
Прим. перев.: В этой статье, написанной техническим консультантом и сертифицированным администратором Kubernetes из Великобритании — Daniele Polencic, — наглядно показывается и рассказывается о том, какую роль играет kube-proxy в доставке пользовательских запросов до подов и что происходит, когда на одном из узлов кластера возникают проблемы.
Код приложений, развёрнутых в Kubernetes, запускается на одном или более рабочих узлов. Узел может располагаться как на физической или виртуальной машине, так и в AWS EC2 или Google Compute Engine, а наличие множества таких площадок означает возможность эффективного запуска и масштабирования приложения. Например, если кластер состоит из трёх узлов и вы решаете отмасштабировать приложение на четыре реплики, Kubernetes равномерно распределит их среди узлов следующим образом:
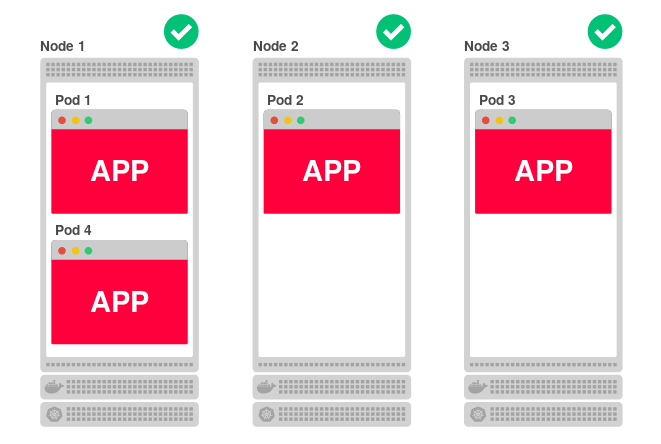
Такая архитектура хорошо справляется и с падениями. Если один узел окажется недоступным, приложение продолжит работать на двух других. А в это время Kubernetes переназначит четвёртую реплику на другой (доступный) узел.

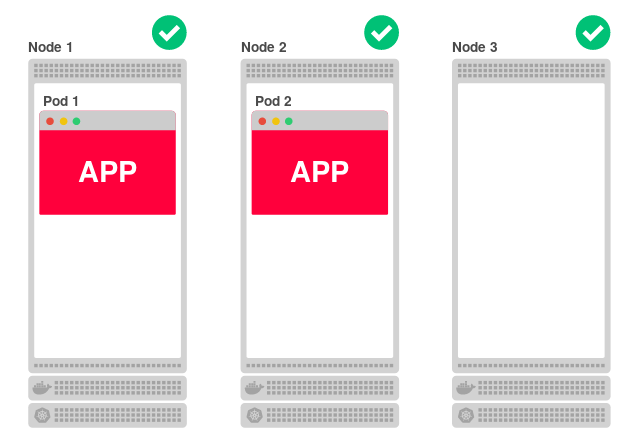
Более того, даже если все узлы окажутся изолированными, они всё равно смогут обслуживать запросы. Например, уменьшим число реплик приложения до двух:
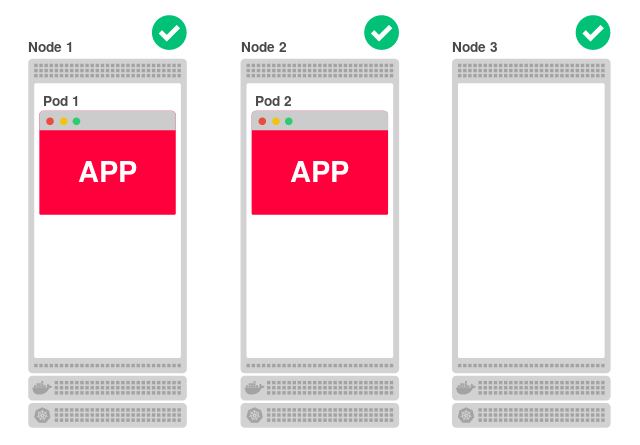
Поскольку каждый узел может обслуживать приложение, как же третий (Node 3) узнает, что на нём не запущено приложение и ему следует перенаправить трафик на один из других узлов?

