуль in-memory-обработки, в основе которого лежит движок xVelocity. Использует язык запросов DAX, очень похожий на язык формул Excel.
- Компонент визуализации. Очень полезен для применения в системах, где нужно визуализировать данные: на сайте компании, или портале техподдержки (например, облако запросов), или на внутреннем корпоративном ресурсе. Есть инструменты, позволяющие сделать это и без Power BI, но многие из них не помогут, когда количество записей исчисляется миллионами и данные нужно как-то агрегировать. А с остальными инструментами подобного рода Power BI конкурирует благодаря своей простоте и дешевизне in-memory-обработки. Понятно, что, если речь пойдёт о терабайтах данных, тут нужен будет другой подход. И для таких случаев у Microsoft уже есть что предложить, но это тема для отдельной статьи.
Кривая обучения на первом этапе очень резко возрастает: если вы неплохо владеете Excel, то 80 % возможностей Power BI раскроются вам после короткого изучения. Это очень мощный инструмент, довольно лёгкий в использовании, но — до определённого момента. Чтобы задействовать его на полную мощность, вам уже потребуются опыт и глубокое знание языков М и DAX.
Для чего нужен Power BI Desktop?
Кому он может быть полезен? В первую очередь, любым бизнес-пользователям, которым приходится обрабатывать и анализировать довольно крупные объёмы данных, когда Excel уже не справляется или пыхтит на пределе возможностей. Подчеркну — Power BI Desktop предназначен для широкого круга пользователей, решающих очень разнообразный спектр задач. К примеру, в моём случае речь шла о нормализации 5 млн текстовых записей для последующего определения частотности ключевых слов.
Это востребовано при обработке анкет, запросов поисковых систем, рекламных объявлений, диктантов/сочинений, каких-то статистических массивов и т. д. Или для разгадывания кроссвордов…
Ещё один кейс и вариант реализации рассмотрен в статье о «распознавателе» Дмитрия Тумайкина. Реализовано на классическом Excel, но с использованием макросов…
Другой популярный сценарий подобного применения Power BI — вычисление соотношения показателей за текущий и предыдущий период. Например, у нас есть предагрегированные данные по выручке, и нужно сравнить её по дням с предыдущим кварталом, или годом, или аналогичным периодом. Причём хочется/требуется вставить результат сравнения в соседнюю колонку в виде значений, а не формул. Казалось бы, для Excel простейшая задача, написать простую формулу сравнения и протянуть по всем ячейкам колонки. Но только не в том случае, если у вас несколько миллионов строк в таблице. В самом DAX эта задача решается даже проще, чем в Excel, но тоже только с помощью поствычислений.
Можно привести ещё множество других практических сценариев применения Power BI, но суть вы, я думаю, уже поняли. Конечно, все эти задачи не проблема для программиста, владеющего, например, Python или R, но таких специалистов априори на порядки меньше, чем знатоков Excel. Вот только у Excel возможности ограничены, чего не скажешь о Power BI, который использует формульный язык DAX, очень похожий на формульный язык Excel, и способен налету обрабатывать миллионы и десятки миллионов записей. А дальше уже нужно наращивать оперативную память (хоть до 100, хоть до 300 Гб).
Помогаем техподдержке обрабатывать запросы
Но вернёмся к моей задаче. Нужно было придумать, как нулевой линии техподдержки автоматически оценивать тематику обращений пользователей. Для начала я решил вычленять определенные словоформы и по частоте их появления в обращениях определять самые важные темы, которые пользователи поднимают чаще всего.
Исходный словарь — это простой текстовый файл, который имеет регулярную структуру и выглядит так:
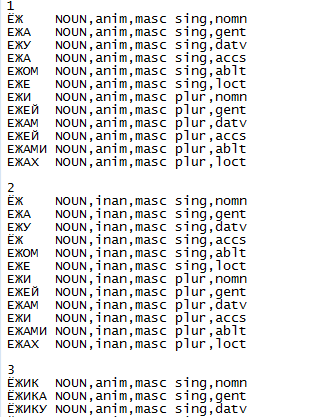
Для статистических целей нужно было для каждой словоформы определить начальную форму: для существительных — единственное число именительного падежа, для глаголов — неопределённую форму и т.д. Для программистов эта задача была проще простого: для каждого слова в левой колонке найти соответствие той форме, которая стоит сразу за номером этого слова в словаре.
Вот только среднестатистический бизнес-пользователь, не владеющий Python, специализированными инструментами и навыками разработки, не сможет решить эту задачу без использования self-analytics BI или подобного user-friendly инструментария. Причём, если данные нужно обработать для своих внутренних нужд или в них нет конфиденциальной информации, требующей защиты, то Power BI в этом случае будет ещё и бесплатен*.
Скрытый текст
*) Здесь имеется в виду версия Power BI Desktop и версия Power BI Services для персонального использования по тарифу Free.
Чтобы проанализировать данные, мне нужно было в Power Query, в таблице из 5 млн записей, добавить новый столбец, смещённый на одну позицию. Сначала я попытался применить ставший классическим подход с использованием Power Query, который описан на портале сообщества Power BI Марселем Бюгом (Marcel Beug), автором оригинального интерактивного справочника по Power Query (написанного тоже на Power Query). В статье предлагается два разных алгоритма: один навеян идеями Мэтта Элингтона —известного гуру и тренера по Power BI, а второй подход — оригинальная идея самого Марселя, с использованием дополнительной функции. Несмотря на то, что для увеличения производительности я полностью кэшировал исходные данные, оба подхода потребовали гигантского количества времени — уже пошли восьмые сутки, а процесс так и не завершился. Размер исходного файла был 270 Мб, а текущий размер обработанных данных подобрался к 17 Тб. Уверен, немногие пользователи Power BI видели такие числа в окне загрузки данных из файлового источника.
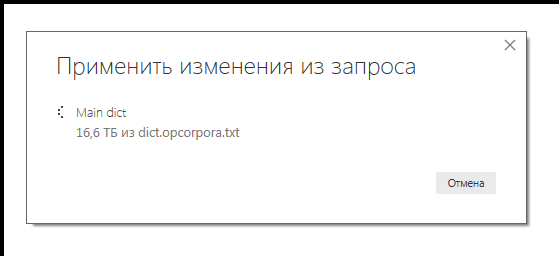
Почему так раздулся объём, непонятно; даже декартово произведение всех записей получается сильно меньше 16 Тб. Здесь внутренний оптимизатор оказался явно не на высоте. А, например, DAX-Studio не позволяет трейсить запросы Power Query, только DAX. Может быть, кто-то поделится своим опытом траблшутинга PQ?
Не дожидаясь завершения первого процесса, я решил на другой машине попробовать решить задачу с помощью DAX посредством самописного запроса. Запрос выполнился… примерно за 180 секунд, а потребление памяти возросло незначительно.

