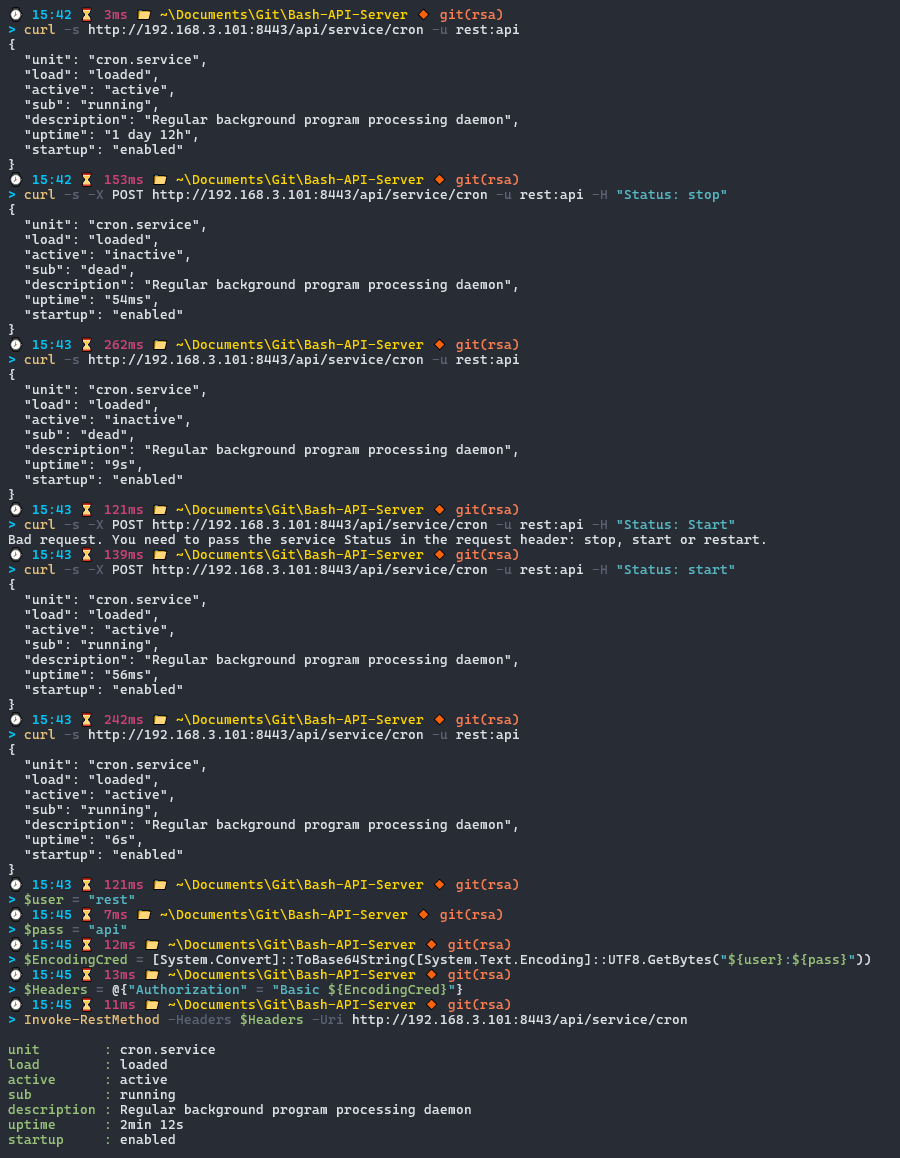
Всем привет! Ранее рассказывал о том, как создать REST API и Web-сервер на PowerShell для Windows, а также упоминал, что подобный сервер будет работать и в системе Linux, благодаря кроссплатформенной версии PowerShell Core. Безусловно, для подобных целей лучше используются специализированные серверные фреймворки или библиотеки, такие как Flask или Django в Python, но меня не покидала идея реализации похожего сервера, где описание логики будет производиться на языке одного только Bash. Приведу примеры, с помощью которых можно создать такой сервер используя сетевые сокеты netcat , socat и ncat, а также веб-сервера Apache с использованием встроенных модулей.