У Kubernetes есть бинарник
Но откуда
Он не знает.
А вот знает обо всём главный (master) узел, который отвечает за создание списка всех правил маршрутизации. А
Совершенно не важно, с какого узла приходит трафик:
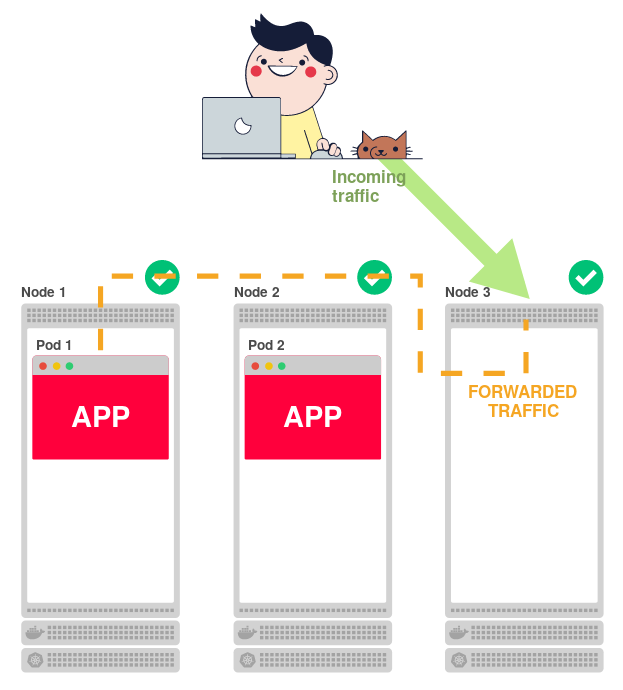
У Manabu Sakai были такие же вопросы. И он решил разобраться.
Предположим, у вас кластер из двух узлов в GCP:
И вы разворачиваете приложение Manabu:
Это простое приложение, которое выводит на веб-странице имя хоста текущего пода.

Масштабируем его (Deployment) до десяти реплик:
Десять реплик равномерно распределяются по двум узлам (node1 и node2):

Создаётся Service для балансировки нагрузки от запросов по десяти репликам:
Во внешний мир он пробрасывается через

За настройку правил по направлению входящего трафика с порта 30000 до одного из десяти подов отвечает
Попробуйте отправить запрос на порт 30000 одного из узлов:
Примечание: IP-адрес узла можно получить командой
Приложение отвечает «Hello world!» и именем хоста контейнера, на котором оно запущено:
Если повторно запрашивать тот же URL, иногда будет появляться такой же ответ, а иногда он будет меняться. Причина —
Что интересно, совершенно всё равно, к какому узлу вы обращаетесь: ответ будет приходить с любого пода — даже с тех, которые размещены на других узлах (не тех, к которым вы обратились).
Для окончательной конфигурации потребуется задействовать внешний балансировщик нагрузки, который распределит трафик по узлам (на порт 30000). Так и получается финальная схема прохождения запросов:

То есть балансировщик нагрузки перенаправляет входящий трафик из интернета на один из двух узлов. Внесём ясность во всю эту схему — резюмируем принцип её работы:
Вот и вся схема!
Теперь, когда мы знаем, как всё взаимодействует, давайте вернёмся к изначальному вопросу. Что случится, если мы изменим правила маршрутизации? Будет ли по-прежнему работать кластер? Будут ли поды обслуживать запросы?
Давайте удалять правила маршрутизации, а в отдельном терминале — мониторить приложение на время ответов и пропущенные запросы. Для последнего достаточно написать цикл, который будет каждую секунду выводить текущее время и делать запрос к приложению:
На выходе мы получим столбцы со временем и текстом ответа от пода:
Итак, давайте удалять правила маршрутизации с узла, но сначала разберёмся, как это делать.