Исходный код запроса на DAX:
KeyWord =
CALCULATE(
TOPN(1;
CALCULATETABLE(
VALUES(ShiftedList[Word])
;ALLEXCEPT(ShiftedList;ShiftedList[Word Nr])
)
)//TOPN
)//CALCULATE
Т. е. для каждой строки в новом столбце [KeyWord] ищется самое первое значение столбца [Word], содержащего все варианты словоформ, имеющее такой же номер базовой словоформы (столбец [Word Nr]). Пока формат исходного файла будет оставаться неизменным, запрос должен отрабатывать без ошибок и на всех последующих релизах словаря.
Код запроса в Power Query, формирующего исходную таблицу в требуемом формате, был сформирован «на автомате» и выполнился менее чем за минуту:

После того, как за три минуты в PowerPivot-интерфейсе сформировался столбец ключевых слов, поиск любых словоформ в интерфейсе Power BI занимает не более 4 секунд. Причём контрольный поиск тех же данных в любимом Notepad++ x64 мог занимать и 20 секунд, и даже больше. Но это не камень в огород NPP — искать по всему массиву данных труднее (и дольше), чем по уже размеченным данным.
К слову сказать, приведённый выше DAX-запрос родился не с первого раза, и промежуточные варианты выедали всю доступную память, работали долго и завершались либо ошибкой данных, либо нерелевантным результатом.

В итоге размер сохранённого PBIX-файла стал меньше исходного текстового словаря на 60 % (112 Мб), но более чем в 4 раза превысил размер ZIP-архива с тем же самым словарём.
Возвращаясь к баттлу между Power Query и DAX: разница в длительности выполнения одной и той же операции в разных компонентах говорит о том, что Power BI — не лом, против которого нет приёма. У него свой характер и особенности применения, которые нужно учитывать в своей работе. Собственно, как и у любого инструмента. А к рекомендациям даже признанных гуру следует относиться с осторожностью.
Кажется, нобелевский лауреат Ричард Смолли говаривал, перефразируя первый закон Кларка: «Когда специалисты утверждают, что что-то осуществимо, то, вероятно, они правы (только не знают когда). Когда же они говорят, что это невозможно, то, скорее всего, они ошибаются».
Характеристики тестовой машины:
Процессор: Intel Core i7 4770@ 3,4 ГГц (4 ядра)
RAM: 16 ГБ
ОС: Windows 7 Корпоративная SP1 x64
Готовый словарь в формате Power BI можно скачать отсюда.
А здесь доступна доработанная онлайн-версия словаря. Можете порешать с его помощью кроссворды на досуге :)

…Кстати, тогда, несколько лет назад, задача всё-таки была решена в Excel, хоть и не на 100 %. Просто для анализа текстов был использован не весь корпус русского языка, а частотный словарь. Для базовой очистки текста вполне подойдёт любой из top100 имеющихся здесь частотных списков на несколько десятков килобайт.
Юрий Колмаков, эксперт Департамента систем консолидации и визуализации данных компании «Инфосистемы Джет» (McCow)
Only registered users can participate in poll. Log in, please.
Любопытства ради, небольшой опрос: какой максимальный размер данных (по количеству записей) вам удалось обработать на Power BI?
16.67% 1) До 1 млн7
2.38% 2) До 5 млн1
4.76% 3) До 10 млн2
7.14% 4) До 50 млн3
7.14% 5) Больше 50 млн3
9.52% 6) Использую другой BI in-memory4
52.38% 7) Вообще не использую ПО подобного класса22
42 users voted. 31 users abstained.