В режиме iptables
Примечание: Учтите, что вызов
Если всё прошло по плану, вы увидите нечто подобное:
Как легко заметить, с момента сбрасывания правил iptables до следующего ответа потребовалось около 27 секунд (с 10:14:43 до 10:15:10).
Что произошло за это время? Почему всё снова стало хорошо после 27 секунд? Может быть, это просто совпадение?
Давайте сбросим правила ещё раз:
Теперь видна пауза в 29 секунд, с 11:29:56 до 11:30:25. Но кластер снова вернулся к работе.
Почему для ответа требуется 30 секунд? На узел приходят запросы даже без таблицы маршрутизации?
Можно посмотреть на то, что происходит на узле на протяжении этих 30 секунд. В другом терминале запустите цикл, который делает запросы к приложению каждую секунду, но на сей раз — обращайтесь к узлу, а не балансировщику нагрузки.
И снова сбросьте правила iptables. Получится такой лог:
Неудивительно, что подключения к узлу заканчиваются таймаутом после сброса правил. Но интересно, что
А что, если в предыдущем примере балансировщик нагрузки ждёт новых подключений? Это бы объяснило 30-секундную задержку, однако останется непонятным, почему узел готов принимать соединения после достаточно продолжительного ожидания.
Так почему же трафик снова идёт через 30 секунд? Кто восстанавливает правила iptables?
Перед тем, как сбрасывать правила iptables, можно их посмотреть:
Сбросьте правила и продолжайте выполнять эту команду — вы увидите, что правила восстанавливаются за несколько секунд.
Это ты,
То есть:
Вот почему около 30 секунд ушло на то, чтобы узел снова заработал! Это также объясняет, как таблицы маршрутизации попадают с главного (master) узла на рабочий (worker). Их регулярной синхронизацией занимается
Итак, резюмируем, как Kubernetes и
Ожидание 30 секунд может быть недопустимым для приложения. В таком случае стоит подумать об изменении стандартного интервала обновления в
На узле есть агент — kubelet, — и именно он отвечает за запуск
Если взглянуть на процесс kubelet, работающий на узле, можно увидеть, что он запущен с флагом
Что же содержится в этом
Примечание: В целях упрощения здесь приведено неполное содержимое файла.
Тайна разгадана! Как видно, для обновления правил iptables каждые 30 секунд используется опция
Сброс правил iptables равносилен тому, чтобы сделать узел недоступным. Трафик по-прежнему отправляется на узел, однако он не способен пробросить его дальше (т.е. на под). Kubernetes может восстанавливаться после такой проблемы с помощью отслеживания правил маршрутизации и их обновления при необходимости.
Большая благодарность Manabu Sakai за публикацию в блоге, которая во многом вдохновила на этот текст, а также Valentin Ouvrard за изучение вопроса пробрасывания правил iptables с мастера на другие узлы.
Читайте также в нашем блоге:
Код приложений, развёрнутых в Kubernetes, запускается на одном или более рабочих узлов. Узел может располагаться как на физической или виртуальной машине, так и в AWS EC2 или Google Compute Engine, а наличие множества таких площадок означает возможность эффективного запуска и масштабирования приложения. Например, если кластер состоит из трёх узлов и вы решаете отмасштабировать приложение на четыре реплики, Kubernetes равномерно распределит их среди узлов следующим образом:
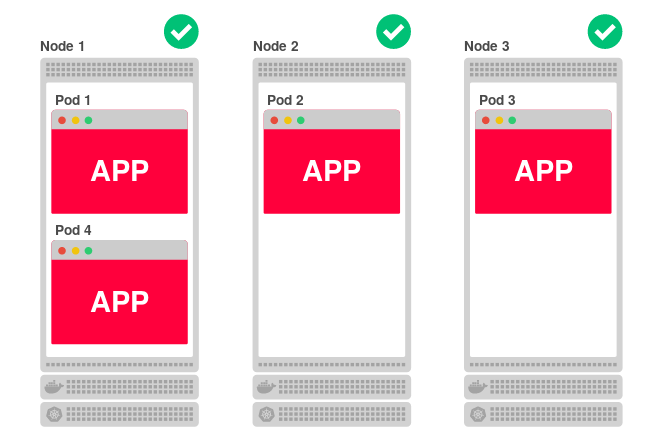
Такая архитектура хорошо справляется и с падениями. Если один узел окажется недоступным, приложение продолжит работать на двух других. А в это время Kubernetes переназначит четвёртую реплику на другой (доступный) узел.
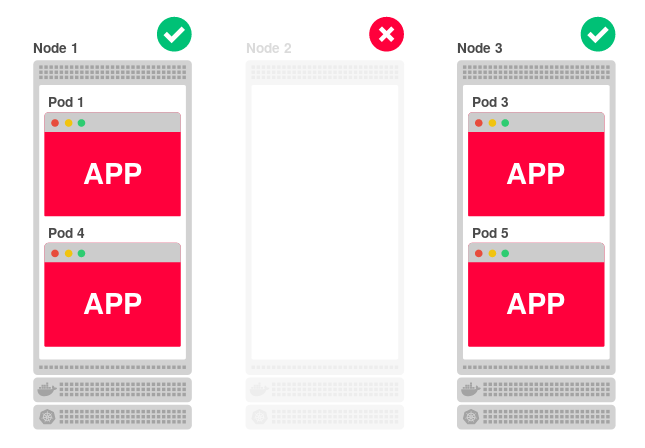
Более того, даже если все узлы окажутся изолированными, они всё равно смогут обслуживать запросы. Например, уменьшим число реплик приложения до двух:
Поскольку каждый узел может обслуживать приложение, как же третий (Node 3) узнает, что на нём не запущено приложение и ему следует перенаправить трафик на один из других узлов?

У Kubernetes есть бинарник
kube-proxy, запускаемый на каждом узле и ответственный за маршрутизацию трафика на конкретный под. Его можно сравнить с администратором отеля, сидящим за стойкой регистрации. Kube-proxy принимает весь трафик, приходящий на узел, и пересылает на правильный под.Но откуда kube-proxy знает, где расположены все поды?
Он не знает.
А вот знает обо всём главный (master) узел, который отвечает за создание списка всех правил маршрутизации. А
kube-proxy проверяет эти правила и приводит их в действие. В простом сценарии, описанном выше, список правил сводится к следующему:- Первая реплика приложения доступна на узле 1 (Node 1).
- Вторая реплика приложения доступна на узле 2 (Node 2).
Совершенно не важно, с какого узла приходит трафик:
kube-proxy знает, куда необходимо перенаправить трафик в соответствии с этим списком правил.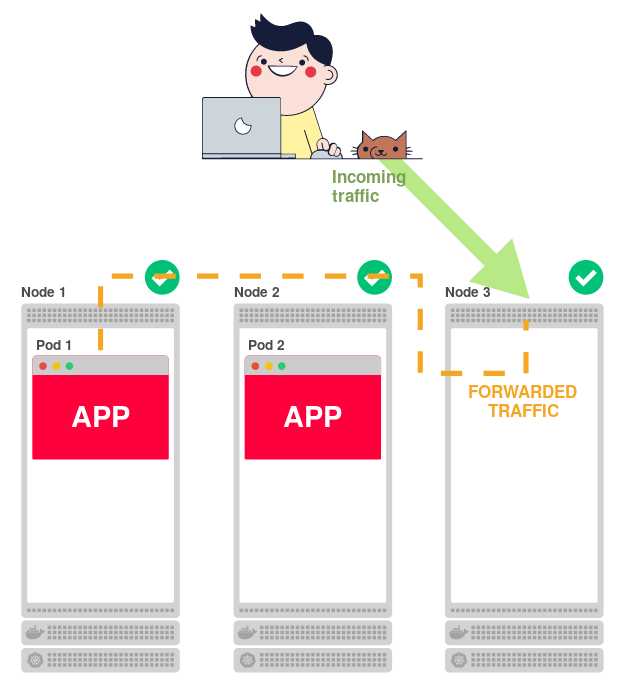
Но что происходит, когда kube-proxy падает?
И что, если список правил пропадёт?
Что происходит, когда нет правил, куда направлять трафик?
У Manabu Sakai были такие же вопросы. И он решил разобраться.
Предположим, у вас кластер из двух узлов в GCP:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready <none> 17h v1.8.8-gke.0
node2 Ready <none> 18h v1.8.8-gke.0И вы разворачиваете приложение Manabu:
$ kubectl create -f https://raw.githubusercontent.com/manabusakai/k8s-hello-world/master/kubernetes/deployment.yml
$ kubectl create -f https://raw.githubusercontent.com/manabusakai/k8s-hello-world/master/kubernetes/service.ymlЭто простое приложение, которое выводит на веб-странице имя хоста текущего пода.
Масштабируем его (Deployment) до десяти реплик:
$ kubectl scale --replicas 10 deployment/k8s-hello-worldДесять реплик равномерно распределяются по двум узлам (node1 и node2):
$ kubectl get pods
NAME READY STATUS NODE
k8s-hello-world-55f48f8c94-7shq5 1/1 Running node1
k8s-hello-world-55f48f8c94-9w5tj 1/1 Running node1
k8s-hello-world-55f48f8c94-cdc64 1/1 Running node2
k8s-hello-world-55f48f8c94-lkdvj 1/1 Running node2
k8s-hello-world-55f48f8c94-npkn6 1/1 Running node1
k8s-hello-world-55f48f8c94-ppsqk 1/1 Running node2
k8s-hello-world-55f48f8c94-sc9pf 1/1 Running node1
k8s-hello-world-55f48f8c94-tjg4n 1/1 Running node2
k8s-hello-world-55f48f8c94-vrkr9 1/1 Running node1
k8s-hello-world-55f48f8c94-xzvlc 1/1 Running node2
Создаётся Service для балансировки нагрузки от запросов по десяти репликам:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
k8s-hello-world NodePort 100.69.211.31 <none> 8080:30000/TCP 3h
kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 18hВо внешний мир он пробрасывается через
NodePort и доступен по порту 30000. Другими словами, у каждого узла открывается порт 30000 для внешнего интернета и начинает принимать входящий трафик.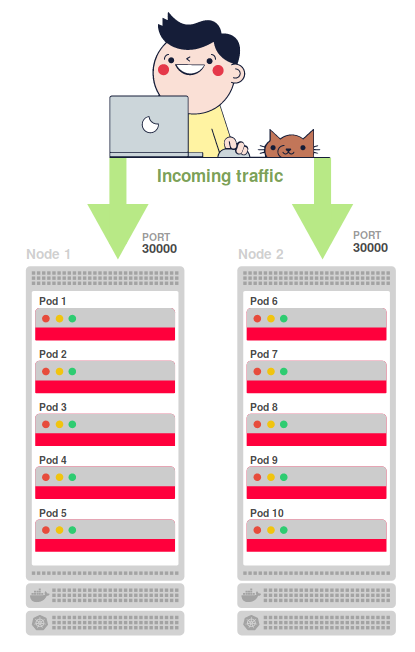
Но как трафик маршрутизируется с порта 30000 до пода?
За настройку правил по направлению входящего трафика с порта 30000 до одного из десяти подов отвечает
kube-proxy.Попробуйте отправить запрос на порт 30000 одного из узлов:
$ curl <node ip>:30000Примечание: IP-адрес узла можно получить командой
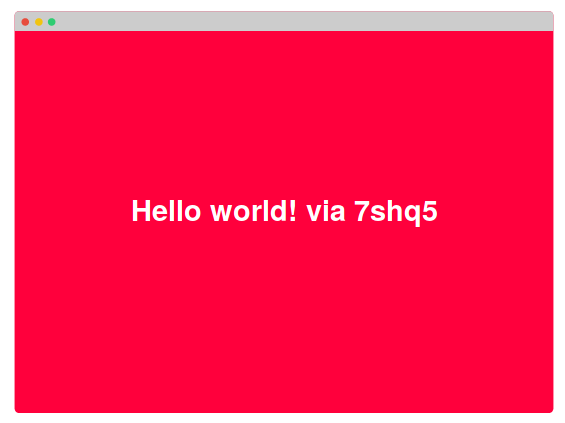
kubectl get nodes -o wide.Приложение отвечает «Hello world!» и именем хоста контейнера, на котором оно запущено:
Hello world! via <hostname>.Если повторно запрашивать тот же URL, иногда будет появляться такой же ответ, а иногда он будет меняться. Причина —
kube-proxy работает как балансировщик нагрузки, проверяет маршрутизацию и распределяет трафик по десяти подам.Что интересно, совершенно всё равно, к какому узлу вы обращаетесь: ответ будет приходить с любого пода — даже с тех, которые размещены на других узлах (не тех, к которым вы обратились).
Для окончательной конфигурации потребуется задействовать внешний балансировщик нагрузки, который распределит трафик по узлам (на порт 30000). Так и получается финальная схема прохождения запросов:
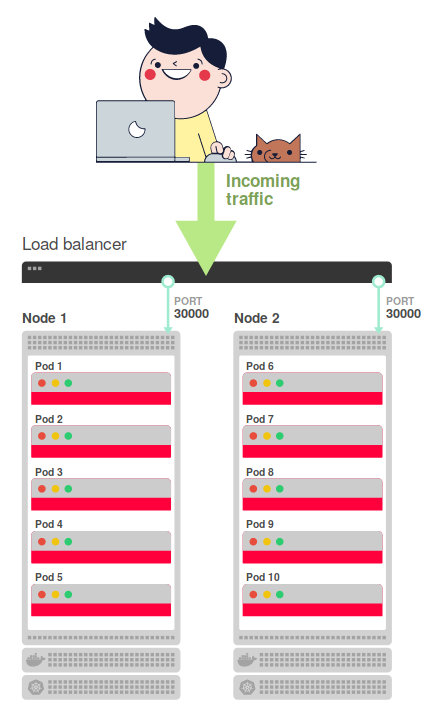
То есть балансировщик нагрузки перенаправляет входящий трафик из интернета на один из двух узлов. Внесём ясность во всю эту схему — резюмируем принцип её работы:
- Приходящий из интернета трафик направляется на основной балансировщик нагрузки.
- Этот балансировщик направляет трафик на порт 30000 одного из двух узлов.
- Правила, установленные
kube-proxy, перенаправляют трафик с узла на под. - Трафик попадает на под.
Вот и вся схема!
Настало время всё сломать
Теперь, когда мы знаем, как всё взаимодействует, давайте вернёмся к изначальному вопросу. Что случится, если мы изменим правила маршрутизации? Будет ли по-прежнему работать кластер? Будут ли поды обслуживать запросы?
Давайте удалять правила маршрутизации, а в отдельном терминале — мониторить приложение на время ответов и пропущенные запросы. Для последнего достаточно написать цикл, который будет каждую секунду выводить текущее время и делать запрос к приложению:
$ while sleep 1; do date +%X; curl -sS http://<your load balancer ip>/ | grep ^Hello; doneНа выходе мы получим столбцы со временем и текстом ответа от пода:
10:14:41 Hello world! via k8s-hello-world-55f48f8c94-vrkr9
10:14:43 Hello world! via k8s-hello-world-55f48f8c94-tjg4nИтак, давайте удалять правила маршрутизации с узла, но сначала разберёмся, как это делать.
kube-proxy может работать в трёх режимах: userspace, iptables и ipvs. Режимом по умолчанию со времён Kubernetes 1.2 является iptables. (Прим. перев.: Последний режим, ipvs, появился в релизе K8s 1.8 и получил статус бета-версии в 1.9.)В режиме iptables
kube-proxy составляет список правил маршрутизации на узле с помощью правил iptables. Таким образом, можно зайти на любой узел и удалить эти правила командой iptables -F.Примечание: Учтите, что вызов
iptables -F может оборвать SSH-подключение.Если всё прошло по плану, вы увидите нечто подобное:
10:14:41 Hello world! via k8s-hello-world-55f48f8c94-xzvlc
10:14:43 Hello world! via k8s-hello-world-55f48f8c94-tjg4n
# в этот момент выполнена команда `iptables -F`
10:15:10 Hello world! via k8s-hello-world-55f48f8c94-vrkr9
10:15:11 Hello world! via k8s-hello-world-55f48f8c94-vrkr9Как легко заметить, с момента сбрасывания правил iptables до следующего ответа потребовалось около 27 секунд (с 10:14:43 до 10:15:10).
Что произошло за это время? Почему всё снова стало хорошо после 27 секунд? Может быть, это просто совпадение?
Давайте сбросим правила ещё раз:
11:29:55 Hello world! via k8s-hello-world-55f48f8c94-xzvlc
11:29:56 Hello world! via k8s-hello-world-55f48f8c94-tjg4n
# в этот момент выполнена команда `iptables -F`
11:30:25 Hello world! via k8s-hello-world-55f48f8c94-npkn6
11:30:27 Hello world! via k8s-hello-world-55f48f8c94-vrkr9Теперь видна пауза в 29 секунд, с 11:29:56 до 11:30:25. Но кластер снова вернулся к работе.
Почему для ответа требуется 30 секунд? На узел приходят запросы даже без таблицы маршрутизации?
Можно посмотреть на то, что происходит на узле на протяжении этих 30 секунд. В другом терминале запустите цикл, который делает запросы к приложению каждую секунду, но на сей раз — обращайтесь к узлу, а не балансировщику нагрузки.
$ while sleep 1; printf %"s\n" $(curl -sS http://<ip of the node>:30000); doneИ снова сбросьте правила iptables. Получится такой лог:
Hello world! via k8s-hello-world-55f48f8c94-xzvlc
Hello world! via k8s-hello-world-55f48f8c94-tjg4n
# в этот момент выполнена команда `iptables -F`
curl: (28) Connection timed out after 10003 milliseconds
curl: (28) Connection timed out after 10004 milliseconds
Hello world! via k8s-hello-world-55f48f8c94-npkn6
Hello world! via k8s-hello-world-55f48f8c94-vrkr9Неудивительно, что подключения к узлу заканчиваются таймаутом после сброса правил. Но интересно, что
curl ждёт ответа по 10 секунд.А что, если в предыдущем примере балансировщик нагрузки ждёт новых подключений? Это бы объяснило 30-секундную задержку, однако останется непонятным, почему узел готов принимать соединения после достаточно продолжительного ожидания.
Так почему же трафик снова идёт через 30 секунд? Кто восстанавливает правила iptables?
Перед тем, как сбрасывать правила iptables, можно их посмотреть:
$ iptables -LСбросьте правила и продолжайте выполнять эту команду — вы увидите, что правила восстанавливаются за несколько секунд.
Это ты,
kube-proxy? Да! В официальной документации kube-proxy можно найти два интересных флага:-
--iptables-sync-period— максимальный интервал, за который правила iptables будут обновлены (например: ‘5s’, ‘1m’, ‘2h22m’). Должен быть больше 0. По умолчанию — 30s; -
--iptables-min-sync-period— минимальный интервал, за который правила iptables должны быть обновлены, когда происходят изменения в endpoints и services (например: ‘5s’, ‘1m’, ‘2h22m’). По умолчанию — 10s.
То есть:
kube-proxy обновляет правила iptables каждые 10—30 секунд. Если мы сбросим правила iptables, для kube-proxy потребуется до 30 секунд, чтобы осознать это и восстановить их.Вот почему около 30 секунд ушло на то, чтобы узел снова заработал! Это также объясняет, как таблицы маршрутизации попадают с главного (master) узла на рабочий (worker). Их регулярной синхронизацией занимается
kube-proxy. Другими словами, каждый раз при добавлении или удалении пода главный узел переделывает список маршрутов, а kube-proxy регулярно синхронизирует правила с текущим узлом.Итак, резюмируем, как Kubernetes и
kube-proxy восстанавливаются, если кто-то испортил правила iptables на узле:- Правила iptables были удалены с узла.
- Запрос направляется балансировщику нагрузки и маршрутизируется на узел.
- Узел не принимает входящие запросы, поэтому балансировщик ждёт.
- Через 30 секунд
kube-proxyвосстанавливает правила iptables. - Узел снова может принимать трафик. Правила iptables перенаправляют запрос балансировщика на под.
- Под отвечает балансировщику нагрузки с итоговой задержкой в 30 секунд.
Ожидание 30 секунд может быть недопустимым для приложения. В таком случае стоит подумать об изменении стандартного интервала обновления в
kube-proxy. Где эти настройки и как их изменить?На узле есть агент — kubelet, — и именно он отвечает за запуск
kube-proxy как статичного пода на каждом узле. Документация по статичным подам предполагает, что kubelet проверяет содержимое определённого каталога и создаёт все ресурсы из него.Если взглянуть на процесс kubelet, работающий на узле, можно увидеть, что он запущен с флагом
--pod-manifest-path=/etc/kubernetes/manifests. Элементарный ls приоткрывает завесу тайны:$ ls -l /etc/kubernetes/manifests
total 4 -rw-r--r-- 1 root root 1398 Feb 24 08:08 kube-proxy.manifestЧто же содержится в этом
kube-proxy.manifest?apiVersion: v1
kind: Pod
metadata:
name: kube-proxy
spec:
hostNetwork: true
containers:
- name: kube-proxy
image: gcr.io/google_containers/kube-proxy:v1.8.7-gke.1
command:
- /bin/sh
- -c
->
echo -998 > /proc/$$$/oom_score_adj &&
exec kube-proxy
--master=https://35.190.207.197
--kubeconfig=/var/lib/kube-proxy/kubeconfig
--cluster-cidr=10.4.0.0/14
--resource-container=""
--v=2
--feature-gates=ExperimentalCriticalPodAnnotation=true
--iptables-sync-period=30s
1>>/var/log/kube-proxy.log 2>&1Примечание: В целях упрощения здесь приведено неполное содержимое файла.
Тайна разгадана! Как видно, для обновления правил iptables каждые 30 секунд используется опция
--iptables-sync-period=30s. Здесь же можно изменить минимальное и максимальное время обновления правил на конкретном узле.Выводы
Сброс правил iptables равносилен тому, чтобы сделать узел недоступным. Трафик по-прежнему отправляется на узел, однако он не способен пробросить его дальше (т.е. на под). Kubernetes может восстанавливаться после такой проблемы с помощью отслеживания правил маршрутизации и их обновления при необходимости.
Большая благодарность Manabu Sakai за публикацию в блоге, которая во многом вдохновила на этот текст, а также Valentin Ouvrard за изучение вопроса пробрасывания правил iptables с мастера на другие узлы.
P.S. от переводчика
Читайте также в нашем блоге:
- «Иллюстрированное руководство по устройству сети в Kubernetes»;
- «Как обеспечивается высокая доступность в Kubernetes»;
- «Улучшая надёжность Kubernetes: как быстрее замечать, что нода упала»;
- «Что происходит в Kubernetes при запуске kubectl run?»: часть 1 и часть 2;
- «Как на самом деле работает планировщик Kubernetes?»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- « Container Networking Interface (CNI) — сетевой интерфейс и стандарт для Linux-контейнеров ».
